操作系统配置:
1、为每台机器添加Livy用户,也可通过LDAP添加
|
|
2、将livy文件夹所属用户改为livy
|
|
3、创建livy的log目录及run目录
|
|
4、在KDC节点创建livy的Kerberos信息,并将生成好的keytab文件拷贝到livy的配置文件夹下
|
|
Livy配置:
修改livy.conf,配置如下属性:
|
|
修改HDFS配置:
|
|
启停livy:
|
|
Griffin 配置:
1、修改application.properties如下:
|
|
2、修改sparkProperties.json
|
3、修改env\env_batch.json
|
|
4、修改env_streaming.json
|
|
5、修改pom.xml
|
|
6、修改HiveMetaStoreProxy.java类的initHiveMetastoreClient()方法
|
7、修改HiveMetaStoreServiceJdbcImpl.java中的init()方法
|
8、我们的ES是7.*,因此需要修改:
MetricStoreImpl.java
|
ElasticSearchSink.scala
|
9、关于正则的校验,前后端不匹配,前端把正则表达式写死了,不知道这怎么开源出来的,这么多问题。
修改\griffin\ui\angular\src\app\measure\create-measure\pr\pr.component.spec.ts
|
10、修改\griffin\ui\angular\dist\main.bundle.js
|
11、在mysql建表:(官方给的sql里少建了一张表DATACONNECTOR,气人不?)
|
|
12、在idea里的terminal里执行如下maven命令进行编译打包:
|
如果有包下载不下来,就去浏览器去maven下载手动install一下
13、打包完之后,将measure下面的target的measure-0.6.0.jar包上传到HDFS上,并重命名为griffin-measure.jar
我是传到了/griffin/griffin-measure.jar,注意要和前面的配置文件中写的路径一致。hive-site.xml也需要上传,还需要新建checkpoint和persist文件夹。Persist是用来存放metric数据的。
|
|
14、至此griffin安装完毕。
15、启动:
可以直接在IDEA中启动进行调试,在服务器的话则是去/bigdata/griffin-0.6.0/service/target
nohup java -jar service-0.6.0.jar > out.log 2>&1 &
16、新建measure和job:
Accuracy是指测试 源表和目标表的准确率;
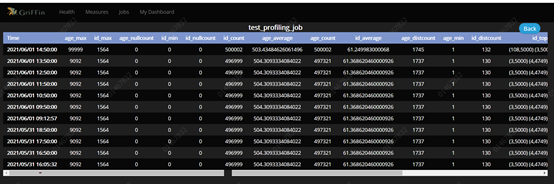
Data Profiling是指按一定的规则进行统计的,比如Null的数量、平均值、最大值、去重后的数量、符合正则的数量等。
Publish没发现有啥用;最后一个是自定义,没测试。
17、

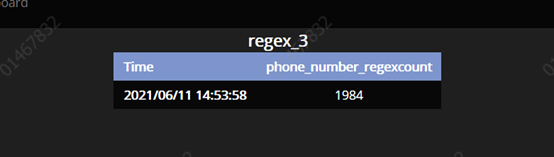
18、简单的正则验证一下手机号吧:

19、将measure做成job定时调度(我是每个measure都做了对应的job):

20、运行结果展示:
正则的:
准确率的:

数据统计的: