A-题目描述:
请找到两个正整数X和Y满足下列条件:
1、2019<X<Y
2、2019
2
、X
2
、Y
2
构成等差数列
满足条件的X和Y可能有多种情况,请给出X+Y的值,并且令X+Y尽可能的小
答案:
7020
我的思路:
想用 for 循环但又不知道循环到什么位置(即第二个参数不知道填什么)
别人的编程:
#include<iostream>
#include<cmath>
using namespace std;
int main()
{
int t=2019*2019;
for(int x=2020;;x++)
{
int x2=x*x;
int y2=2*x2-t;
int y=sqrt(y2);
if(y*y==y2)
{
cout<<x+y<<endl;
break;
}
}
return 0;
}
别人的思路:
一重循环
从2020开始遍历X的值,对于每一个X的值,利用等差数列的条件求出Y
2
的值,只需要判断开方得到的Y是不是整数即可。(可以将Y再次平方,看数值是否发生变化)
我学到的:
思路很新颖,值得学习(对我来说)
判断一个数是不是整数可以根据开方得到的与再平方得到的是不是一样的来证明
B-题目描述:
2019可以被分解成
若干个
(不是两个)两两不同的素数,请问不同的分解方案有多少种?
注意:分解方案不考虑顺序,如2+2017=2019和2017+2=2019属于同一种方案
答案:
55965365465060
我的编程:
#include <sstream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cmath>
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
#include <string>
#include <queue>
#include <stack>
#include <map>
#include <set>
#define _for(i,a,b) for(int i=a;i<b;i++)
#define _unfor(i,a,b) for(int i=a;i>=b;i--)
#define RI(a) scanf("%d",&a)
#define mset(a,val,n) for(int i=0;i<n;i++)a[i]=val;
#define mset2(a,val,n,m) for(int i=0;i<n;i++)for(int j=0;j<m;j++)a[i][j]=val;
#define FI freopen("D:\\in.txt","r",stdin)
#define FO freopen("D:\\out.txt","w",stdout)
using namespace std;
typedef long long LL;
/*-------下面为主要代码-------*/
const int N=1e4+20;
const int M=2019;
int pre[N],cnt;
bool vis[N];
LL dp[N][N];
void prime() //用到了 N、cnt 和 pre[N] 和 vis[N]
{
for(int i=2;i<N-10;i++)
{
if(!vis[i])
pre[cnt++]=i;
for(int j=0;j<cnt&&i*pre[j]<N-5;j++)
{
vis[i*pre[j]]=1;
if(i%pre[j]==0)break;
}
}
}
int main()
{
prime();
for(int i=0;pre[i]<=M;i++)
dp[pre[i]][pre[i]]=1; //所有代表质数的 dp 数组都为 1,代表了自身算 1个质数
for(int i=2;i<=M;i++) //循环 2019 - 2 次是为了使所有的第一维数组都重新赋值 (一维数组)
{
for(int j=0;pre[j]<=i;j++) //循环小于 i 的 质数次是为了使所有的第二维数组都重新赋值 (二维数组)
{
for(int k=0;k<j&&pre[k]<=i-pre[j];k++) //此循环是为了使 dp数组的元素加小于自身的 质数值 (加元素)
dp[i][pre[j]]+=dp[i-pre[j]][pre[k]]; //状态转移方程
}
}
LL ans=0;
for(int i=0;pre[i]<=M;i++)
ans+=dp[M][pre[i]];
cout<<ans<<endl;
return 0;
}
解析:
① 先用
欧拉线性筛法
将素数筛出来,存在pre数组中
② 再用三层 for 循环进行 状态转移方程
(可以用 9 = 2 + 7 的分解思想联系代码想想看)
注意第三层 for 循环条件是
k<j&&pre[k]<=i-pre[j]
👇下面以求20的分解方案举例

提醒:dp[20][13]表示被分解数为20并且分解出的最大素数恰好为13的方案数,以此类推…
问:为什么没有 dp[20][20] ?
答:因为20不是质数
问:为什么有 dp[7][5] 却没有 dp[7][2] ?
答:因为 dp[7][2] 又可以在分成 dp[5][3],而3 > 2,这不满足第三层 for 循环的条件
问:为什么 dp[2][2]、dp[3][3] 等于 1
答:因为这时它不代表分成自身和 0 的意思,它代表的是质数本身
C-题目描述:(题目不全)
7×7方格,分成两部分,每部分连通,右半部分翻转旋转拼接之后也是7×7,
有多少种分割方法(题目不全)
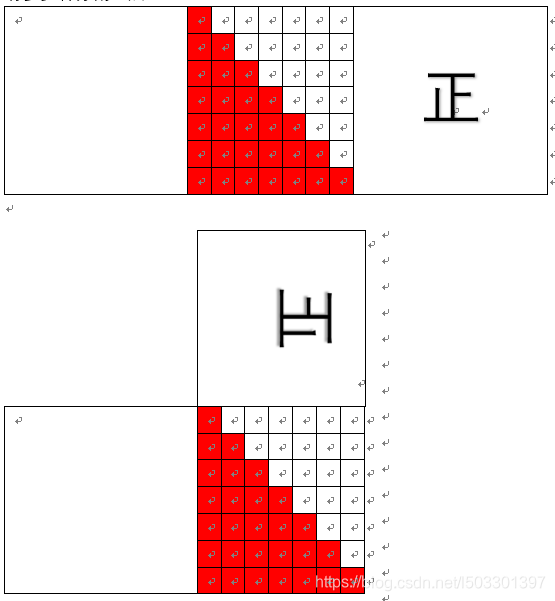
待补充
D-题目描述:
有一个7X7的方格。方格左上角顶点坐标为(0,0),右下角坐标为(7,7)
求满足下列条件的路径条数:
1、起点和终点都是(0,0)
2、路径不自交
3、路径长度不大于12
4、对于每一个顶点,有上下左右四个方向可以走,但是不能越界
例如,图中路线,左上角顶点(0,0),路线长度为10
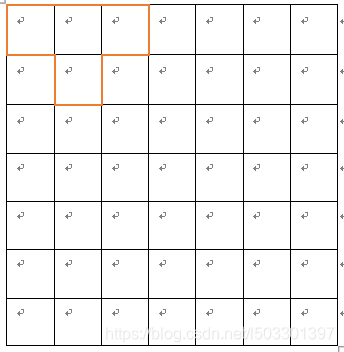
答案:
206
我的思路:
普通的DFS,但是在判定ans处加一个条件:
走过的路径大于等于4
我的编程:
#include <sstream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <cmath>
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
#include <string>
#include <queue>
#include <stack>
#include <map>
#include <set>
#define _for(i,a,b) for(int i=a;i<b;i++)
#define _unfor(i,a,b) for(int i=a;i>=b;i--)
#define RI(a) scanf("%d",&a)
#define mset(a,val,n) for(int i=0;i<n;i++)a[i]=val;
#define mset2(a,val,n,m) for(int i=0;i<n;i++)for(int j=0;j<m;j++)a[i][j]=val;
#define FI freopen("D:\\in.txt","r",stdin)
#define FO freopen("D:\\out.txt","w",stdout)
using namespace std;
typedef long long LL;
/*-------下面为主要代码-------*/
int vir[7][7];//标记
int ans;//全部路径
int dir[4][2] = {{-1,0},{1,0},{0,-1},{0,1}};//上下左右
bool check(int nx,int ny,int nz)
{
if(nx<0||nx>7||ny<0||ny>7||vir[nx][ny]||nz>12) return false;
return true;
}
int dfs(int x,int y,int z)
{
if(x==0&&y==0&&z<=12&&z>=4) ans++;
else
{
_for(i,0,4)//上下左右
{
int nx=x+dir[i][0];
int ny=y+dir[i][1];
int nz=z+1;
if(check(nx,ny,nz))
{
vir[nx][ny]=1;
dfs(nx,ny,z+1);
vir[nx][ny]=0;
}
}
}
return ans;
}
int main()
{
int temp=dfs(0,0,0);
cout<<temp;
return 0;
}
别人的思路:
DFS模板稍微和平时不一样,先搜索再判定,这样就避免了判断结果影响ans,还有,用dfs函数前先标记(0,0)
别人的编程:
#include<cstdio>
#include<cstdlib>
#include<iostream>
#include<algorithm>
using namespace std;
typedef long long ll;
const int N=25;
int ans;
bool vis[N][N];
int b[4][2]={{0,1},{0,-1},{1,0},{-1,0}};
void dfs(int x,int y,int k)
{
if(k>12)
return;
