
最近逛技术论坛,发现一个牛到逆天的英伟达项目,刚刚发布几个月,全称为:
Instant Neural Graphics Primitives
[1]
,
项目链接为:
https://github.com/NVlabs/instant-ngp
该项目提出一个称为Multiresolution Hash Encoding的技术,能够大大提升NeRF网络的训练速度,使之可以从几分钟缩短到几秒钟。显示结果好的让人震惊。今天我们就用这篇博客来看一下Instant-ngp对传统的NeRF到底做出了哪些改善,以改善重建效率。
注:NeRF三维重建技术我已经在之前的博客中介绍过, 链接如下
火爆科研圈的三维重建技术:Neural radiance fields (NeRF)_程序猿老甘的博客-CSDN博客_nerf 三维重建
1. 简介
Instant-ngp主要用于解决NeRF在对全连接神经网络进行参数化时的效率问题。该方法提出一种编码方式,使得可以使用一个较小规模的网络来实现NeRF同时不会产生精度的损失。该网络由特征向量的多分辨率哈希表实现增强,基于随机梯度下降执行优化。多分辨率结构有助于GPU并行,能够通过消除哈希冲突减少计算。该方法最大的亮点是将NeRF以小时计的时间开销提升到秒级。下图为一些渲染样例,可以看到渲染时间有显著的提升。
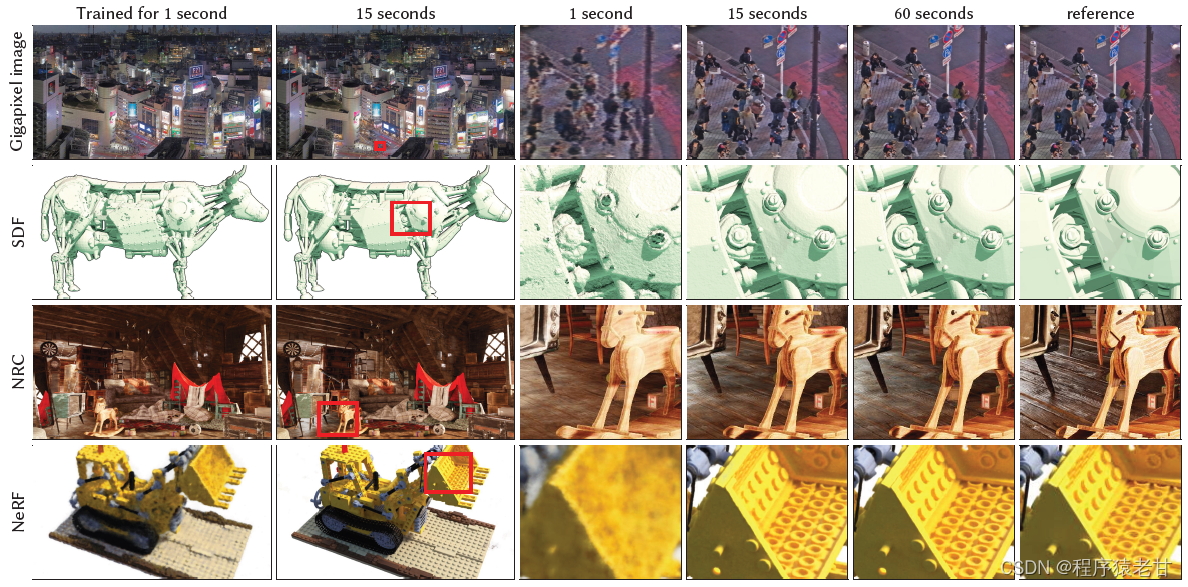
图1. 多分辨率哈希编码在各个训练任务中的结果
这里需要注意的是,作者给出了一些关于计算机图形学与神经网络交叉融合的基本观点:
将神经网络的输入映射到一个高维空间,进而从压缩模型中提升拟合结果的质量。
优点包括可训练,特定于任务的数据结构,解决了大量的学习任务,使得小样本MLP可用。但是,这个过程启发式的,结构化的调整,进而造成因调整产生的性能下降,泛化性差,并行设计开销大。Instant-ngp的建立则是为了解决上述问题。基于由粗到细的哈希搜索实现网格到特征向量的分级对应,提供了该项技术的适应性与效率。我对Instant-ngp直观感觉,仍然没有跳出类似光线追踪时期提出的分区索引概念,很像包围盒思想。该框架已经在四项工作中得到应用,包括:Gigapixel image;Neural signed distance functions(SDF);Neural radiance caching(NRC);Neural radiance and density fields (NeRF),结果如图1所示(这个超分辨率计算的效果非常出色)。
2. 实现细节
由简介可知,Instant-ngp项目最大的亮点在于提出了一个基于哈希搜索的编码方法,仅需一个小规模神经网络就能够实现全连接网络的效果,而且不损失精度。因此,该文章的核心要点可被分为两个部分:1). 多分辨率哈希编码的设计与实现;2). 基于编码的神经网络训练。
2.1 多分辨率哈希编码
稍微了解哈希搜索的人都应该了解其算法效率,根据内容就能直接定位数据位置。即使需要二次搜索相同哈希值下的候选,只要在设计时保持数据分布的平衡,依然可保持高效计算。
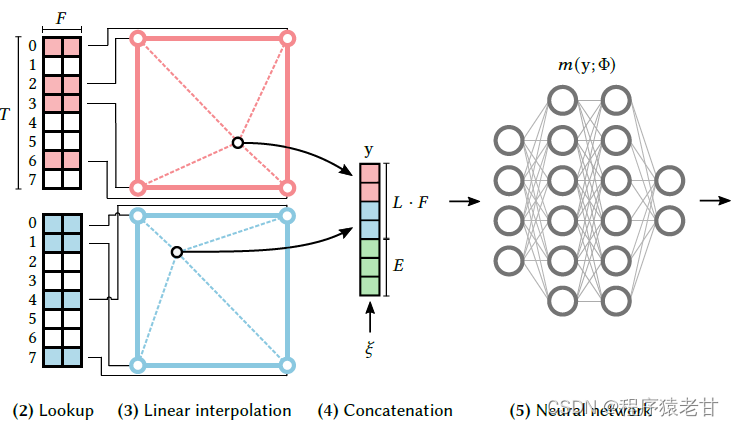
假设提供一个全连接层m(y;Φ), Instant-ngp设计一个针对输入的再赋权:y=enc(x,𝜃)用来提升拟合质量和训练速度,同时避免额外的计算开销。这使得 Instant-ngp不仅拥有可训练的权重值Φ,同时还拥有可训练的编码权重𝜃。这些权重被安排再L层中,每层包含T个特征向量,伴随F维的数据。这些超参数值被表示在下表中:

