此文之前先发一段鸡汤吧,至今我依然记着这么三段话:
1、 人类进步最大的动力是懒;
2、 能用机器完成的事情绝对不应该用人工来完成;
3、 让框架来适应业务,而不是业务适应框架。
1背景
之前完成了,让通用Mapper支持Join的功能,再查阅业务代码,另一个常出现的XML就是SUM,COUNT,MAX,MIN 的相关统计的功能。当然用其他方式也能实现统计,比如Spark,Flink等大数据实时计算框架,但是这在绝大部分中小公司来说性价比是非常低的,本文暂不讨论,实时数据的计算。
1.1 需要了解但是不介绍的部分
1、 Mybatis的使用;
2、 通用Mapper:Tk.Mybatis的使用;
3、 Tk.Mybatis支持Join操作
2、解开实现Group By的面纱
2.1 方案的选择
在决定做这个通用封装的时候,有两个方案浮现在面前:
1、 继续扩展EntityTable,参照上一篇的JoinEntityTable,同时在Resolve中进行解析:
优势:(1)整个思维相对比较通顺,同时仅仅是对原来业务是叠加,而不是改变
劣势:(1)会产生大量的实体,如果我既想SUM又想COUNT,不同业务,不同字段;(2)从调用者的思维角度上不够自然
2、 把GROUPBY放到Example里面,去扩展Example:
优势:(1)更加符合调用者的使用习惯,并且只需要产生一个Table实体
劣势:(1)MappedStatment无法解析到Select字段,因为Example是参数,而不是实体类,实现上更为负责;(2)需要对ResultMapper进行处理
从模块设计来说,我完全没有思考地选择了方案二。
2.2 从一个例子开始GroupBy
我们先看下面一段SQL:
Select name, suit, count(goods_extern.category) as countCategory where category>3 group name, suit;
上面这个例子,我们来看Java的调用,如图1
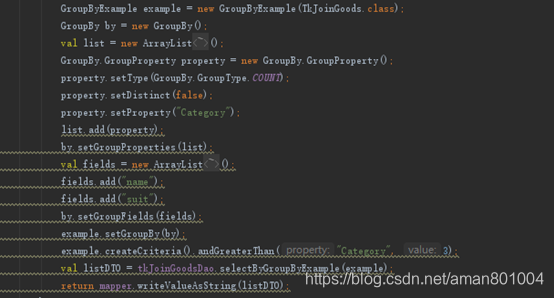