for(int i=0;i<4;i++)
{
int tx=x+b[i][0];
int ty=y+b[i][1];
if(!tx&&!ty&&k+1>2&&k+1<=12)
ans++;
if(tx<0||tx>7||ty<0||ty>7)continue;
if(vis[tx][ty])continue;
vis[tx][ty]=1;
dfs(tx,ty,k+1);
vis[tx][ty]=0;
}
return;
}
int main()
{
vis[0][0]=1;
dfs(0,0,0);
vis[0][0]=0;
cout<<ans<<endl;
return 0;
}
我学到的:
思路挺新颖(对我来说),提醒了我要适当跳出模板,勇于尝试新方法
E-题目描述:
有1个约数的最小数为1(1),有两个约数的最小数为2(1,2)……
有n个约数的最小数为Sn
S1=1 (1)
S2=2 (1 2)
S3=4 (1 2 4)
S4=6 (1 2 3 6)
求S100(即约数的数量恰好是100的最小正整数)
答案:
45360
我的思路:
若从 1 开始到自身的每个数都能自身被整除则都算是约数,再统计有多少个数若是100则取自身的那个整数,我猜测从1000开始
我的编程:
#include <stdio.h>
#include <math.h>
int main()
{
int a;
for (a = 1000;; a++)
{
int count = 0;
for (int x = 1; x <= a; x++)
{
if (a % x == 0)
{
count += 1;
}
}
if (count == 100)
{
break;
}
}
printf("%d", a);
return 0;
}
别人的编程:
#include<cstdio>
#include<iostream>
using namespace std;
int main()
{
for(int i=1;;i++)
{
int sum=0;
for(int j=1;j<=i;j++)
{
if(i%j==0)
sum++;
}
if(sum==100)
{
cout<<i<<endl;
break;
}
}
return 0;
}
别人的思路:
两重for循环暴力
F-题目描述:(未)
题目给定两个字符串S和T,保证S的长度不小于T的长度,问至少修改S的多少个字符,可以令T成为S的子序列。
输入描述:
输入两行
第一行是字符串S,第二行是字符串T。
保证S的长度不小于T的长度,S的长度范围在10~1000之间。
样例输入1:
ABCDABCD
AABCX
样例输出1:
1
样例输入2:
ABCDABCD
XAAD
样例输出2:
2
样例输入3:
XBBBBBAC
ACC
样例输出3:
2
我的思路:
无
别人的编程:
#include<cstdio>
#include<iostream>
#include<string>
using namespace std;
const int N=1e3+10;
int dp[N][N];
string s,t;
int main()
{
cin>>s>>t;
int ls=s.size();
int lt=t.size();
if(s[0]!=t[0])
dp[0][0]=1;
for(int i=1;i<lt;i++)
if(s[i]==t[i])
dp[i][i]=dp[i-1][i-1];
else
dp[i][i]=dp[i-1][i-1]+1;
for(int i=1;i<ls;i++)
{
if(s[i]==t[0])
dp[i][0]=0;
else
dp[i][0]=dp[i-1][0];
}
for(int j=1;j<lt;j++)
for(int i=j+1;i<ls;i++)
if(s[i]==t[j])
dp[i][j]=dp[i-1][j-1];
else
dp[i][j]=min(dp[i-1][j],dp[i-1][j-1]+1);
printf("%d\n",dp[ls-1][lt-1]);
return 0;
}
别人的思路:
动态规划
dp[ i ] [ j ]表示令T的前j个字符成为 S 的前 i 个字符的子序列需要修改的字符个数
先初始化 i = j 和 j = 0 的情况。
状态转移方程:
if ( s [ i ] == t [ j ] )
dp[ i ][ j ] = dp [ i-1 ][ j-1 ];
