对抗训练通过添加扰动构建对抗样本,喂入模型一同训练,提高模型遇到对抗样本时的鲁棒性,同时一定程度也能提高模型的表现和泛化能力。
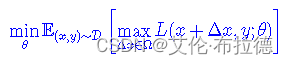
公式解读
其中D代表训练集,x代表输入,y代表标签,θ是模型参数,L(x,y;θ)是单个样本的loss,Δx是对抗扰动,Ω是扰动空间。下面来认真分析一下这个公式。

如何求出Δx
Δx的目标是增大L(x+Δ,y;θ),而我们知道让loss减少的方法是梯度下降,那反过来,让loss增大的方法自然就是梯度上升,因此可以简单地取:
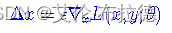
因此,用一句话形容对抗训练的思路,就是在输入上进行梯度上升(增大loss)使得输入尽可能跟原来不一样,在参数上进行梯度下降(减小loss)使得模型尽可能能够正确识别。
∇为梯度符号,因此可知,Δx的取值是和梯度相关的,ϵ为一常数。
为了防止Δx过大,通常要对∇xL(x,y;θ)做些标准化:

如何实现
在CV中我们可以通过在原图像中加入噪点,但是并不影响原图像的性质。
而在NLP领域,我们并不能直接的通过在词编码上添加噪点,因为词嵌入本质上就是one-hot,如果在one-hot上增加上述噪点,就会对原句产生歧义。因此,一个自然的想法就是在embedding上增加扰动。
Embedding层的输出是直接取自于Embedding参数矩阵的,因此我们可以直接对Embedding参数矩阵进行扰动。这样得到的对抗样本的多样性会少一些(因为不同样本的同一个token共用了相同的扰动),但仍然能起到正则化的作用,而且这样实现起来容易得多。
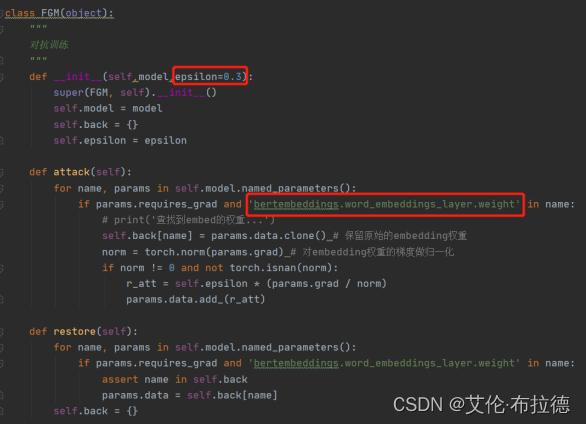
实现步骤
(1)一切照常,计算前向loss,然后反向传播计算grad(注意这里不要更新梯度,即没有optimizer.step())
(2)拿到embedding层的梯度,计算其norm,然后根据公式计算出r_adv,再将r_adv累加到原始embedding的样本上,即 x+r(也就是x+∆x) ,得到对抗样本;
(3)根据新对抗样本 x+r ,计算新loss,在backward()得到对抗样本的梯度。由于是在step(1)之后又做了一次反向传播,所以该对抗样本的梯度是累加在原始样本的梯度上的;
(4)将被修改的embedding恢复到原始状态(没加上r_adv 的时候);
(5)使用step(3)的梯度(原始梯度+对抗梯度),对模型参数进行更新。