1. 项目介绍
dataCollection项目在kettle基础开发的可视化任务调度系统,提供简单易用的操作界面,降低用户使用crontab调度的学习成本,缩短任务配置时间,避免配置过程中出错。系统对接webSpoon,支持在线编辑kettle脚本,通过数据整合功能,可同步资源库中已有的脚本,用户在创建完脚本之后,可通过系统任务管理,创建数据同步任务。
2. 特性
1、在线编辑kettle脚本,
webSpoon download
提取码: cffa
2、资源库管理,避免脚本本地存储,版本错乱、丢失等问题;
3、通过Web构建kettle采集任务;
4、在线查看kettle执行结果及日志,便于排查采集问题;
5、任务告警,系统支持邮件告警,所有异常信息即使掌握;
3. 部署WEB端kettle
1)将webSpoon.zip压缩包上传到linux根目录

2)创建spoon文件夹
mkdir spoon
3)将webSpoon.zip解压到spoon文件夹下
mv webSpoon.zip spoon
cd spoon
unzip webSpoon.zip
解压完成后查看目录
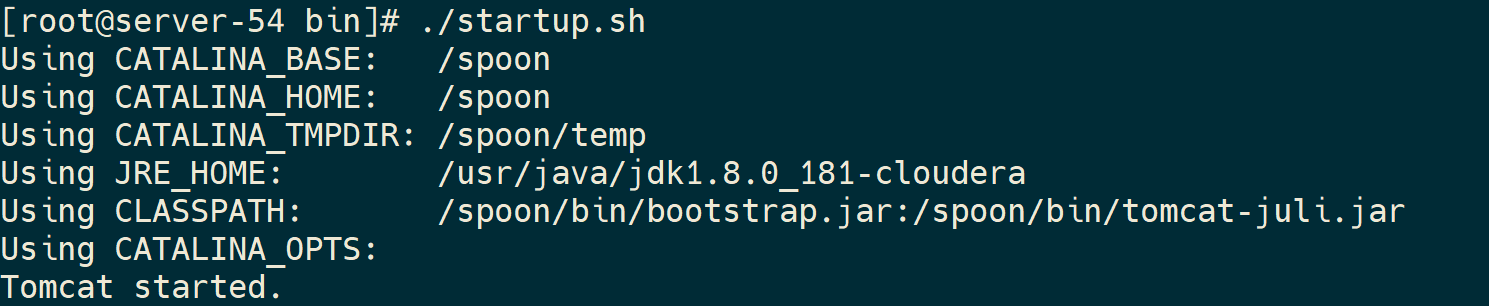
4)启动kettle web端
cd bin/
./startup.sh
注意
: ./startup.sh后如果提示权限不够, 需要修改权限:
chmod -R 777 /spoon
./startup.sh
出现这个界面则启动成功
5)在windows上访问kettle
在浏览器上输入:
http://ip:8080/spoon/spoon
(ip为linux的ip地址)
4. 部署数据采集平台
4.1 安装jdk1.8
自己安装,这里就不介绍了···
4.2 MySQL配置
1)下载部署包(自己编译也行),上传到/java 目录下

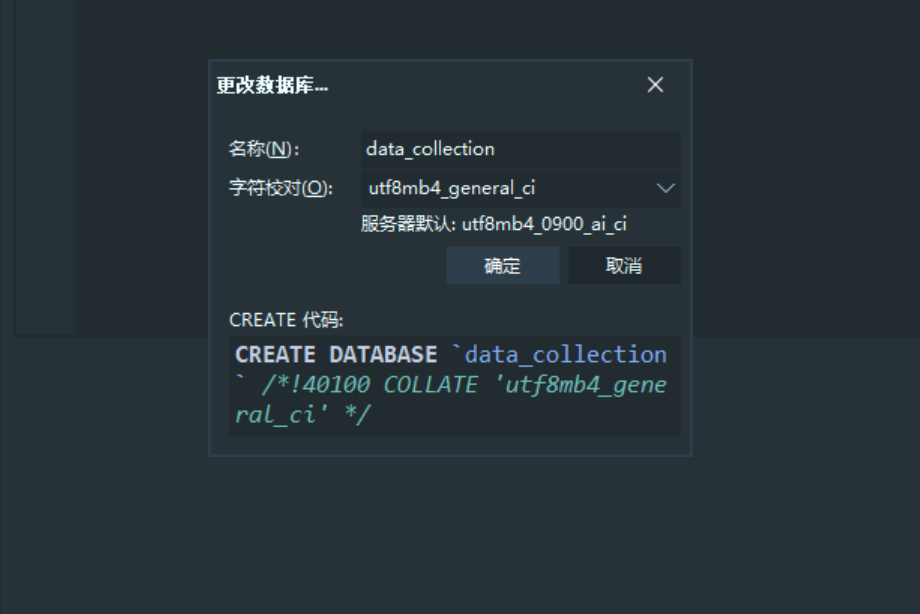
2)创建数据库data_collection
3)执行SQL文件

- 导入dataCollection平台数据库(./sql/mysql/data_collection_20220417_130951.sql)
