转载请注明出处,https://www.cnblogs.com/CooperXia-847550730/p/10533558.html
禁止用于商业用途,一切后果与本人无关
小夏又来写博客啦
7.28号更新:
这次bug已经被修复了,这是现在大图和缩略图的url,有没有同学能看出来用的编码或者是hash函数的,救救救:
http://img4.tuwandata.com/v4/thumb/jpg/0jzUF68uv59al8ebGw14O0jSobjQ82o1sgld3dqyiQQ/u/GLDM9lMIBglnFv7YKftLBGTPBuZ18dsRxq7lLFRmwHNxm5vYTWcBQBPs4lxofIIDDVim1oGbBWgRPuawq1D61NhUxeeJzZX9lVSQjIO3fgyT.jpg
http://img4.tuwandata.com/v4/thumb/jpg/YEAUN6ZWzfHEsgvPUPw9gdUbktn6iwdmnlyB750N6JX/u/GLDM9lMIBglnFv7YKftLBGTPBuZ18dsRxq7lLFRmwHNxm5vYTWcBQBPs4lxofIIDDVim1oGbBWgRPuawq1D61NhUxeeJzZX9lVSQjIO3fgyT.jpg
F0T8XzPwra6yZkoLvv2Z90EsdPzyytjgLk0sQl5RUI3
0nNli0OxejHpzyKVvywJXEm5yTRcZo6uQRDUMjgOeAu/u/GLDM9lMIBglnFv7YKftLBGTPBuZ18dsRxq7lLFRmwHNqHCyCn9OOp9AtNTrIM8rW93vyCEmhAT6ZRshSh4lWWBj1NuET2DQ8hxUAqFZ8lTOx.jpg
BXgEbTpyf4wvFKyQqj60F3KOwQ725PfdHLCEKYUIWN5
4XkDSNsY3jKCgTc6SvuirtbSF64gD6vhGnHGx3WUyme/u/GLDM9lMIBglnFv7YKftLBGTPBuZ18dsRxq7lLFRmwHNqFCvUrqmSG4Hr3vVp0zDfryydDwhgTxyTVbfMLhjM7h3lmIF6bRSli2HSEobMbl9c.jpg
这次的爬虫是兔玩君分享计划的所有收费套图
不知道的同学可以看这里www.tuwanjun.com
简单的说一下吧,这个网站通Jquery+JS的方式加载图片,每套图只可以看三张,之后要收费
但是博主发现了一个小漏洞,缩略图的url和大图地址文件名基本相同,路径也有由参数构成的,base64解码url发现,小图和大图只有部分参数不同,并且每组图可以通过替换获得完整图片地址。
秀一下:
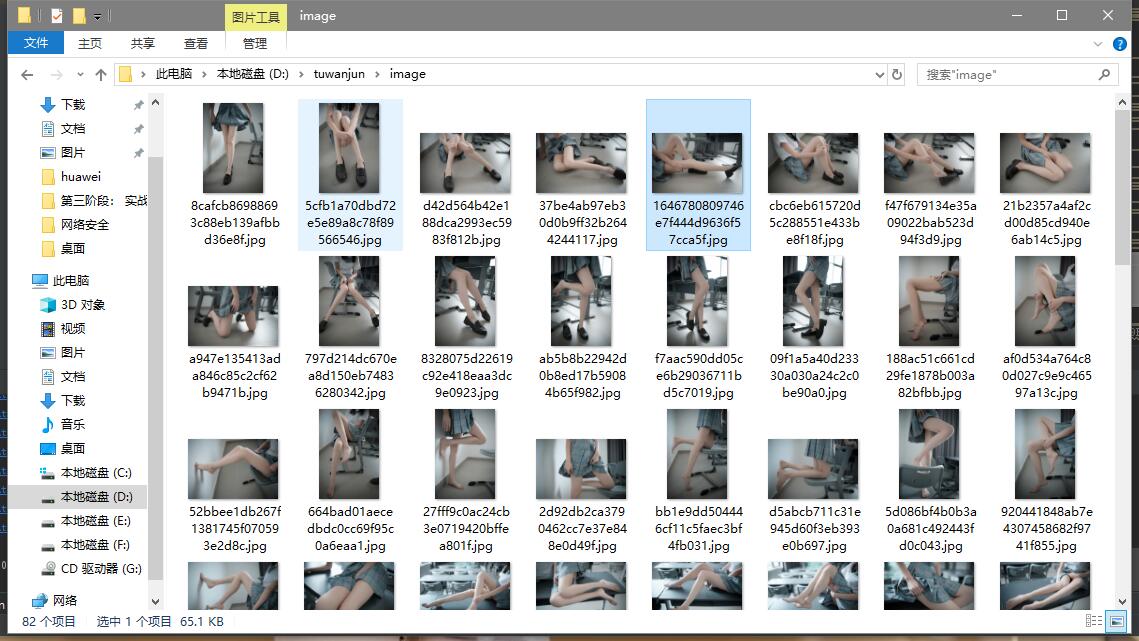
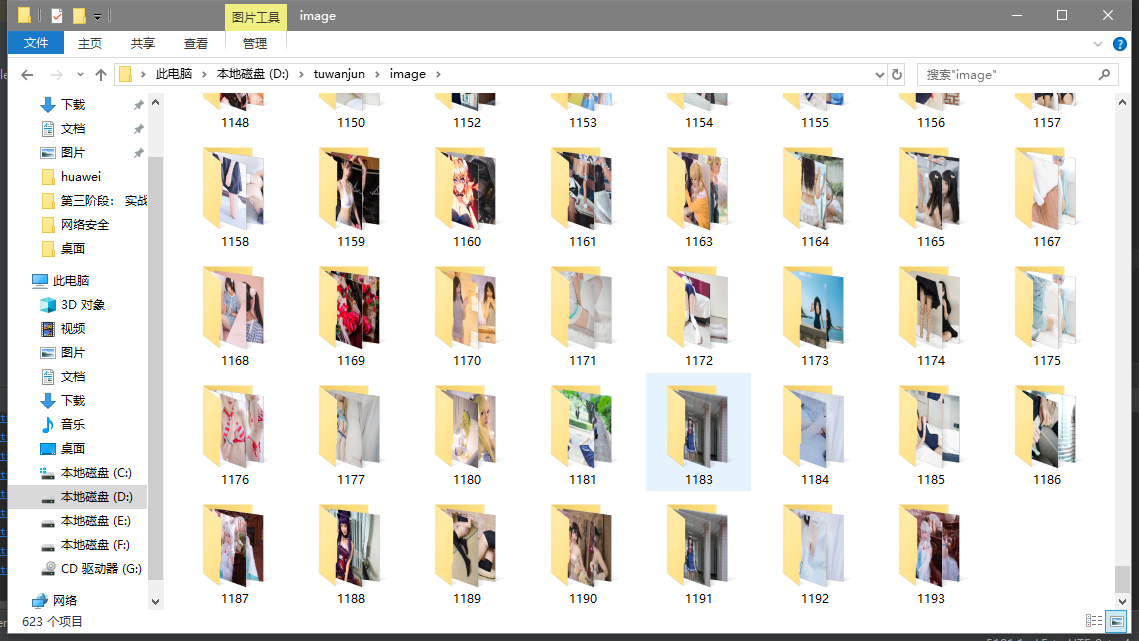
脚本是3.14号写的,跑完之后一共爬取到1015套写真,6.4号又跑了一次,新增了112套,目前总计1127套
这里不再提供全部源码,只给出核心代码,求打赏,求赞助,欢迎加入精神股东!小白,大股东,土豪,萌妹,可以+xwd2363,赞助100块,1127套写真,直接百度云给你!
def get_page(offset):
key={
'type':'image',
'dpr':3,
'id':offset,
}
url = 'https://api.tuwan.com/apps/Welfare/detail?' + urlencode(key)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print("请求页出错", url)
