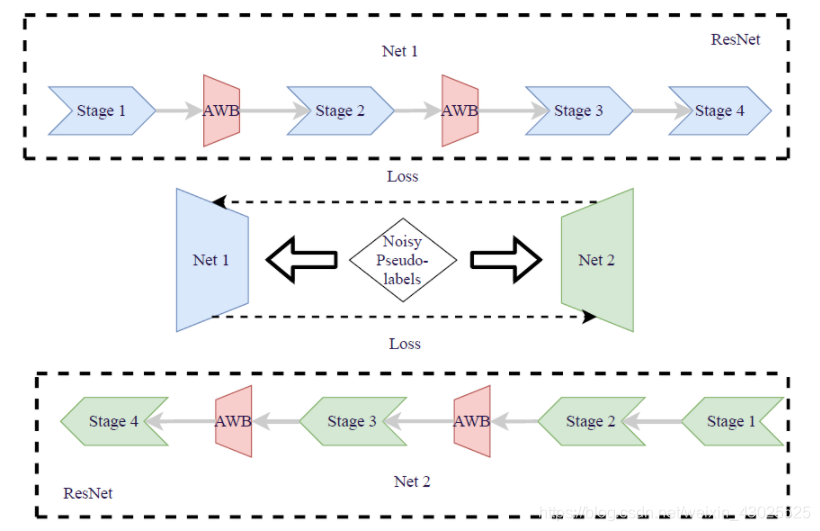
AWB(Attention WaveBlock)
文章目录
1 问题and方法
?:UDA:聚类算法产生的伪标签存在噪声->双流网络相互学习产生软标签(随着网络的逐渐收敛,互补性被削弱 两者偏向于同类噪声。
1、通过两个网络分别使用waving blocks产生差异
2、利用注意力机制扩大差异,发现更多互补特征
3、结合注意力机制和wb
2 MMT
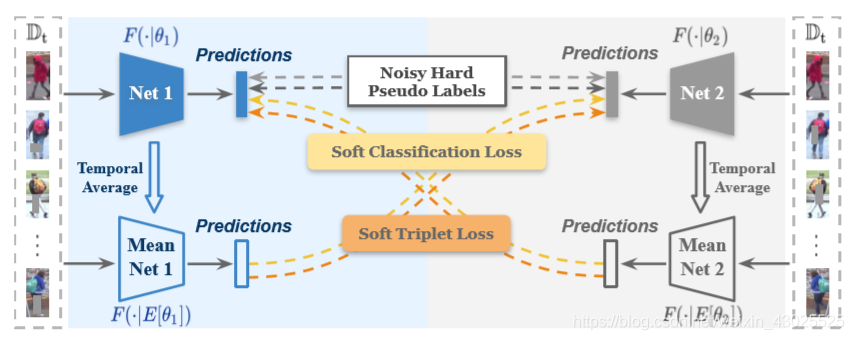
两个不同初始化的网络NET1与NET2,首先在源域上对两个网络进行预训练,得到初始化参数,在每个epoch使用聚类算法生成硬伪标签,在给定时期的每次迭代两个网络产生精细的软伪标签,然后由一个网络生成的硬伪标签和软伪标签一起用于监督另一个网络. “软”标签来自对方网络的”平均模型”,采用网络的”平均模型”Mean-Net 1/2而不是当前的网络本身Net 1/2进行相互监督
3 WaveBlock
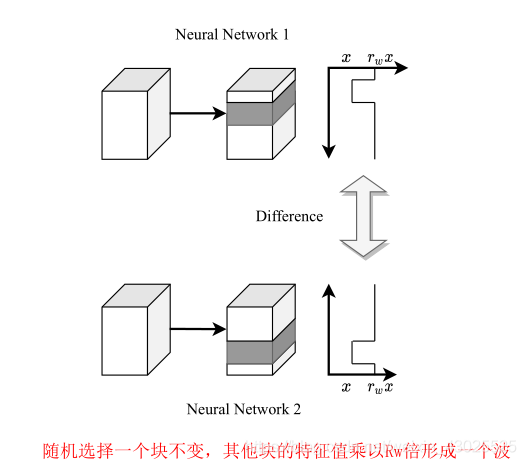
增强两个网络的互补性,用不同的波调制
4 attention WaveBlock
尽管WaveBlock能够使两个网络在特征地图的不同区域上工作,但从非歧视性区域(如背景)中学习到的一些特征可能仍然相似。通过将注意力模块与WaveBlock相结合,这两个网络将注意力集中在不同且有区别的区域,例如人体,因此可以学习更多不同的特征。
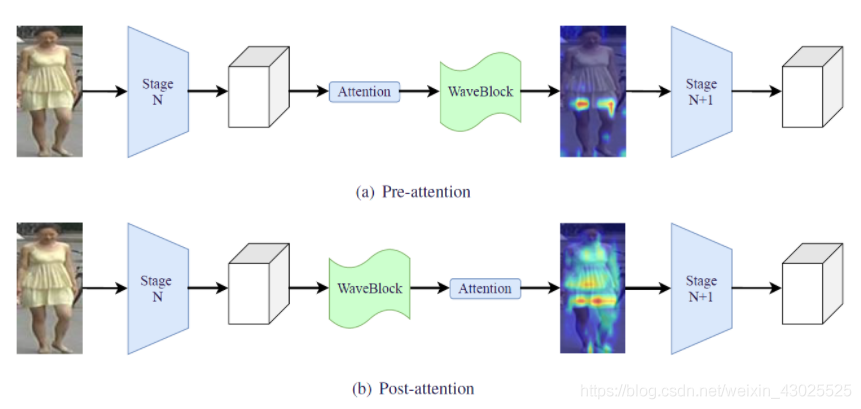
注意力和AWB的组合有两种方式,前注意力和后注意力,如下图所示,简单易懂,前注意力的优点是可以利用完整的特征来计算注意力,后注意力的优势是可以进一步增大特征差异。
4.1 CBAM