- 导入数据库资源库脚本(./sql/mysql/kettle_rep_20220417_130548.sql)
4)解决Linux中MySQL表名区别大小写的问题
-
切到MySQL配置文件
挂载
的目录
cd /mysql/conf/
- 编辑 my.cnf 配置文件
vim my.cnf
在 [mysqld] 下面添加: lower_case_table_names=1
即可忽略表名大小写

4.3 修改源码配置
1)修改kettle配置文件
编辑 application-kettle.yml
kettle:
log-file-path: /apps/logs/${spring.application.name}/run-logs
encoding: utf-8
upload-path: /apps/var/kettle-script-file
kettle-home: /apps/var/file-rep
kettlePluginPackages: /home/ali/data/plugins
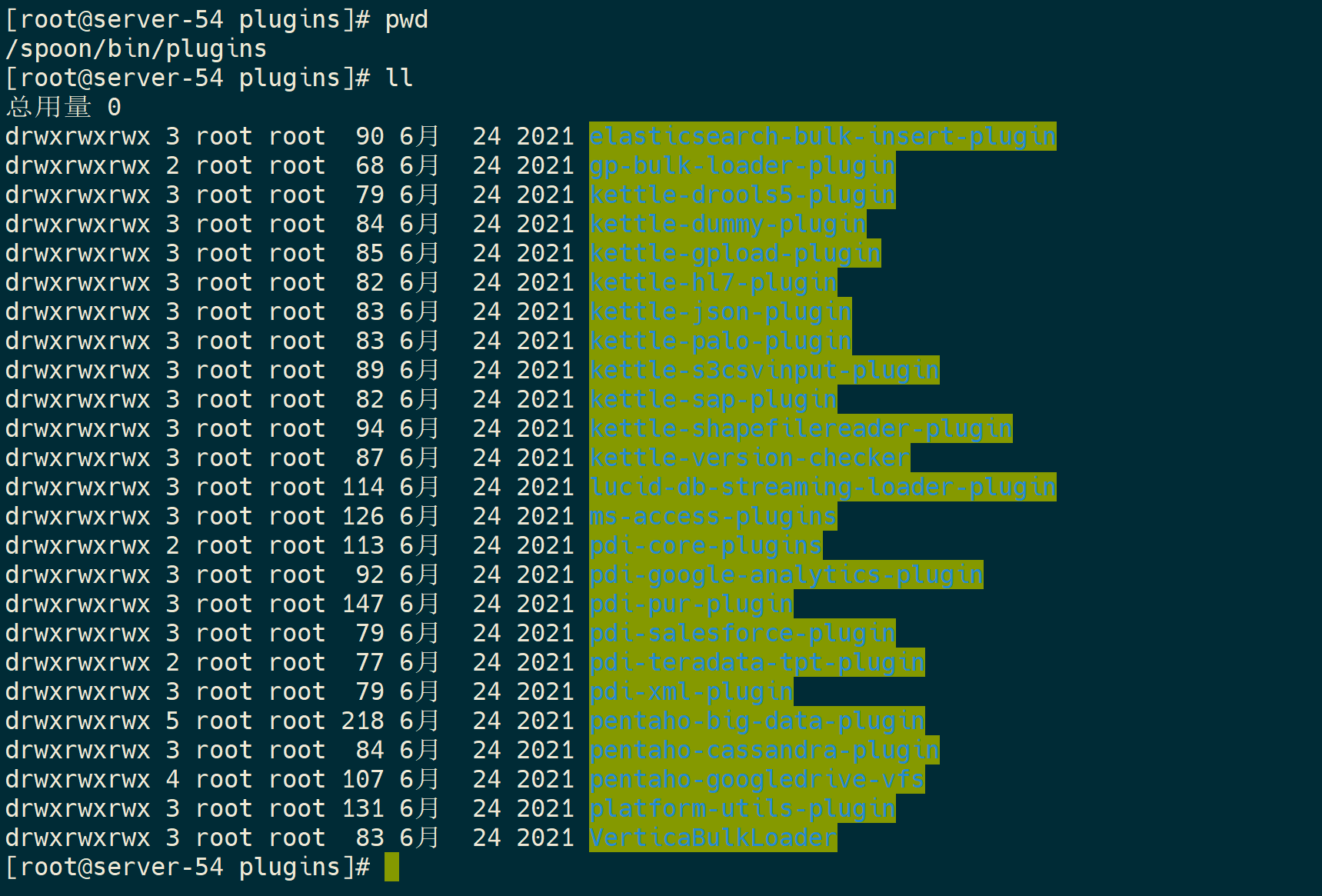