图1 带有GroupBy的Example调用
接着,我们来看GroupByExample的实现,这里有两点需要注意
(1) 非聚合字段必须GroupBy
(2) 必须使用动态参数来表示选择的字段
如图2,图3
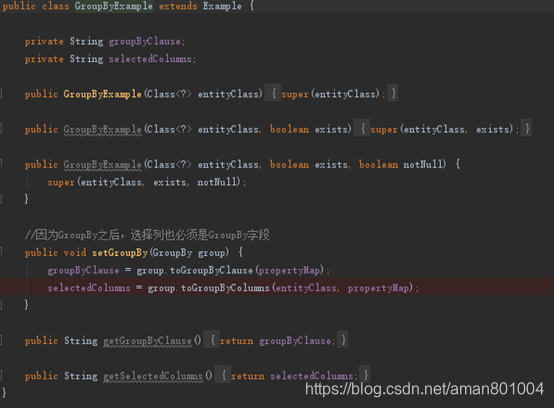
图2 GroupByExample的实现
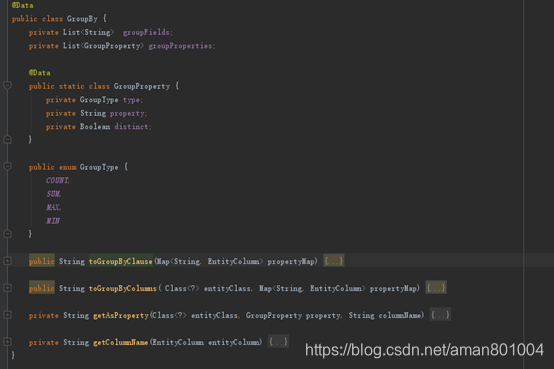
图3 GroupBy的组成与核心方法
这里,还有TkJoinGoods的实体实现,我们来看如图4
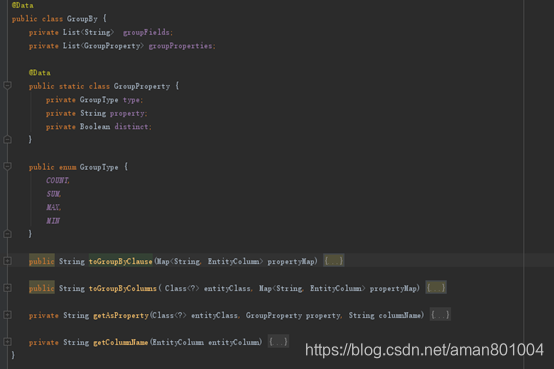
图4 实体类的定义
在这个实体类的定义中,除了之前介绍的Join注解外,还包含了GroupByColumn注解,这个是可以多定义但是不使用的。
2.3 Provider的定义
刚才我们说到,因为GroupBy是在Example中定义的,而且必须满足上面说的非聚合列和Group By的两个要求,于是我们定义了GroupSqlHelper,如图5所示
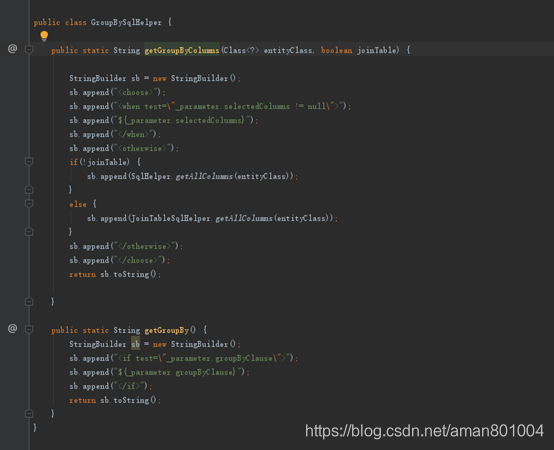
图5 定义选择的字段与Group by
从上图来看,都采用$参数的方式进行处理了。
那么Provider的方法就顺其自然产生了,如图6。
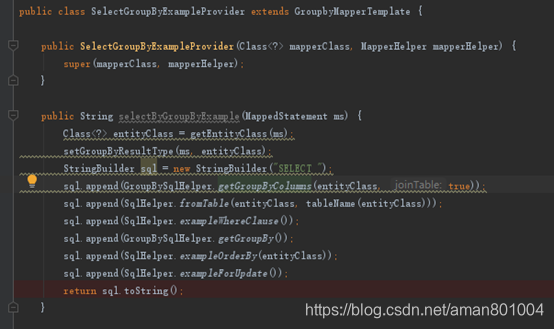
图6 Provider的GroupBy方法
这里,还有一个核心问题,就是设置GroupBy的MapperResult,我们看如图7
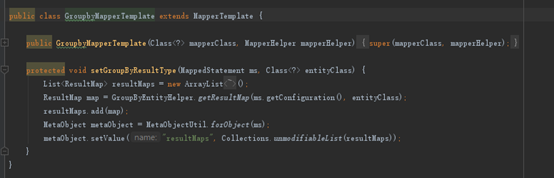
图7 设置ResultMapper
在获取ResultMapper中和Tk原有的方法比较只是增加了GroupByColumn的处理,如图8
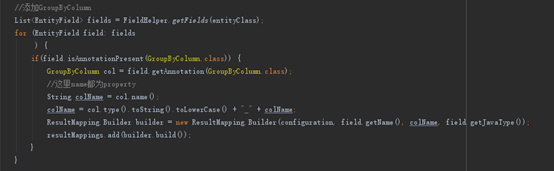
图8 处理GroupByColumn
到此,TkMapper的扩展结束,当然这远没到终点,接下来会继续完成CodeLess工程,连实体,Mapper和调用都不用编码,敬请期待。