else
dp[ i ][ j ] = min ( dp [ i-1 ][ j ] , dp [ i-1 ][ j-1 ] + 1 )
我学到的:
回头看
G-题目描述:三色三圈的火柴游戏(未)
三圈火柴,外圈12根,中圈8根,内圈4跟,红的一共12根,黄色8绿色4
三圈可以同时顺时针旋转一个单位
三圈可以同时逆时针旋转一个单位
三圈最顶部的火柴可以按特定顺序旋转替换(外,中,内—>中,内,外),其他方式不可以
第一行输入n,代表需要判断n组
三圈用三个字符串表示,R红,Y黄,G绿
问能不能替换到最外圈全为红,中间全黄,内圈全绿。可以输出Yes,否则No
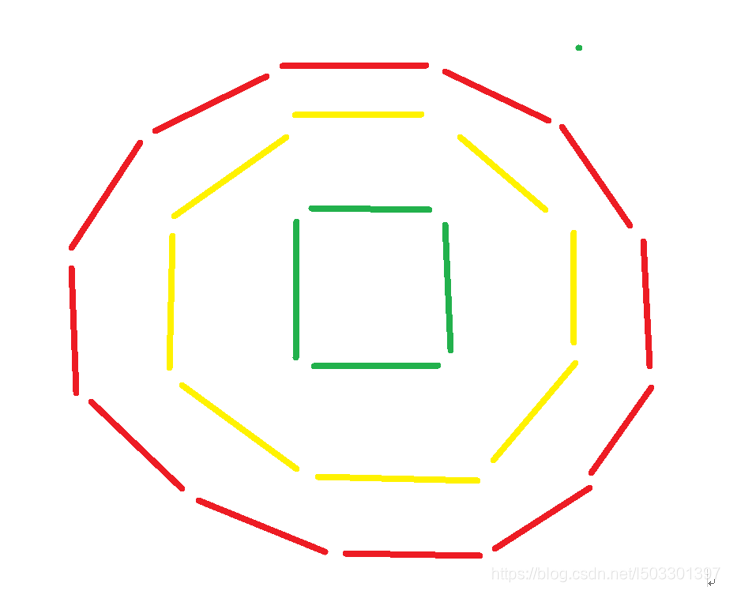
输入样例:
2
RGRRRRRRRRRR
YRYYYYYY
GYGG
RRGRRRRRRRRR
YYYYYYYY
GGRG
输出样例:
Yes
No
我的思路:
无
别人的编程:
未找到…
别人的思路:
未找到…
我学到的:
无
H-题目描述:(未)

对于一个数列中的某个数,如果这个数比两侧的数都大或比两侧的数都小,我们称这个数为这个数列的一个转折点。
如果一个数列有t个转折点,我们称这个数列为t+1调数列。
给定两个正整数n,k。求在1~n的全排列中,有多少个数列是k调数列。
(自己写全排列代码+剪枝)
数据范围:
对于10%的数据,0<=k,n<=10
对于20%的数据,0<=k,n<=20
对于30%的数据,0<=k,n<=100
对于100%的数据,0<=k,n<=1000
输入描述:
两个正整数n,k。
输出描述:
答案,一个整数。
输入样例:
4 2
输出样例:
12
我的思路:
全排列函数 next_permutation 用法可以点
这里
把数组所有的顺序给排列一遍(全排列),再一个个的找哪个符合要求,但是这种暴力的做法只能拿10%的分
【但是比赛过程中我们可以打表(花大量时间运行代码并把答案输入)这样估计可以拿到20%的分】
我的编程:
#include <bits/stdc++.h>
using namespace std;
const int N=1e7+10;
int main()
{
int n,k;cin>>n>>k;
int a[n+1],t=0;
for(int i=1;i<=n;i++) a[i]=i;
do{
int ans=0;
for(int j=2;j<=n-1;j++)
{
if((a[j]>a[j-1]&&a[j]<a[j+1])||(a[j]<a[j-1]&&a[j]>a[j+1])) ans++;
}
if(ans+1==k) t++;
}while(next_permutation(a+1,a+n+1));
cout<<t<<endl;
return 0;
}
别人的思路:
利用全排列的递归函数,剪枝,水数据(但也只能拿10%的分)
别人的编程:
#include<cstdio>
#include<iostream>
using namespace std;
const int N=1e3+10;
int n,k,ans,a[N];
void swap(int x,int y)
{
int t=a[x];
a[x]=a[y];
a[y]=t;
return;
}
bool pd(int x)//判断a[x]是不是转折点
{
if(a[x]>a[x-1]&&a[x]>a[x+1]||a[x]<a[x-1]&&a[x]<a[x+1])
return 1;
return 0;
}
void dfs(int m,int sum)//m为递归层数,sum为已经有的转折点数量
{
if(m>2&&pd(m-2))//判断a[m-2]是不是转折点
sum++;
if(sum>k-1||sum+n-m<k-1)//转折点过多或者过少都剪枝
return;
if(m==n-1)//全排列递归出口
{
if(m>1&&pd(m-1))
sum++;
if(sum==k-1)
ans++;
return;
}
for(int i=m;i<n;i++)//全排列函数的函数主体
{
swap(m,i);
dfs(m+1,sum);
swap(m,i);
}
return;
}
int main()
{
cin>>n>>k;
for(int i=0;i<n;i++)//初始化数组
a[i]=i+1;
dfs(0,0);
cout<<ans<<endl;
