few-shot: 通过较少的学习样本,实现比较好的识别能力。
技术迭代:

基于bert的标准微调范式在小样本效果比较差。

为什么小样本容易过拟合?
因为预训练有大量的参数,如果样本非常少,那么训练参数量就会远远高于样本量,造成过拟合!
PET算法:
通过人为修改模板,把分类标签转化成完形填空。

通过引入一段话,把分类标签带入到训练样本中,实现完形填空的功能。
PET的缺点,写的不同的模板会影响效果。

P-Tuning模型
基于PET使用伪模板。

一般而言,p-tuing效果优于PET范式。但是对于标签特别多,以及蕴含任务需要去理解的时候,p-tuing任务的效果不是很好。蕴含任务就是无法把标签变成完形填空的形式。

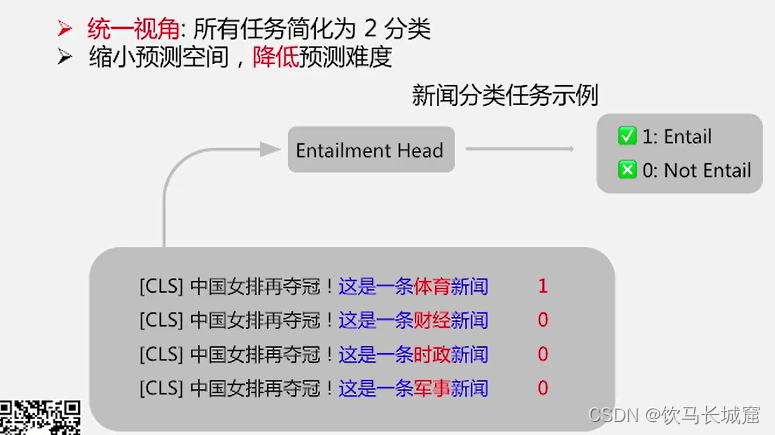
EFL : 把分类任务转换成二分类蕴含任务。
关于paddle-NLP的小样本增强技术;
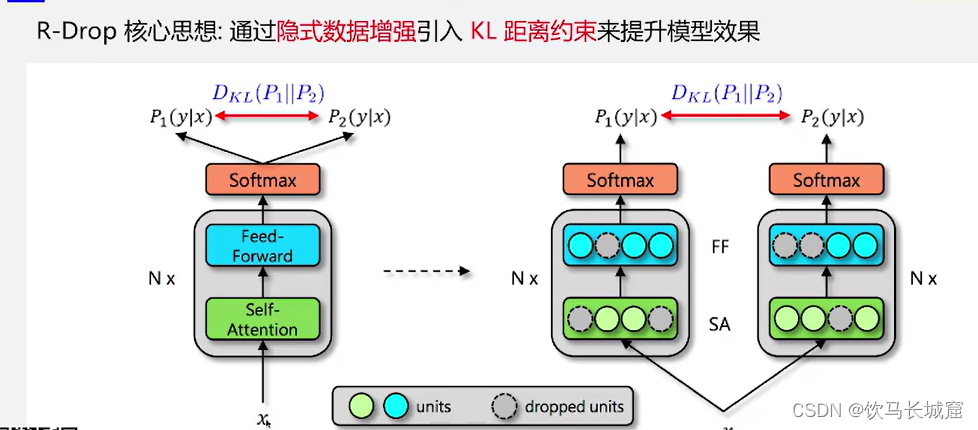
R-drop:

Rdop做的是隐式数据增强,把一句话,变成两个接近的token。