2)上传kettle插件
将kettle插件包plugins上传到
/home/ali/data/
下
3)配置webSpoon
在 application.yml配置文件中配置 kettle的url:
spoon:
url: 172.30.106.54:8080/spoon/spoon
4)配置数据源
application-mysql.yml
spring:
datasource: # 数据库链接
url: jdbc:mysql://172.30.106.54:3306/data_collection?useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=GMT%2B8
username: root
password: root #数据库名、用户名和密码改为自己的
driver-class-name: org.gjt.mm.mysql.Driver
5)运行jar包
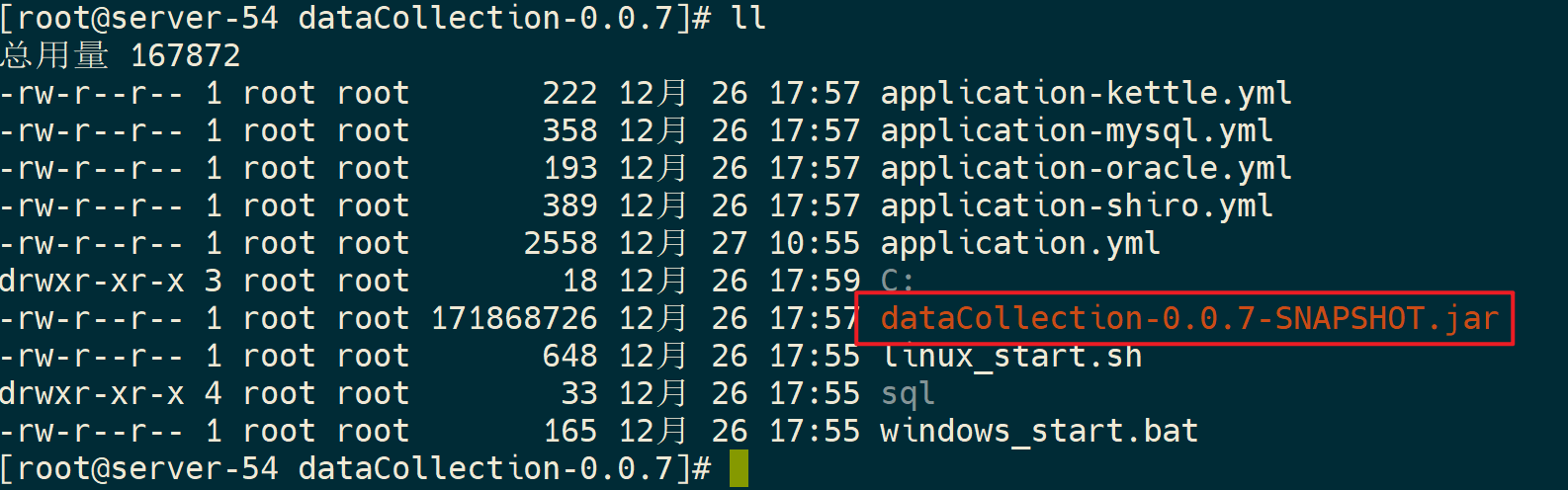
java -jar dataCollection-0.0.7-SNAPSHOT.jar