return 0;
}
I-题目描述:第八大奇迹(未)
有一条河,沿河的一侧生活着一个部落。这个
一字型
的部落有n个据点,从左至右依次编号1~n
部落的人们有时会在某个据点建立建筑,每个建筑都有各自的价值。一开始,每个据点的都没有建筑,价值都是0。如果在已有建筑的据点建立新的建筑,那么
新的建筑会代替旧的建筑(旧的建筑就此消失)
有两种操作C和Q:
1、C x y,表示在据点x建立一个价值为y的建筑
2、Q x y,询问在据点x~y之间(包括x,y)的建筑中,价值
第八大
的建筑的价值是多少
(线段树,主席树)
输入描述:
第一行,两个正整数n和k,表示据点的数量和操作的数量
接下的k行,每行一个操作
输出描述:
对于所有的Q操作,输出相应的
第八大
建筑的价值
输入样例:
10 14
C 1 5
C 2 4
C 3 7
C 4 6
C 5 5
C 6 1
C 7 8
Q 1 10
C 8 3
C 9 6
C 10 3
Q 1 9
C 6 10
Q 1 10
输出样例:
0
3
4
我的思路:
无
别人的编程:
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
typedef long long ll;
const int N=1e5+20;
int ans[17];//用于输出
char s[12];//用于读入字符C和Q
struct node{
int l,r;
int a[17];
}tr[N<<2];
bool pd(int x,int y)//sort排序依据
{
if(x>y)
return 1;
return 0;
}
void pushup(int m)//线段树回溯函数
{
for(int i=1;i<=8;i++)
tr[m].a[i]=tr[m<<1].a[i];
for(int i=9;i<=16;i++)
tr[m].a[i]=tr[m<<1|1].a[i-8];
sort(tr[m].a+1,tr[m].a+17,pd);//及时sort
return;
}
void build(int m,int l,int r)//建立线段树
{
tr[m].l=l;
tr[m].r=r;
if(l==r)
{
memset(tr[m].a,0,sizeof(tr[m].a));
return;
}
int mid=(l+r)>>1;
build(m<<1,l,mid);
build(m<<1|1,mid+1,r);
pushup(m);
return;
}
void update(int m,int x,int y)//更新数据
{
if(tr[m].l==x&&tr[m].r==x)
{
tr[m].a[1]=y;
return;
}
int mid=(tr[m].l+tr[m].r)>>1;
if(x<=mid)
update(m<<1,x,y);
else
update(m<<1|1,x,y);
pushup(m);
return;
}
void query(int m,int l,int r)//查询数据
{
if(tr[m].l==l&&tr[m].r==r)
{
for(int i=9;i<=16;i++)
ans[i]=tr[m].a[i-8];
sort(ans+1,ans+17,pd);//及时sort
return;
}
int mid=(tr[m].l+tr[m].r)>>1;
if(r<=mid)
query(m<<1,l,r);
else if(l>mid)
query(m<<1|1,l,r);
else
{
query(m<<1,l,mid);
query(m<<1|1,mid+1,r);
}
return;
}
int main()
{
int n,k,x,y;
cin>>n>>k;
build(1,1,n);
for(int i=0;i<k;i++)
{
scanf("%s%d%d",s,&x,&y);
if(s[0]=='C')
{
update(1,x,y);
}
else
{
for(int j=1;j<=8;j++)
ans[j]=0;
query(1,x,y);
printf("%d\n",ans[8]);
}
}
return 0;
}
别人的思路:
线段树+sort
线段树基础
戳这里
!
我学到的:
无
J-题目描述:(未)

我的思路:
无
别人的编程:
无
别人的思路:
无
我学到的:
无