原文展示了一个示意图,来说明点的哈希编码方法:
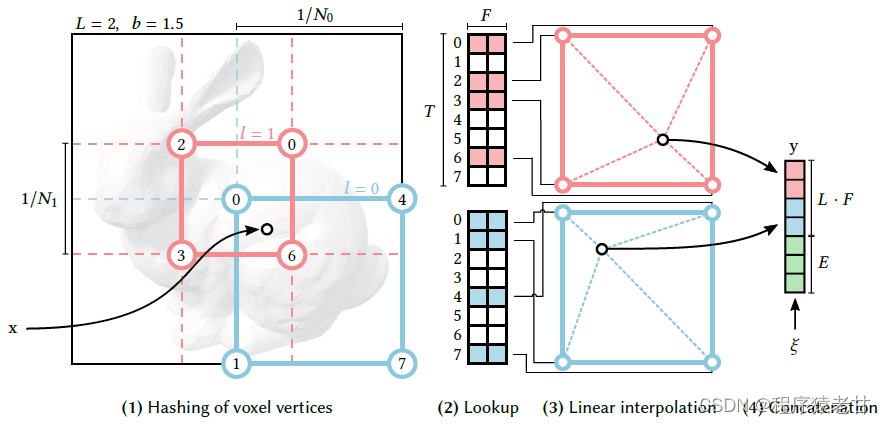
该图表示了利用不同分辨率的体素结构来编码点云数据的方式。红色方框表示的是分辨率较高的体素网格,蓝色方框对应的是分辨率较低的提速网格。根据网格顶点的数值以及对应的位置,可以实现对网格内部点的编码。该过程可以较快执行的原因在于整个编码过程是面向数值本身实现的,因此不需要搜索,仅需要比较计算即可实现快速精确定位与编码,并输出最终我们需要的T个L维特征向量。
L对应的是特定分辨率体素对应的编码层,按照之前表格给出的超参数,层数被设置为16,即体素分辨率变化分为16级,对应的分辨率随级别变化的公式为:
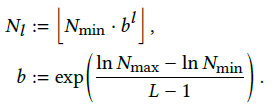
b被认为是成长参数,原文设定的b值在1.38到2之间。考虑L层中的一个单层
l
。输入的坐标点被对应层网格缩放为:

对于粗网格,不需要T个参数,即
。这样映射就能保证一对一的关系。对于精细网格,使用一个哈希映射函数,
来索引到数组,虽然没有显示的碰撞处理。这里使用的空间哈希函数为:
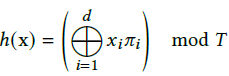
运算⊕表示XOR(异或)运算,𝜋𝑖是独一无二的大素数。该计算在每一维产生线性同余排列,以解除维度对散列值的影响(这里确实没有看懂,有兴趣的同学可以参看文献[2])。最后根据x在体素里的相对位置,实现对体素内角点的特征向量线性插值,插值的权重为:

想象一个,这个计算过程是可以在L层中独立的执行的,不会产生层间干扰。这样使得每一层的插值向量以及辅助输入(编码视图方向和纹理在神经辐射缓存)被串联以产生y,
。y是由输入的enc(x;𝜃)到MLP m(y;Φ)。
2.2 神经网络训练实现
性能考量
为了提升反向传播性能,作者提出存储哈希表条目在一个半精度浮点数中,即每个条目两个字节。另外,算法维护了一个全精度的参数主副本,以便稳定的混合精度参数更新。为了优化使用的GPU缓存,作者逐层的评估哈希表:当处理一个batch的输入位置时,作者安排计算来查看第一层所有输入的第一层哈希编码,跟随对应的第二层所有输入,逐层查找。因此只有少量连续的哈希表不得不驻留在缓存,依赖于GPU的并行计算能力。
MLP结构
除了NeRF,使用具有两个隐层的MLP,包含64个神经元以及ReLU函数构建网络结构,如下图所示。损失和输出激活的选择是特定于任务的,将在相应的子节中详细说明。
NeRF也是包含两个串联的MLP,一个密度MLP与一个颜色MLP。密度MLP映射哈希编码位置y=enc(x,θ)到一个16位的输出值,将其视为对数空间密度。颜色MLP添加视点相关的颜色变化。该结构的输出是一个颜色的三元组,当训练数据具有低动态范围(sRGB)时,我们使用sigmoid激活;当训练数据具有高动态范围(线性)时,我们使用指数激活(线性HDR)。相比之下,作者推荐HDR training data。
初始化
参考文献[3],提供一个合理的神经网络各层的激活尺度及其梯度,即一个均匀分布实现对哈希表项目的初始化:
,值接近于0。注:这部分内容似乎没有什么特别需要注意的地方,原文大部分介绍的实现细节基本与之前的主流工作保持一致。鉴于我确实缺乏对深度学习一些基本该概念的了解,就不再对上述内同进行展开解释了。如果你真的希望了解一些背后的知识,推荐你学习文献[4-7]。
3. 部分实验结果
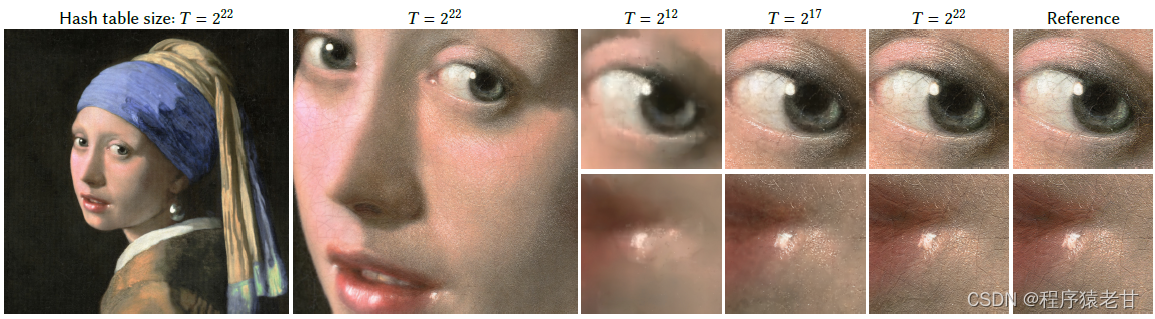
图3.1 超分辨率图像处理示意图

图3.2 超分辨率图像处理动态示意图

图3.3 三维重建动态示意图
4. 总结
全文看下来,感觉比较创新的地方就是使用了一个多级的体素搜索结构来实现对数据的权重搜索。效率的提升就是基于这样一种多级的索引结构,使得权重优化与数据计算能够被逐级的控制在不同层次对应的有个子区域。这样,对于权重优化,就能够避免过多无效的计算过程。整个框架的实现简洁,高效,且适用于多个应用。英伟达非常满意该项技术,最近还有多家媒体报道,介绍该项技术的创新型贡献。
新闻链接:
GIF动态图片:

Reference
[1] Müller T, Evans A, Schied C, et al. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding[J]. arXiv preprint arXiv:2201.05989, 2022.
[2] Teschner M, Heidelberger B, Müller M, et al. Optimized spatial hashing for collision detection of deformable objects[C]. Vmv. 2003, 3: 47-54.
[3] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]. Proceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010: 249-256.
[4] Da K. A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.4
[5] Müller T, McWilliams B, Rousselle F, et al. Neural importance sampling[J]. ACM Transactions on Graphics (TOG), 2019, 38(5): 1-19.
[6] Müller T, Rousselle F, Novák J, et al. Real-time neural radiance caching for path tracing[J]. arXiv preprint arXiv:2106.12372, 2021.
[7] Verbin D, Hedman P, Mildenhall B, et al. Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields[J]. arXiv preprint arXiv:2112.03907, 2021.