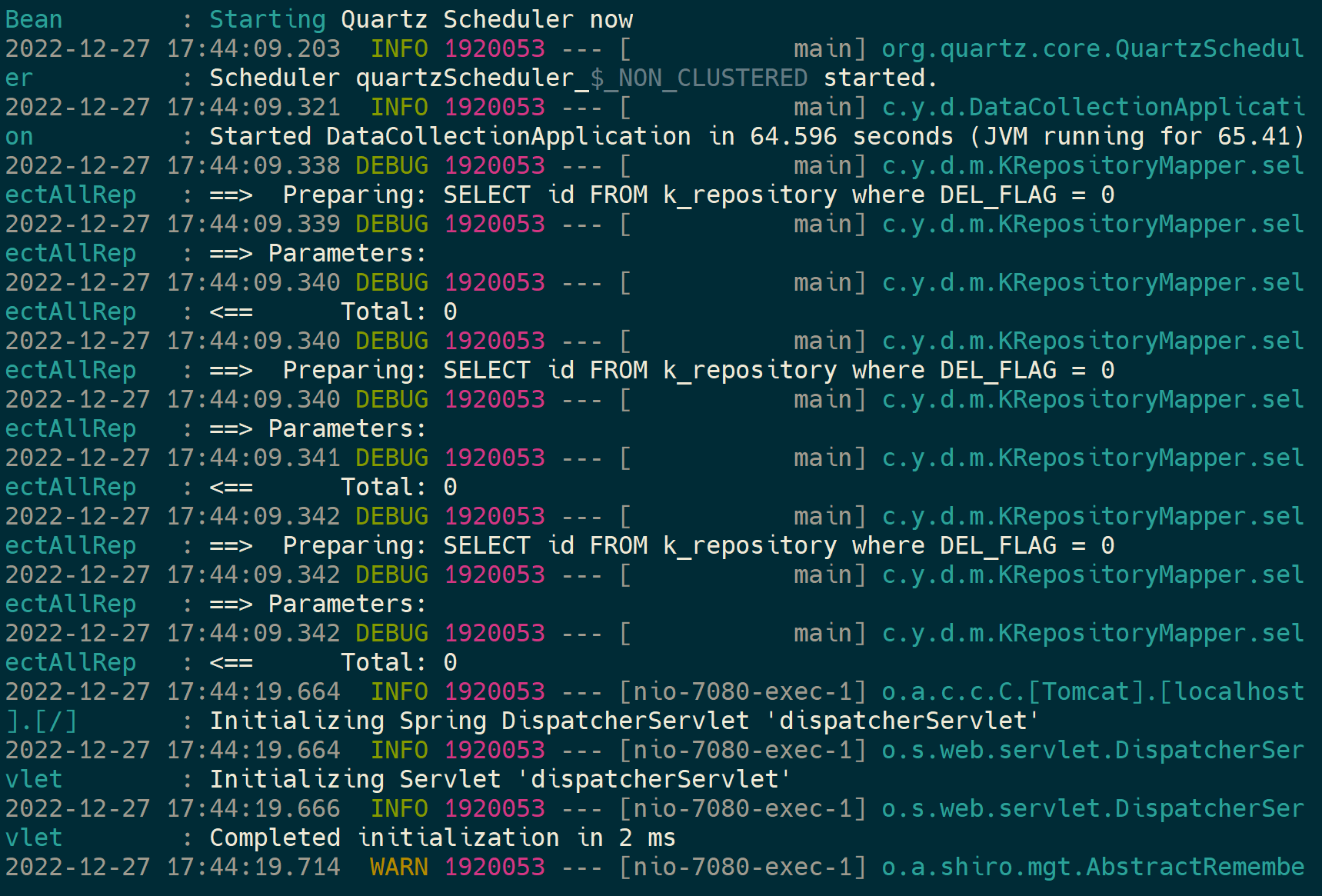
访问:
http://172.30.106.54:7080/
出现以下界面 , 启动成功
5. 数据采集平台使用说明
5.1 启动和登录
- 启动
根据以上步骤进行启动
kettle
和
数据采集平台
- 登录
默认账号密码都为
admin
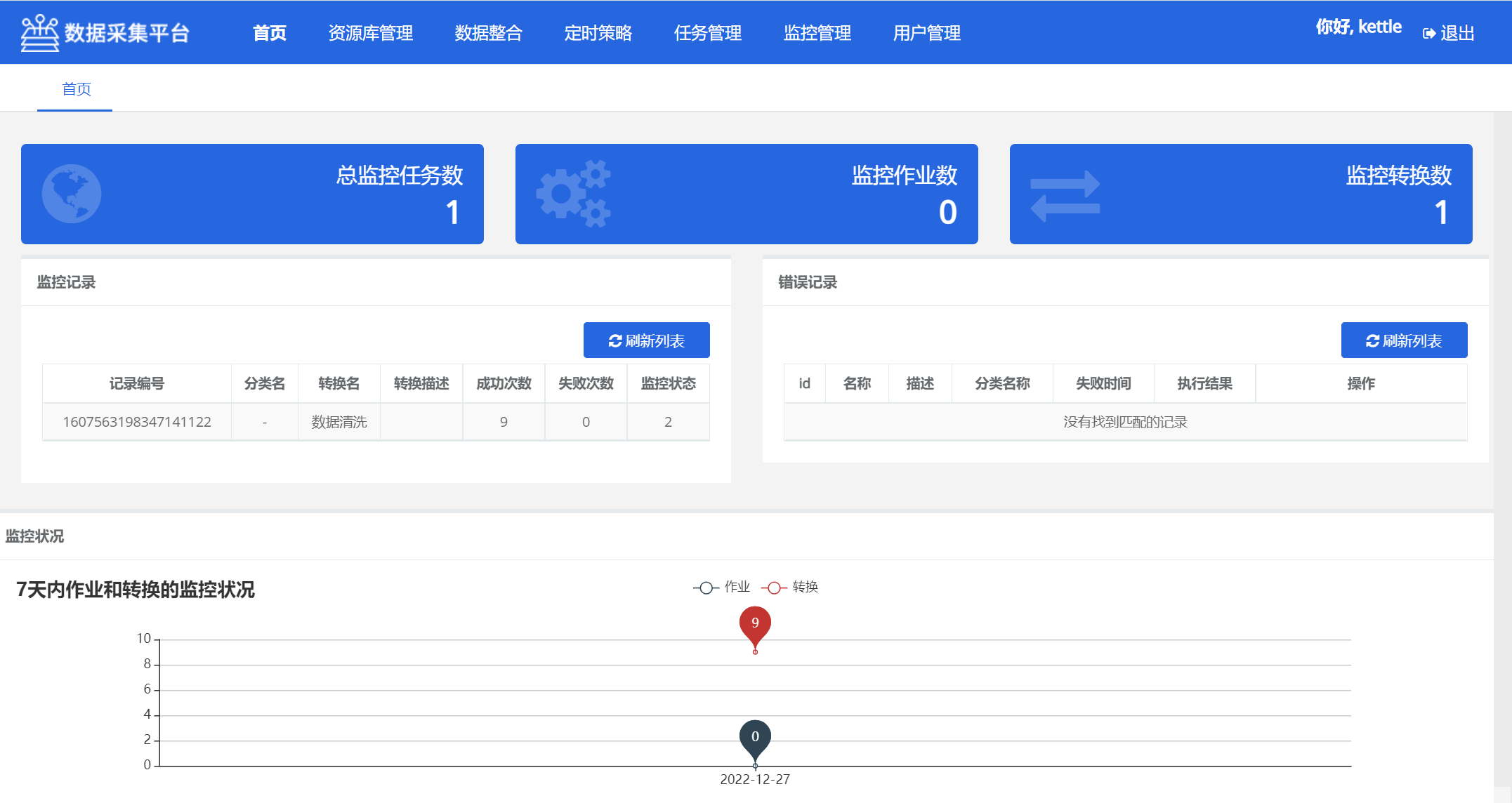
5.2 首页
首页为任务的监控界面
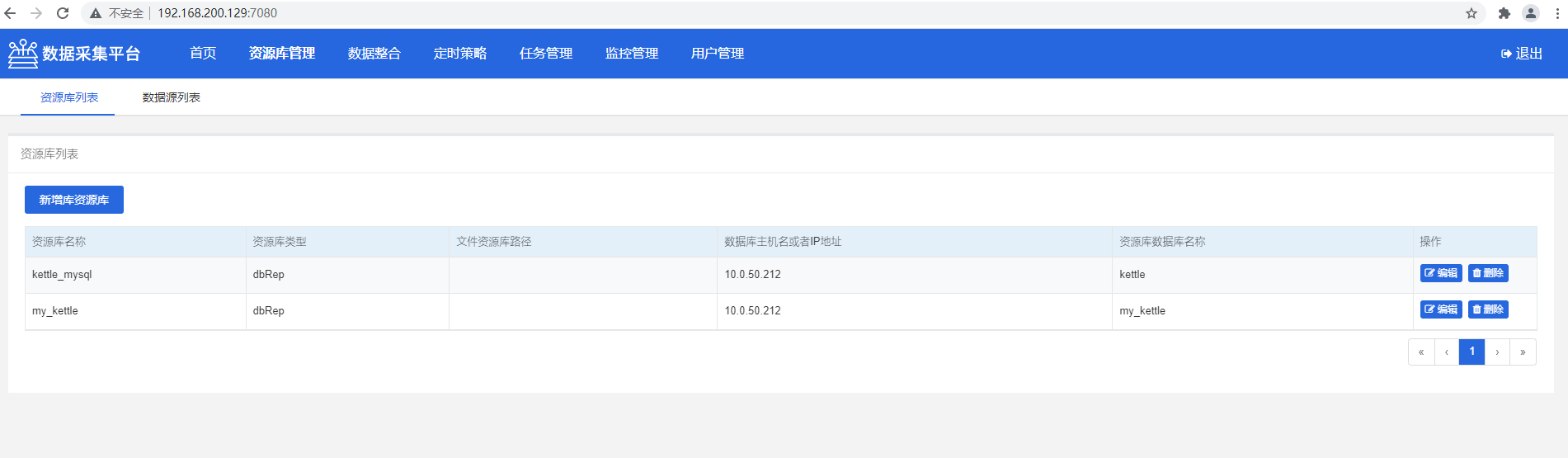
5.3 资源管理库
1)资源库列表
可以查看已经连接过的资源库列表
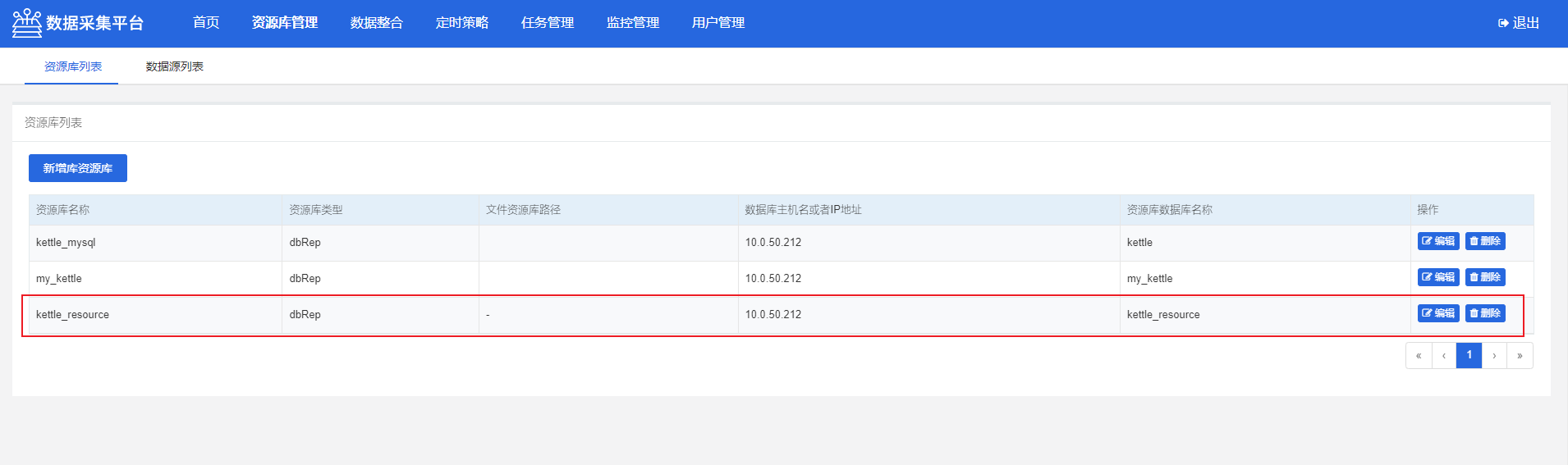
2)新增资源库
点击新增库资源库

点击保存, 新建完成, 即可在列表中查看到刚才新建的数据库资源库
5.4 数据整合
1)资源库列表
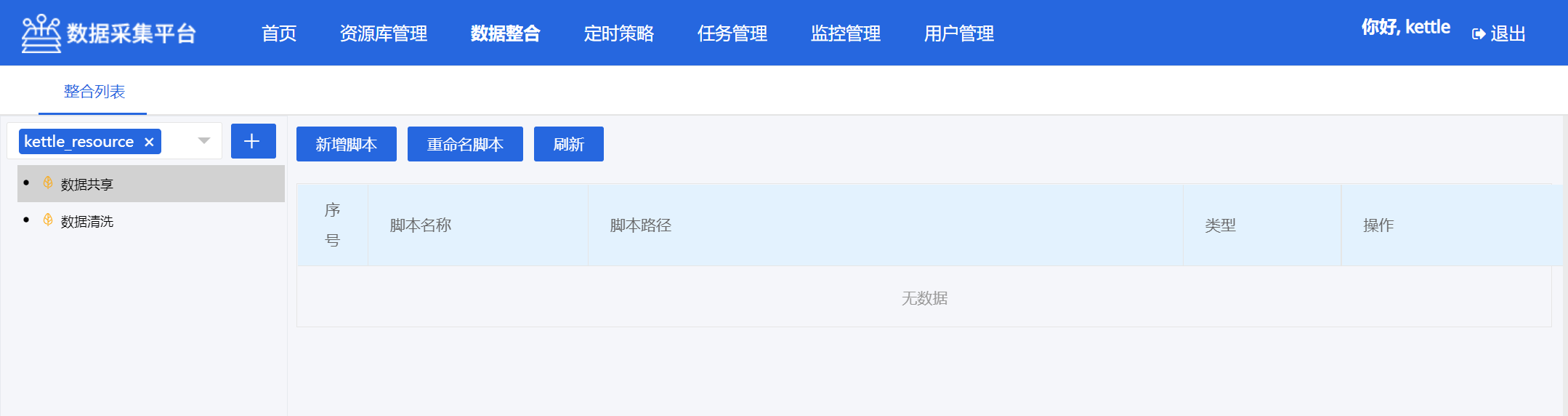
