CTPN训练自己的数据集
代码来自:
eragonruan/text-detection-ctpn
一,下载预训练模型
下载链接:
预训练模型
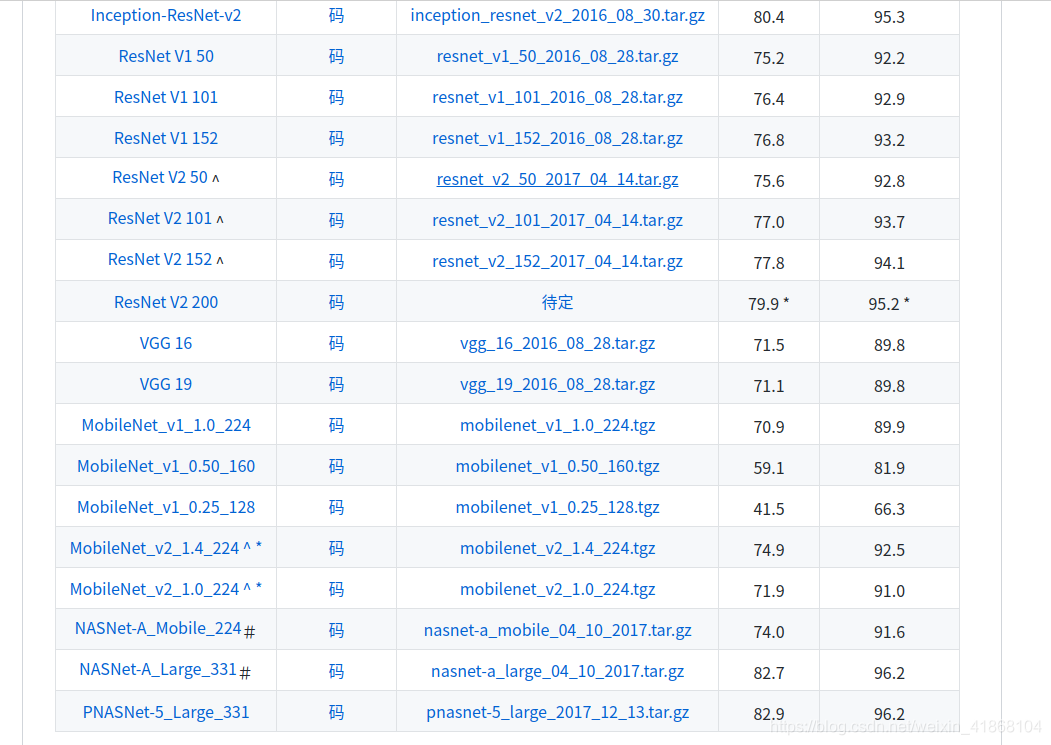
选择VGG16,但是貌似下载特别慢。下载VGG net的预训练模型解压并将其放在data / vgg_16.ckpt中。
二,准备自己的训练集
目的:将原始数据中四个点框住的文本切分为16份。
1.我的原始数据是利用labelimage生成的xml文件格式,需要先将xml文件中的坐标信息转化为txt格式,在我的前几篇文章中有参考代码。生成的坐标信息如图所示:

至于代码作者贴出的格式中,后面写的“english,###“表示没有作用,只需要四个点的坐标信息即可:

2.运行split_label.py
这个程序是为了将框切分成宽为16的矩形。
在utils / prepare / split_label.py中修改DATA_FOLDER和OUTPUT。然后在根目录下运行split_label.py

DATA_FOLDER文件摆放情况如图:
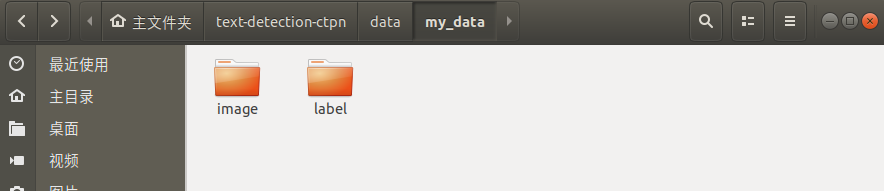
image文件夹中存放的是图片,label文件夹中存放的是.txt格式的标签。
在这一步我遇到了两个问题记录一下:
1.一直报错Error processing
单步调试后发现在
with open(gt_path, 'r') as f:
lines = f.readlines()
这里无法正常读入,是因为在
gt_path = os.path.join(DATA_FOLDER, "label", 'gt_' + bfn + '.txt')
img_path = os.path.join(DATA_FOLDER, "image", im_fn)
中因为’gt_’,对.txt的标签数据命名加个个gt_000001.txt ,导致无法找到与之对应的000001.jpg图片。将’gt_’删除即可。
2.ImportError: No module named utils.rpn_msr.anchor_target_layer

这个问题我试了很多方法,最后发现原来是基于anaconda里面安装了一个名字为utils的库,导致程序在调用时,没有调用CTPN中的utils文件夹。解决方法是:
1.卸载utils库,在终端中直接输入pip uninstall utils即可(不知道会不会对anancoda产生影响,但确实有效),utils库也可以安装回去。
2.修改utils文件夹以及所有代码中utils的名字(工作量有点大)
三,开始训练
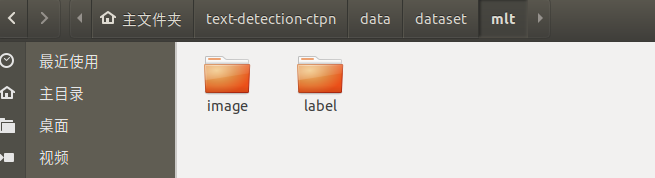
将生成的数据放入data / dataset /中,如图:
接下来开始训练即可。