一种轻量的注意力模块,包含两个独立的子模块, 这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。先通道再空间的结果会稍微好一点
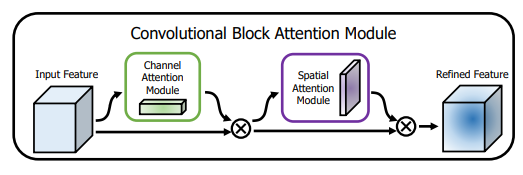
CAM(通道注意力模块):
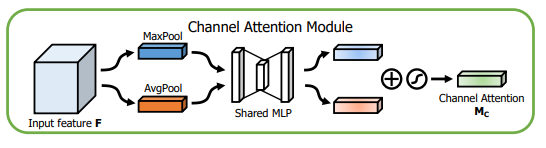
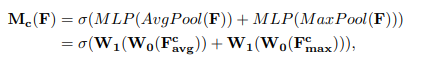
具体流程如下:
将输入的特征图F(H×W×C)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即M_c。最后,将M_c和输入特征图F做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
SAM(空间注意力模块):
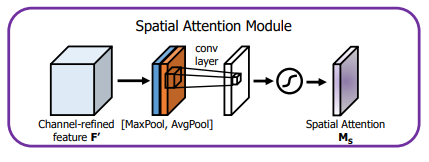
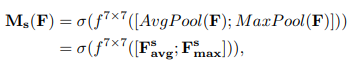
具体流程如下:
将Channel attention模块输出的特征图F‘作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,得到两个H×W×1 的特征图,然后将这2个特征图基于channel 做concat操作(通道拼接)。然后经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即H×W×1。再经过sigmoid生成spatial attention feature,即M_s。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
4.2 Non-local block
某一像素点处的响应是其他所有点处的特征权重和,将每一个点与其他所有点相关联,实现non-local 思想。
5 实验结果