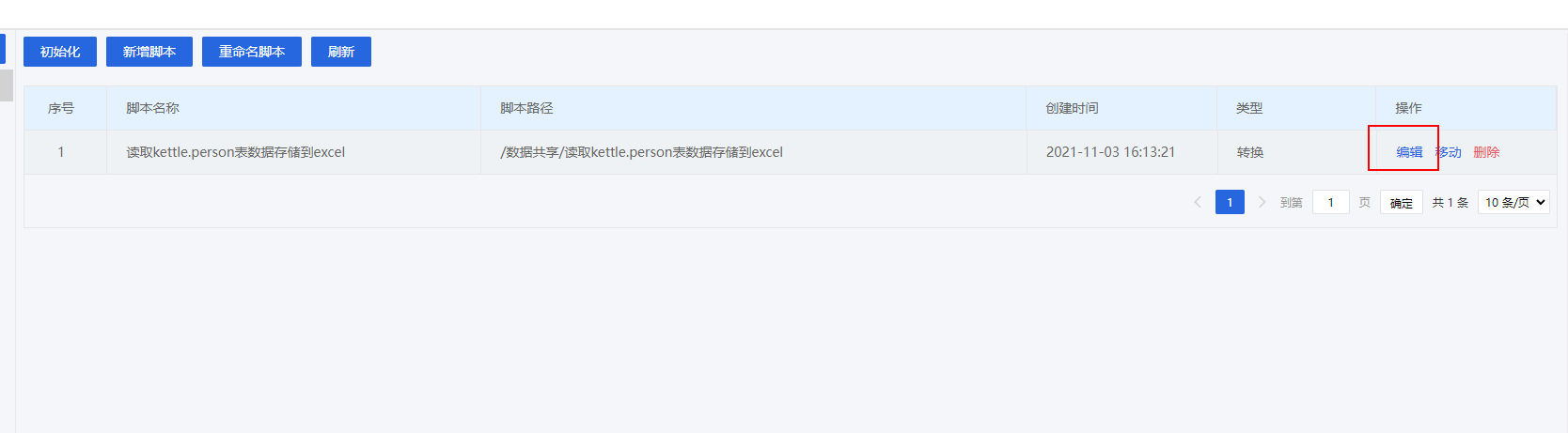
2)新增一个脚本
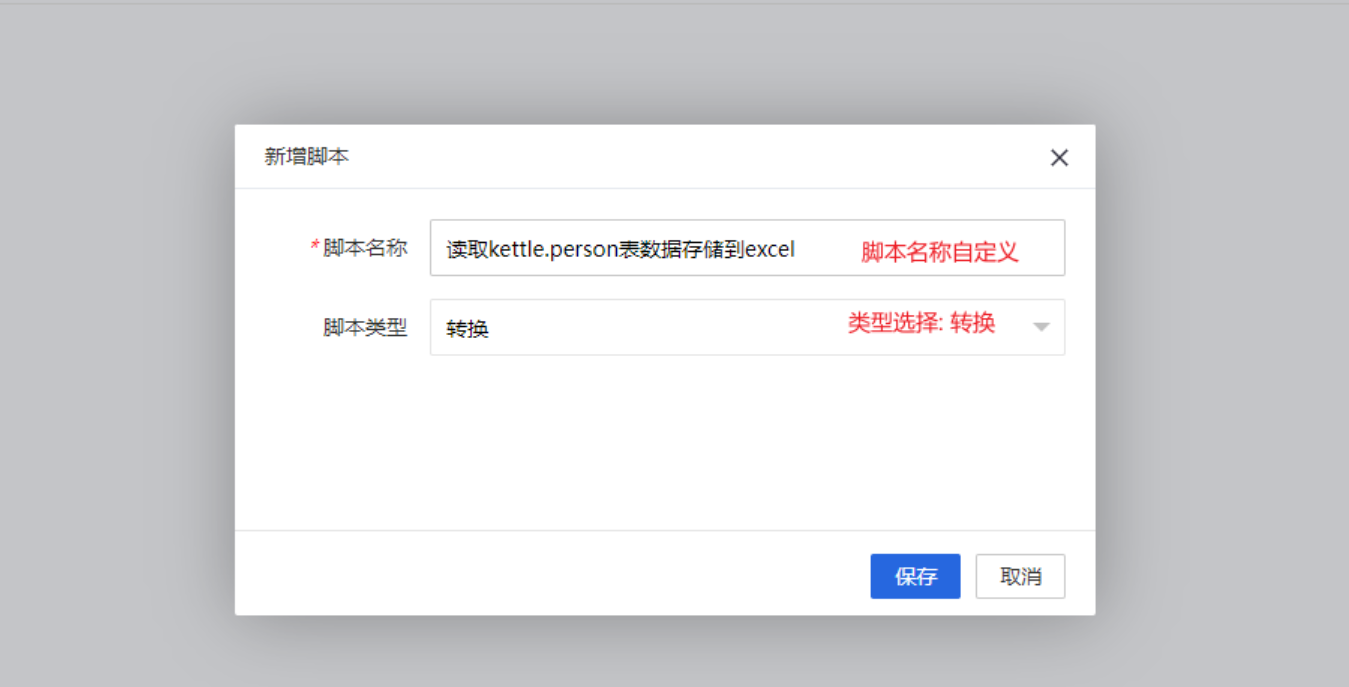
点击
保存
, 会跳转到
kettle web端界面
如果是新建的数据库资源库
, 第一次新增脚本时需要在kettle界面
连接该数据库资源库
, 后续添加脚本则不需要
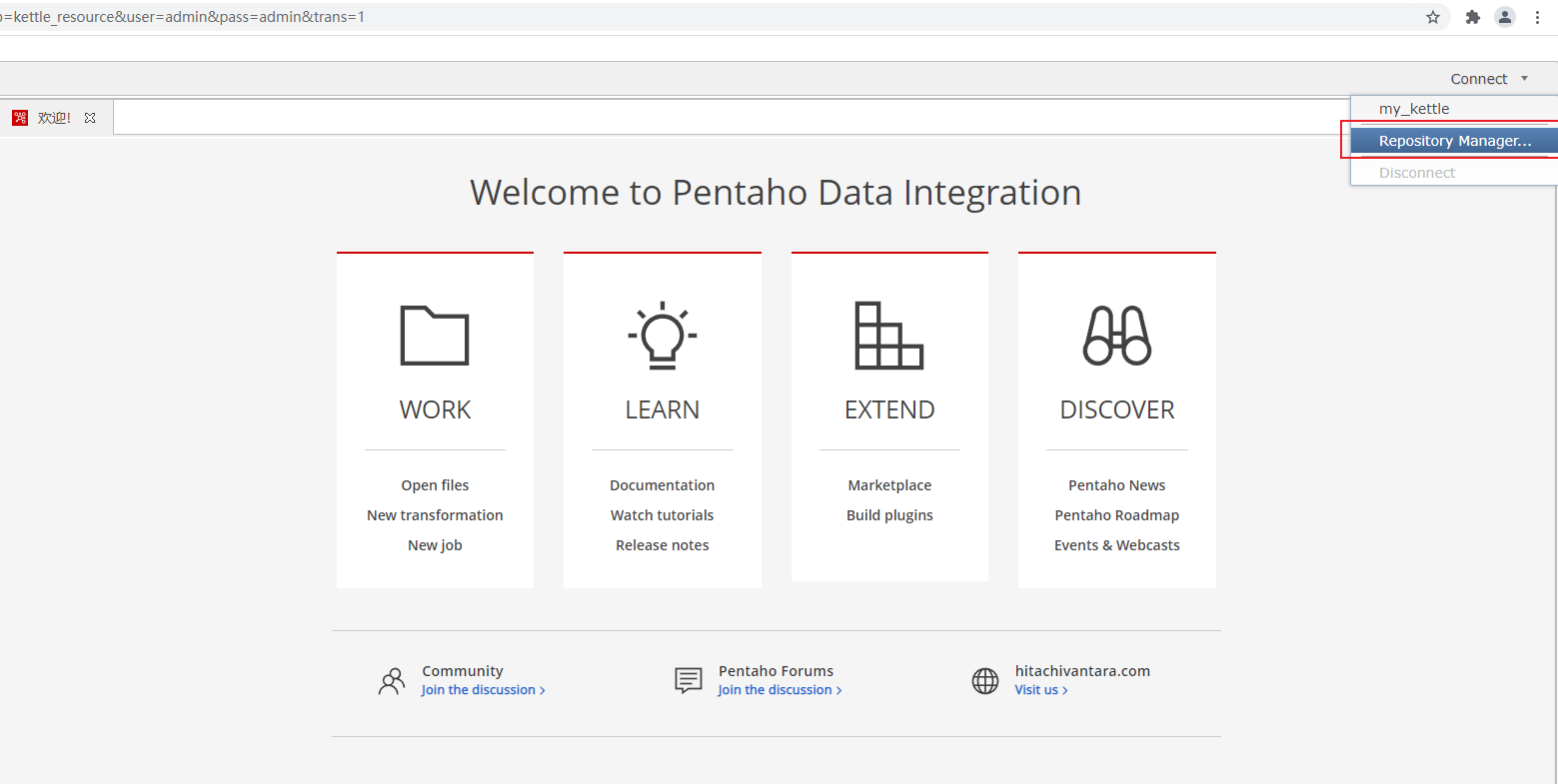
步骤:
(1) 点击右上角的
Connect
选择
Repository Manager
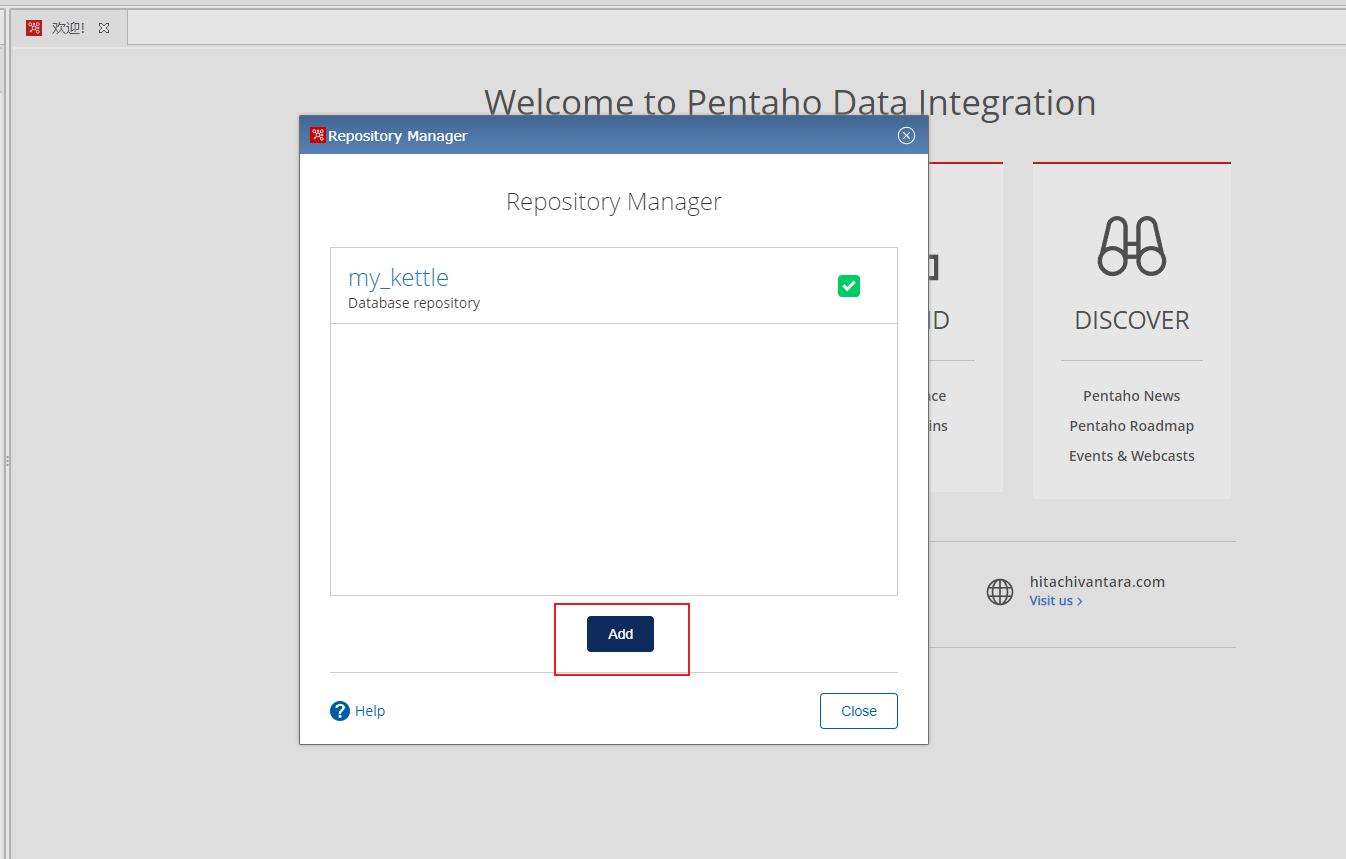
(2) 点击
Add
即: 新增资源库
(3) 点击
Other Repositories
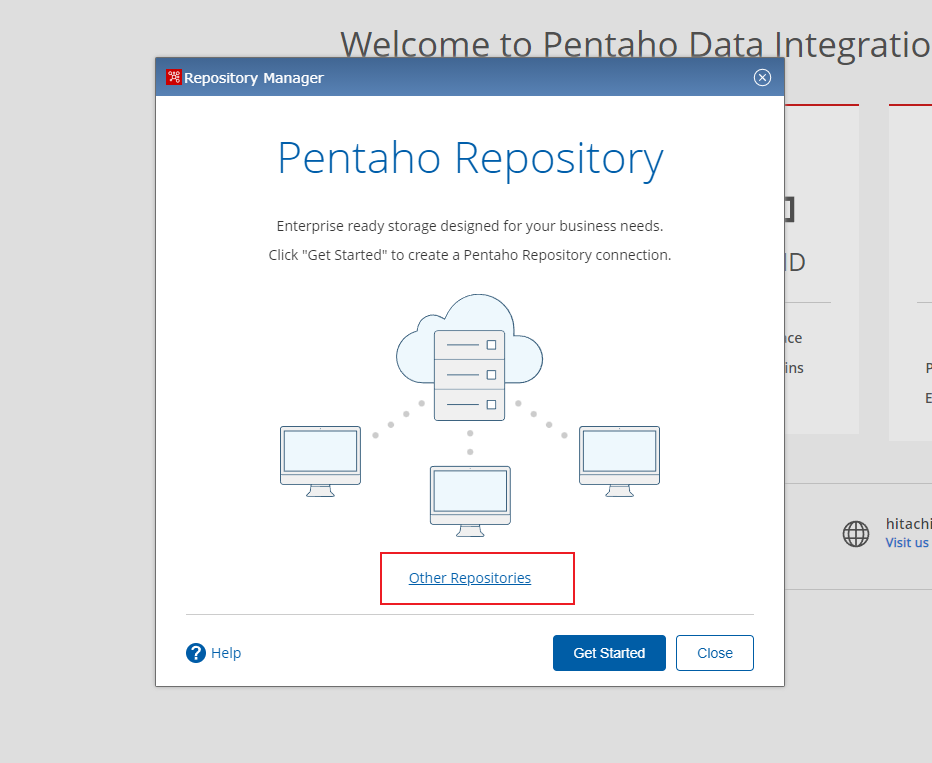
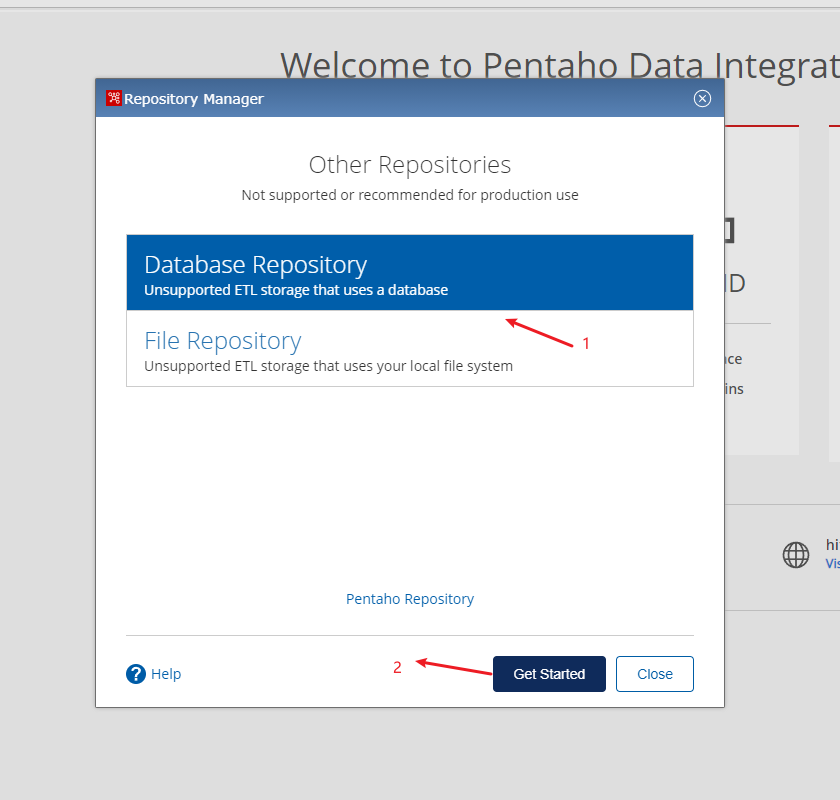
(4) 选择
Database Repository
, 然后点击
Get Started
(5) 设置
资源库名称
(
资源库名称
需要和
新增资源库时设置的名称保持一致
)

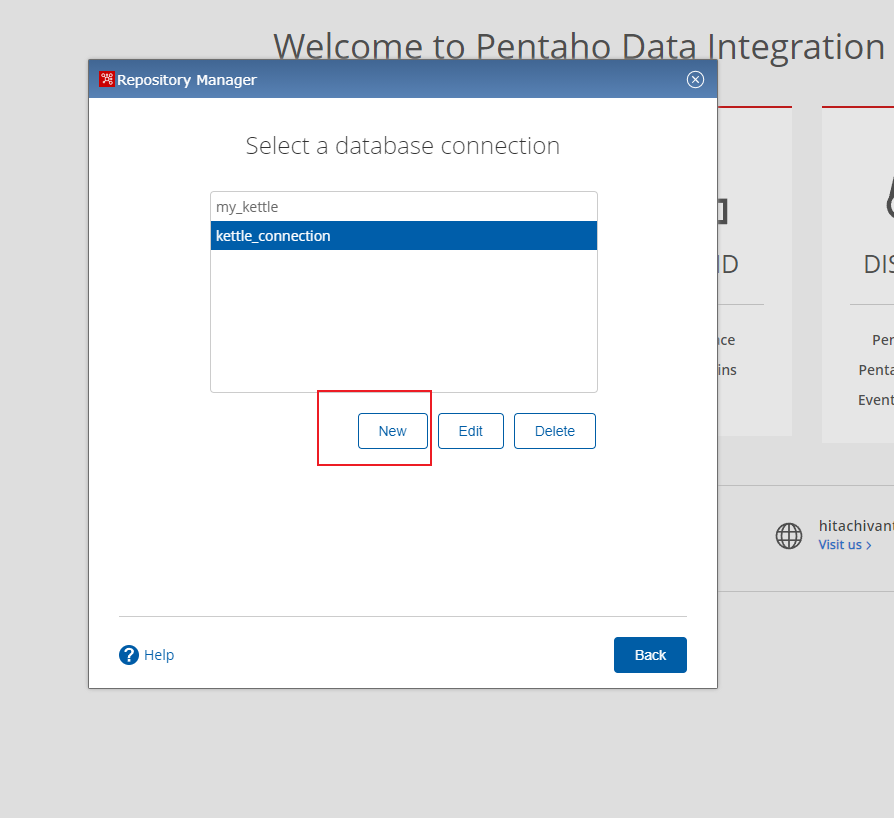
(6) 设置
资源库连接
, 点击
New
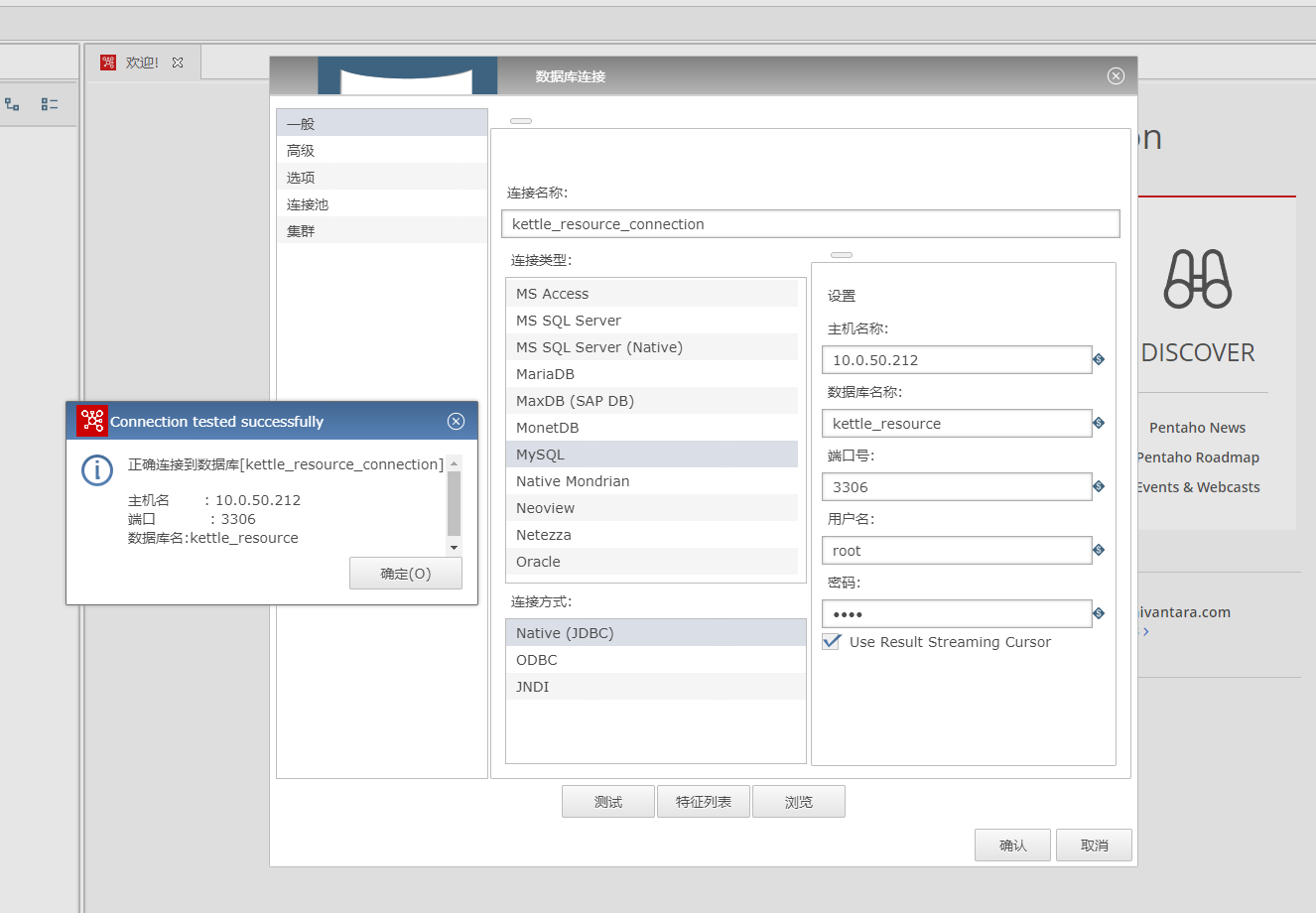
(7) 连接名称(自定义); 连接类型, 连接方式 , ip, 数据库名 端口号 用户名 密码 需要和新增资源库时保持一致, 然后点击测试
(8) 点击back返回后, 点击
Finish
完成
(9) 返回数据采集平台, 选择脚本,点击
编辑
, 即可编写脚本

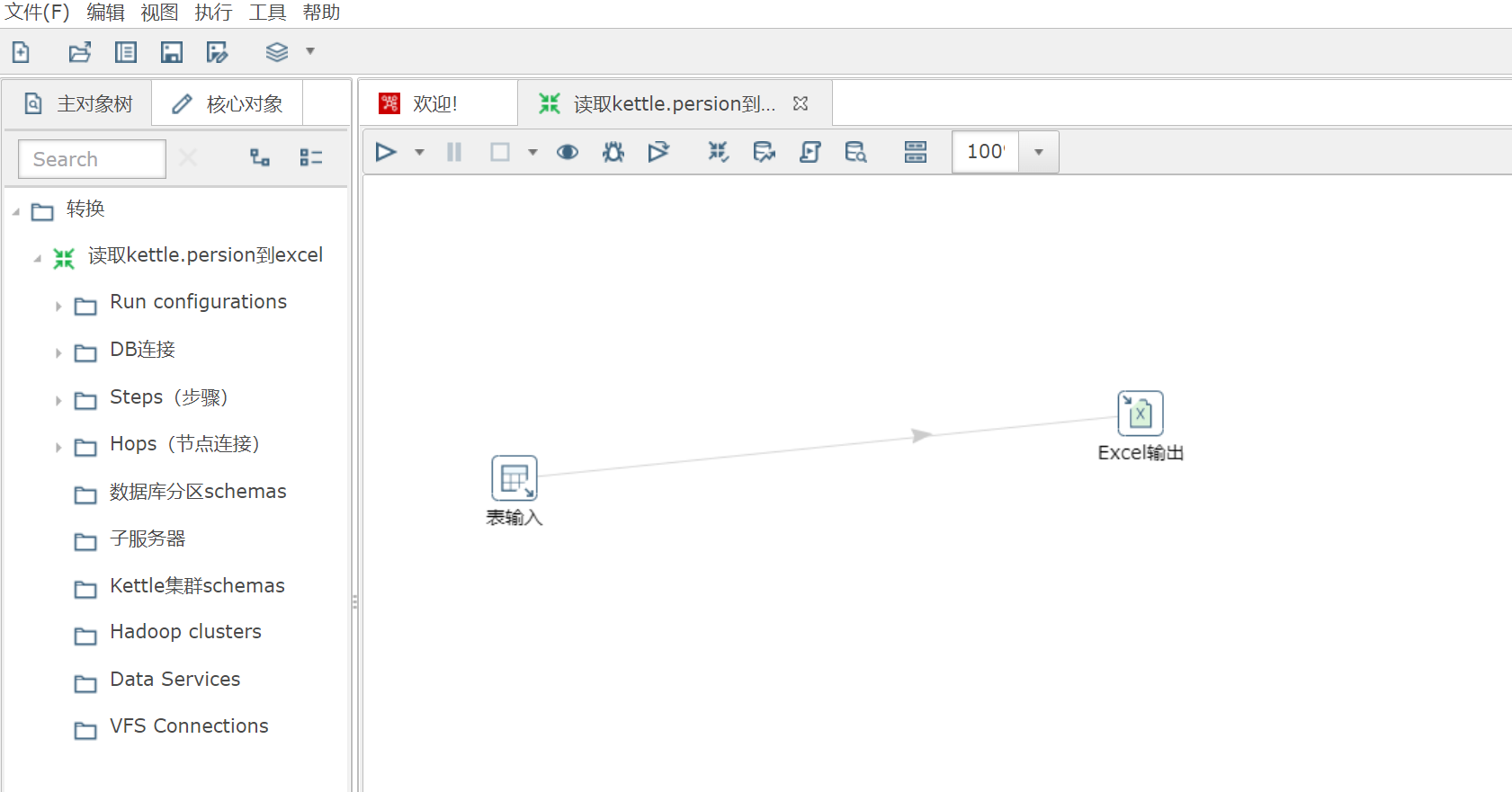
5.5 编写脚本
-
(1) 选择
表输入
和
Excel输出
, 并使用
shift + 鼠标左键
建立连接
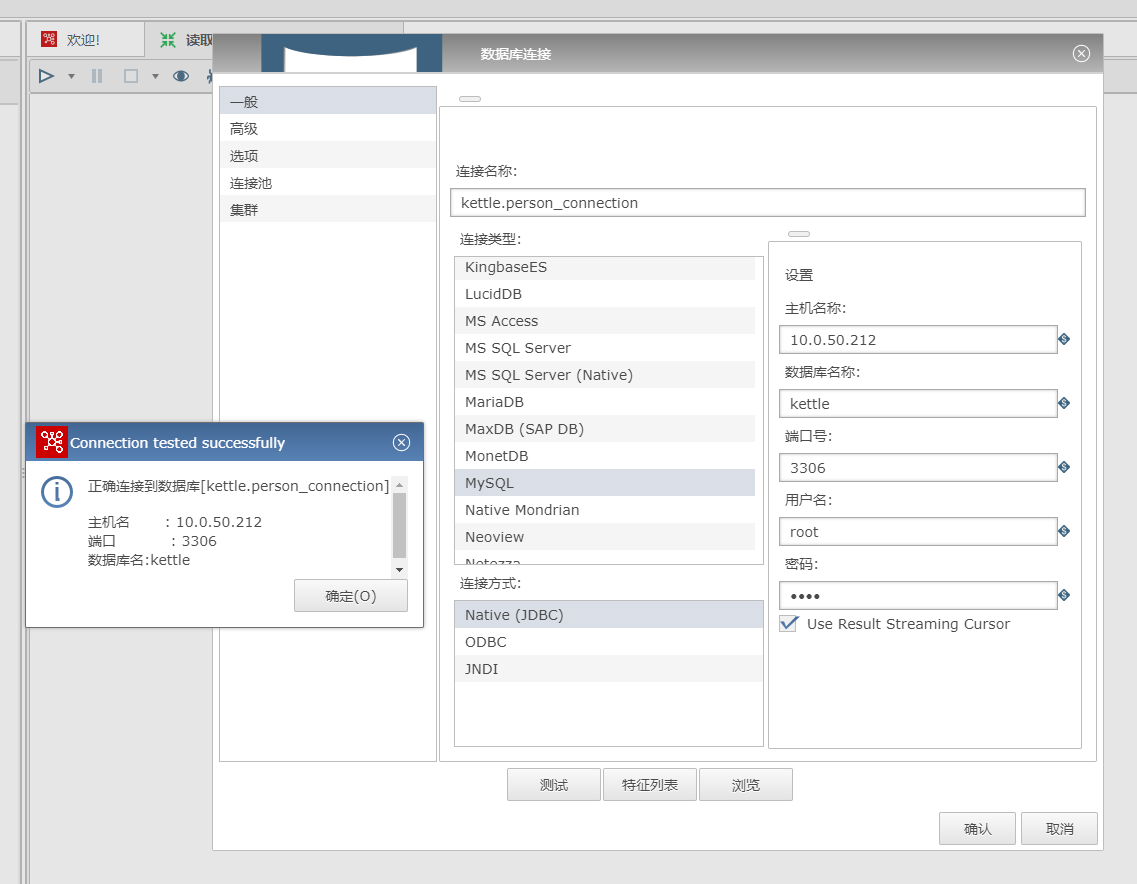
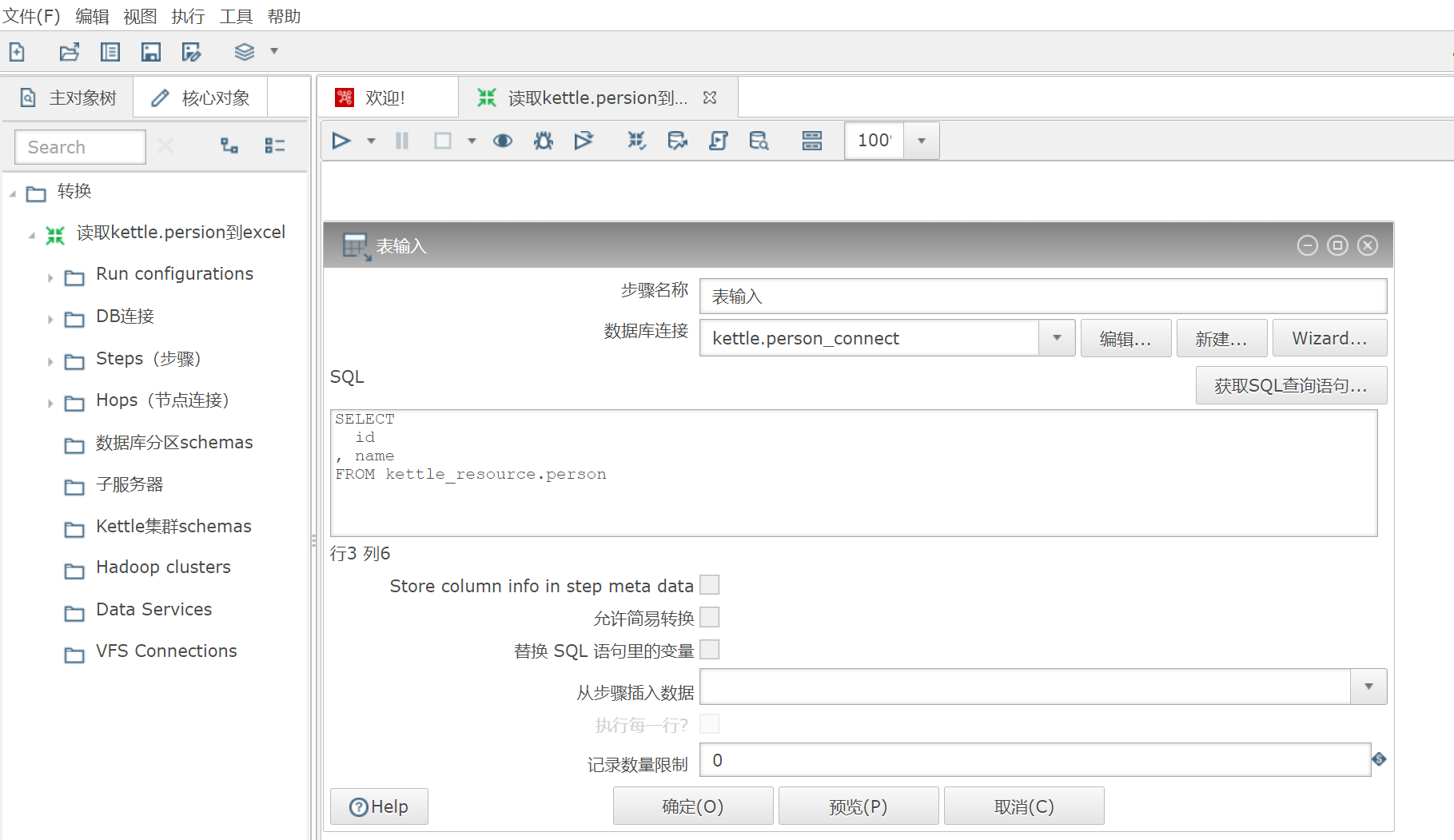
(2) 编辑
表输入
, 新建数据库连接, 选择要操作的数据库和表
(3)点击
预览
, 显示如下, 表输入设置成功,点击确定
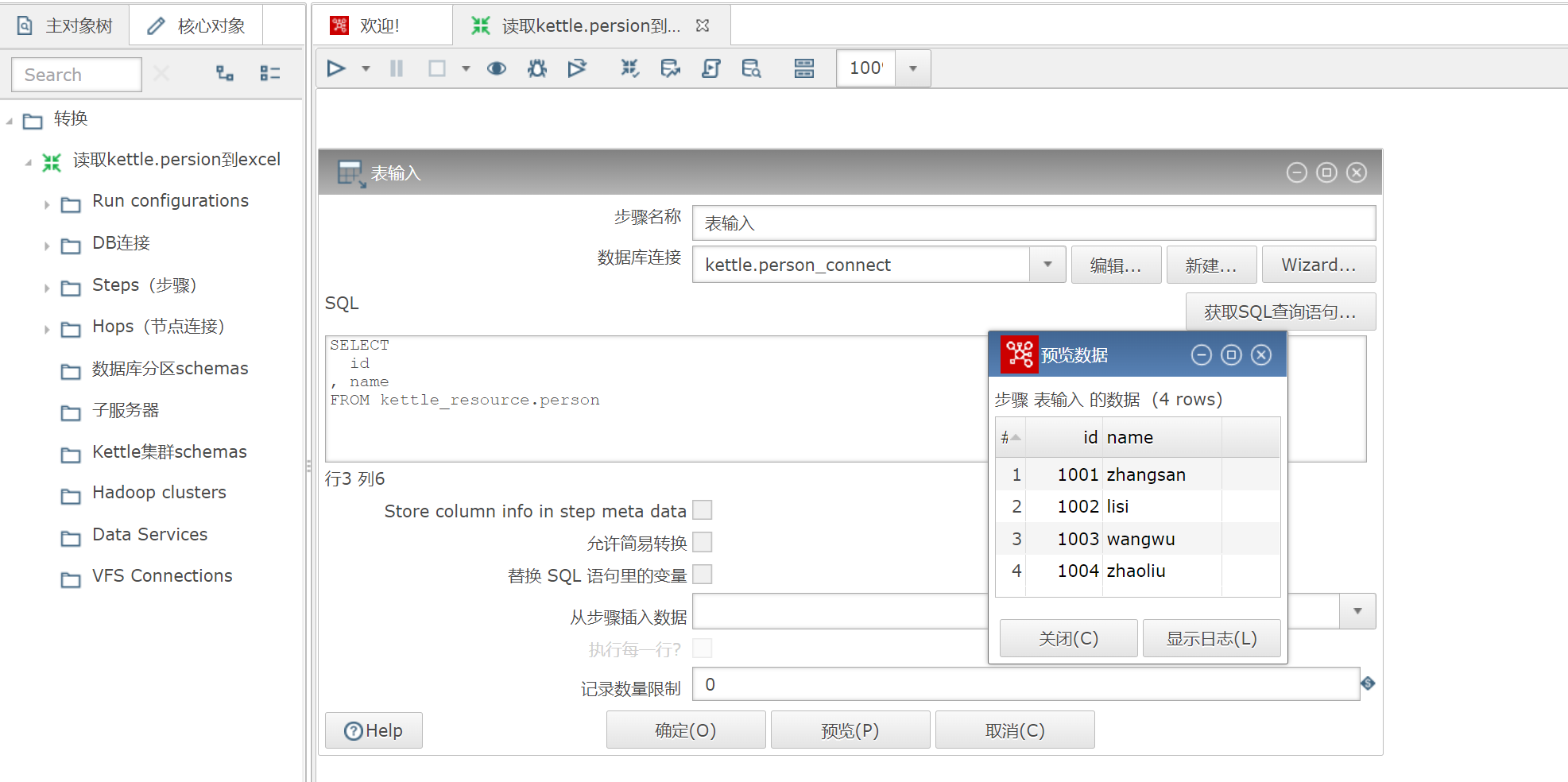
(4) 设置Excel输出
设置生成文件的路径:
/opt/data/
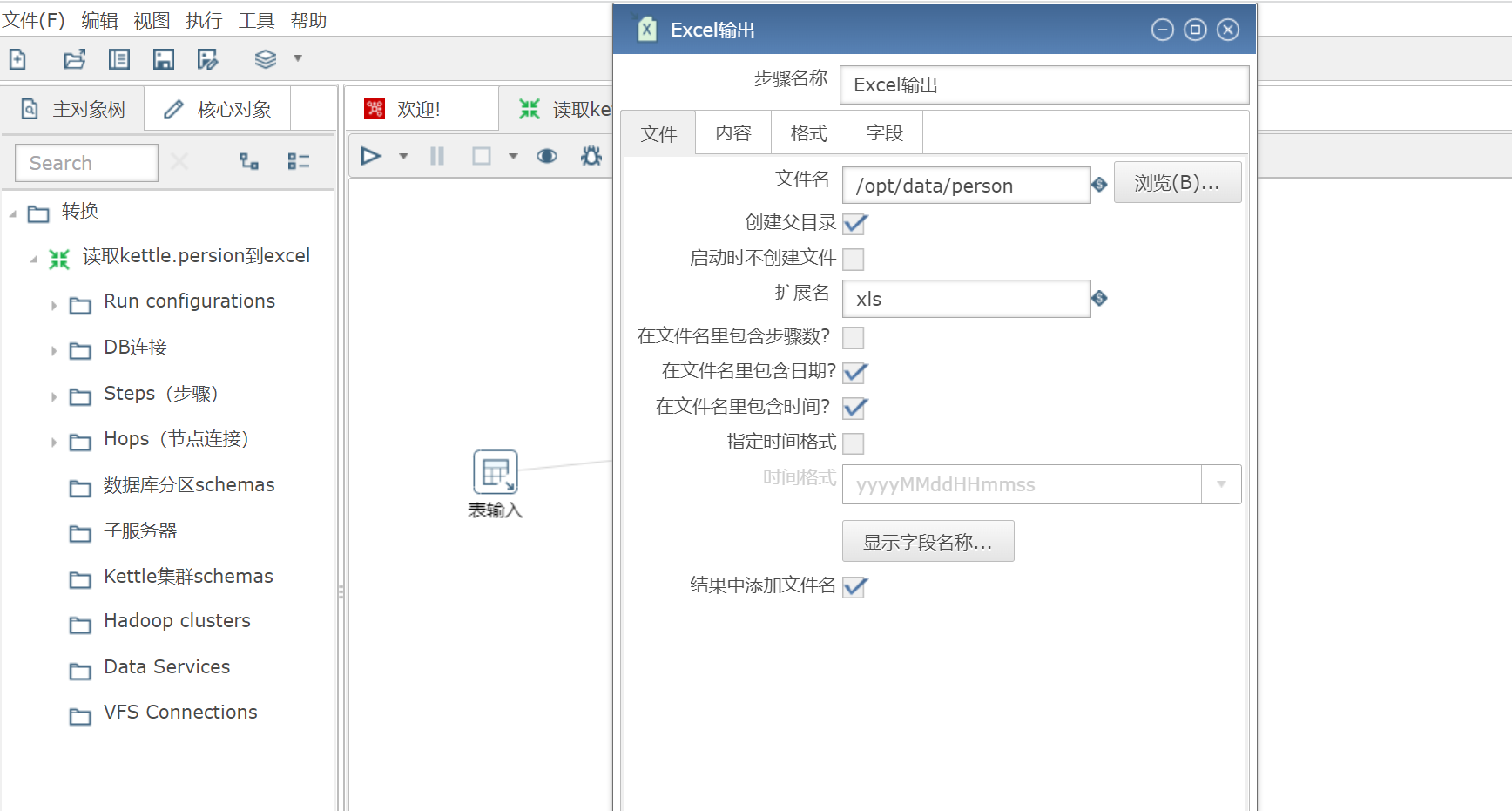
获取字段
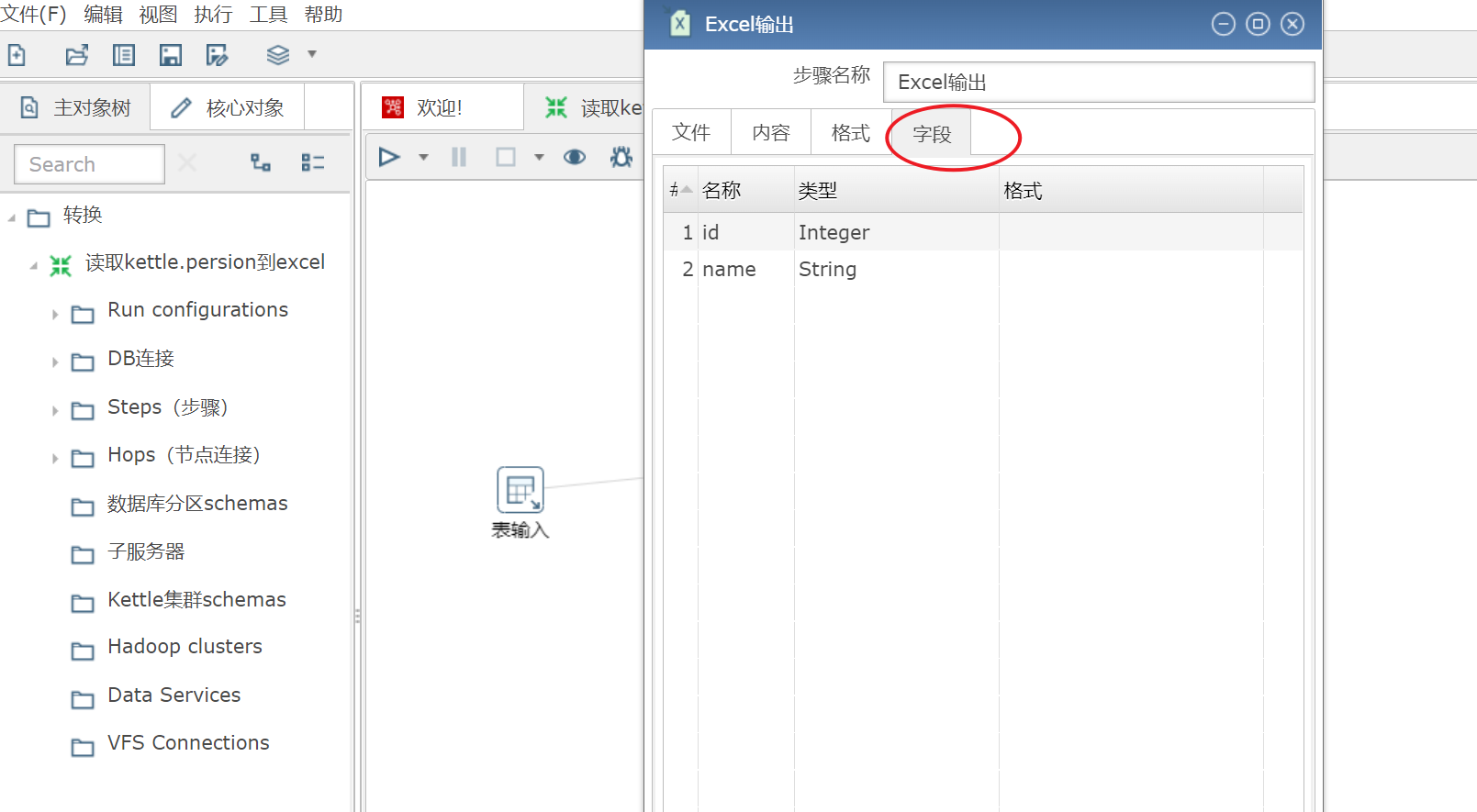
ctrl + s
进行保存
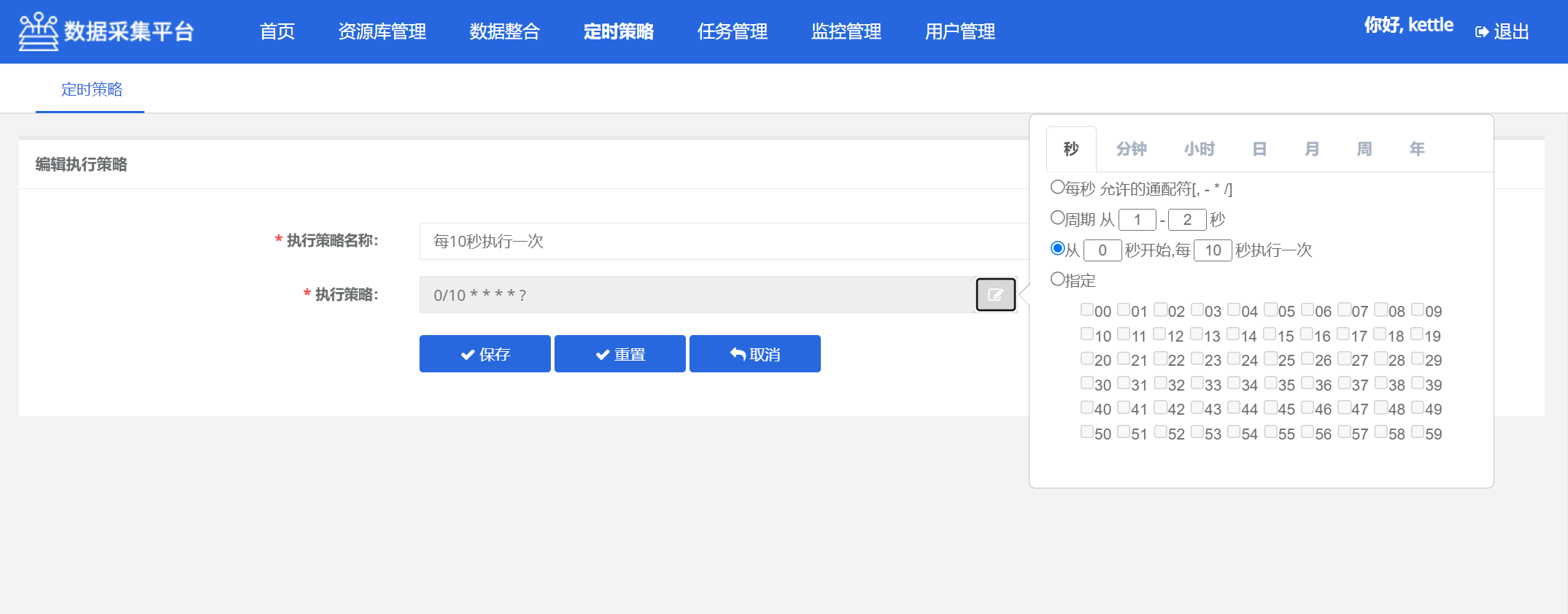
5.6 定时策略
可以设置任务定时执行的策略, 即: 多长时间执行一次
5.7 任务管理
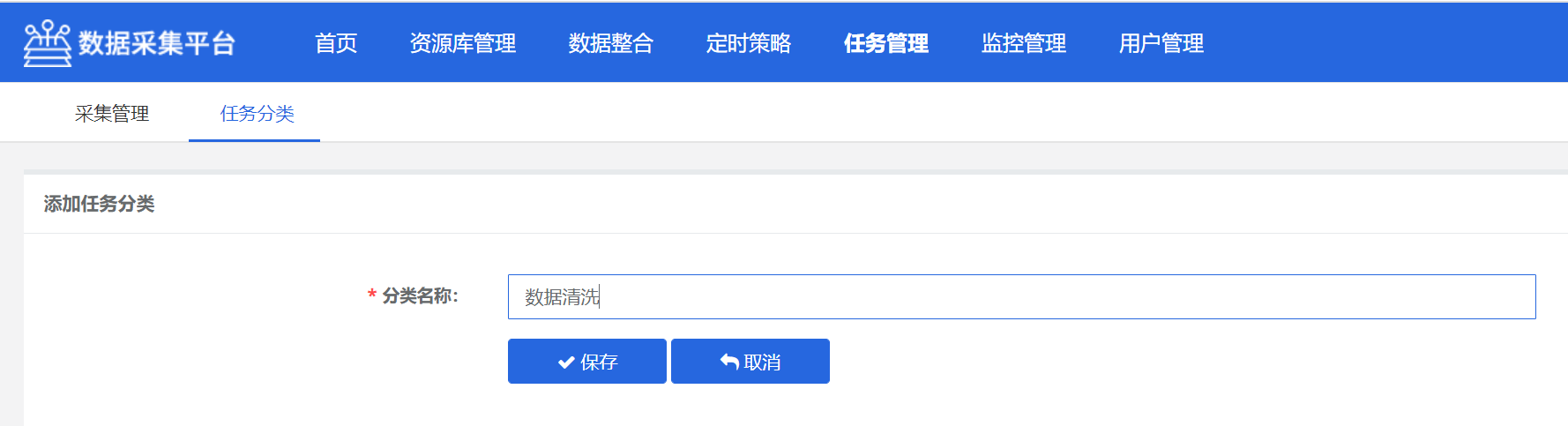
- 任务分类
可以自定义任务分类
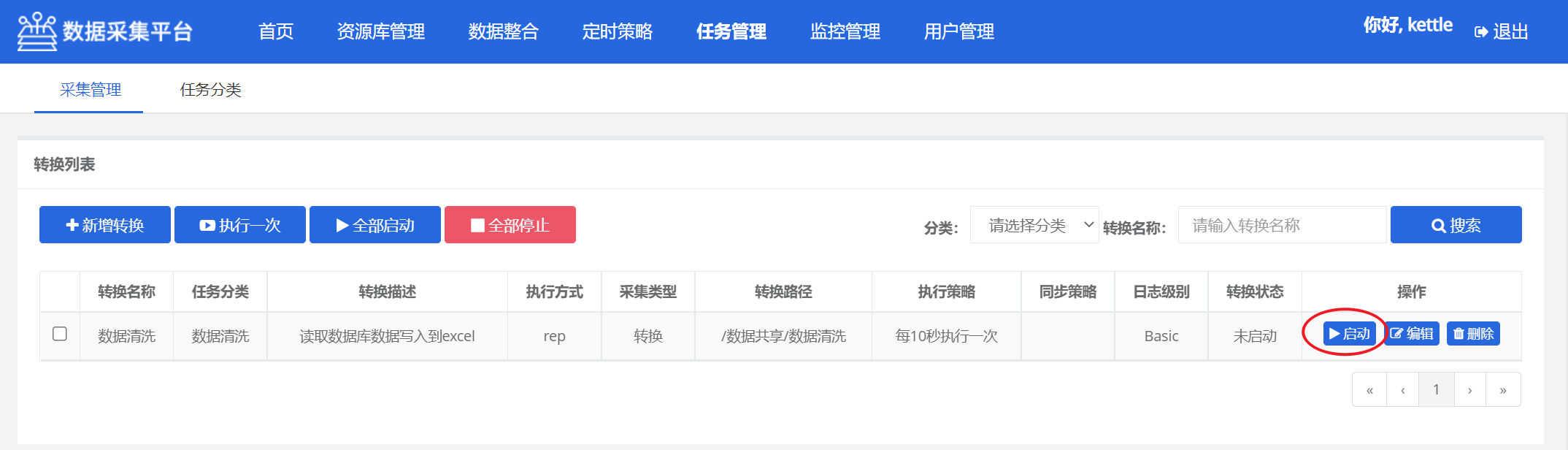
- 采集管理
(1) 新增转换

(2) 启动转换
(3) 生成文件

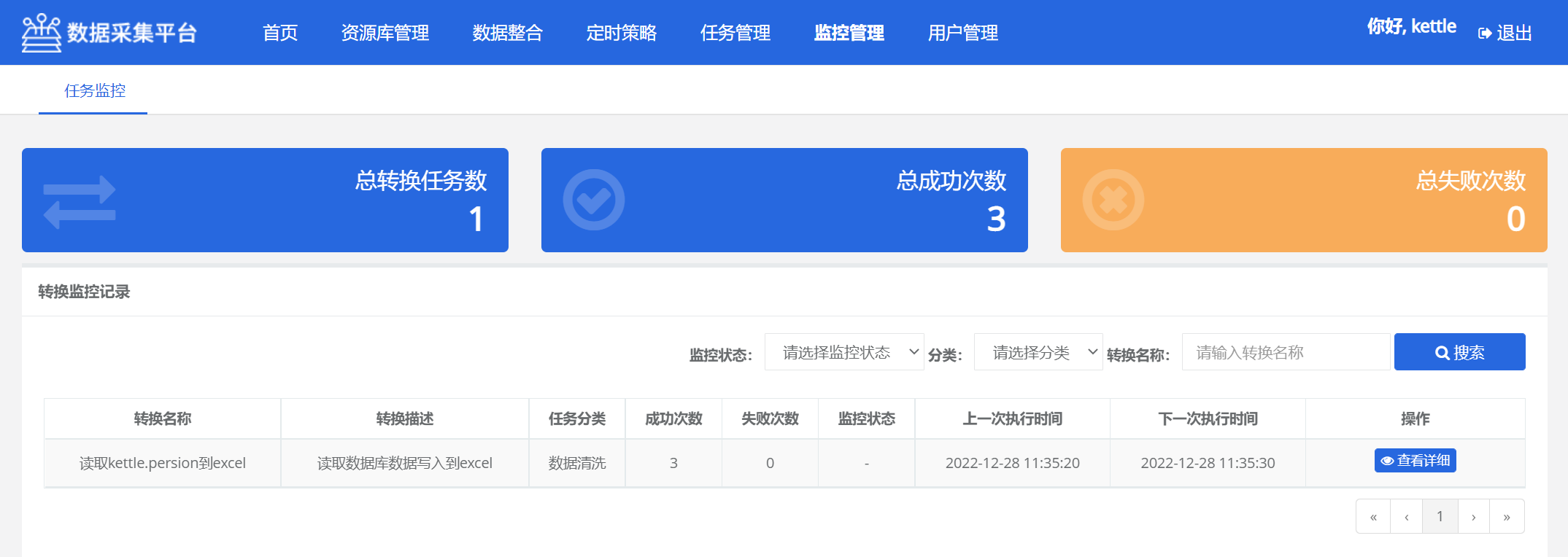
5.8 监控管理
可以查看任务的执行记录和执行状态
5.9 用户管理