return None
def getUrl(html):
pattern1 = re.compile('"thumb":(.*?)}', re.S)
result = re.findall(pattern1, html)
bigUrl=result[0]
bigUrl=bigUrl.replace('"','').replace('\\','')
pattern2 = re.compile('(http.*?.+jpg),', re.S)
result2 = re.findall(pattern2, bigUrl)
bigUrl=result2[0]
pattern3 = re.compile('(http.*?==.*?\.jpg)', re.S)
result3=re.findall(pattern3,result[3])
smallUrl = []
for item in result3:
# print(item.replace('\\',''))
smallUrl.append(item.replace('\\',''))
return (bigUrl,smallUrl)
def findReplaceStr(url):
pattern = re.compile('.*?thumb/jpg/+(.*?wx+)(.*?)(/u/.*?).jpg', re.S)
result = re.match(pattern, url)
return result.group(2)
def getBigImageUrl(url,replaceStr):
pattern = re.compile('.*?thumb/jpg/+(.*?wx+)(.*?)(/u/.*?).jpg', re.S)
result = re.match(pattern, url)
newurl='http://img4.tuwandata.com/v3/thumb/jpg/'+result.group(1)+replaceStr+ result.group(3)
return newurl
def save_image(content,offset):
path='{0}'.format(os.getcwd()+'\image\\'+str(offset))
file_path='{0}\{1}.{2}'.format(path,md5(content).hexdigest(), 'jpg')
if not os.path.exists(path):
os.mkdir(path)
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def download_images(url,offset):
print('downloading:',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content,offset)
return None
except RequestException:
print("请求图片出错",url)
return None
def download(bigImageUrl,smallImageUrl,offset):
replaceStr = findReplaceStr(bigImageUrl)
for url in smallImageUrl:
download_images(getBigImageUrl(url,replaceStr),offset)
转载于:https://www.cnblogs.com/CooperXia-847550730/p/10533558.html