在机器学习中,我们常见的优化模型的方法是结果导向型,通过观察损失函数的趋势曲线图,去调整学习率,优化器等。这是对模型参数的调整,以达到优化的效果。殊不知,还有一种是对数据特征的处理,但这里的处理又非指的是简单的预处理。
优化模型——数据端出发(上) 或者 参数方面切入(下)
目录
1.损失值间的博弈
这里的博弈指的是训练集损失值和测试集损失值之间的权衡。
1.1 博弈的缘由
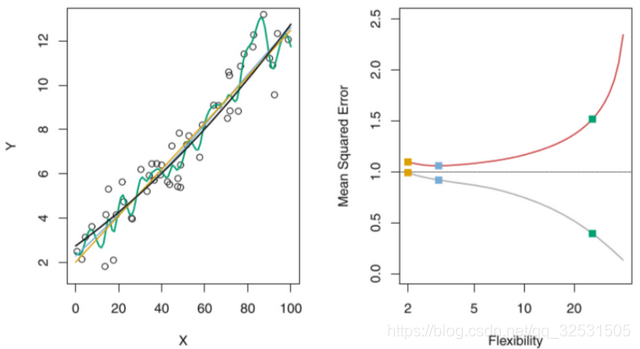
左图:黑线为某真实函数f,数据点(圆圈)由 f 模拟产生。提出用三种不同函数对数据点进行模拟:绿色线为线性回归、橙色和蓝色曲线为两条光滑样条拟合。
右图:灰色曲线为训练集的MSE,红色曲线为测试集MSE
方块分别对应左图的三种拟合中的训练集MSE和测试集MSE
简要分析如下:
绿色曲线对数据集的拟合程度最高,训练集的损失是最小的,然而在测试中遭遇滑铁卢,得到了倒数第一名,测试集损失值最大,也就是说绿色曲线所对应的模型在对训练集以外的数据泛化能力最弱,与实际想要达到的数值(效果)差距较大。然而与黑线(真实函数)依次接近的橙色和蓝色线条,训练集与测试集的损失相差不大,泛化能力强于绿色线条的线性回归,这样的模型是可以在所要使用的场景中很好地应答未训练的陌生数据。
注意
,我们在这里假设了一个前提,便是知道真实函数的存在,知道训练所得模型的优劣。现实中,撤销黑线(真实函数),如何找到泛化能力优秀的模型,是我们实践中所要面临的难点和抉择。在这当中,博弈既存在数据之中,训练数据与测试数据的抗衡,也存在实验者的调整抉择中。
2.数据端对模型的优化
2.1 模型的方差与偏差
方差
模型的方差可以这样理解,用相同数量但内容不同的数据集去估计某个模型 f ,不同数据集得到不同的 f’ , 不同 f’ 之间的差异便是模型的方差。对于模型的方差来说,有这样一个趋势——模型的复杂度越高,f 的方差就会越大。
偏差
模型的偏差,举个例子,有A和B两个模型,由相同的数据训练得到,只是建模的方式不同,导致性能A强于B,即模型A的泛化能力强于模型B,其中由于两个模型的复杂度不同引起的误差为模型的偏差。
方差和偏差
都要小
,这就意味着,模型能够充分地拟合数据——偏差小,模型也能很好地降低不同数据带来的扰动影响——方差小
2.2 模型的优化
2.2.1 训练误差修正
先说一结论,模型越复杂,训练误差越小,测试误差先小后大。
所以我们可以先构造一个特征较多的模型——多元多次方就是比单一的线性特征多——使其过拟合,过拟合便是训练误差小,测试误差大。这时我们对特征个数进行惩罚,惩罚项因为特征数量的增加而增大,可以抑制训练误差随着特征个数的增加而无休止的减小。

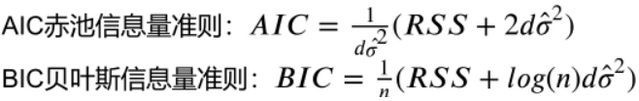
2.2.2 交叉验证
2.2.1中是通过训练误差的修正来得到不错的测试误差,而交叉验证则是对测试误差的直接估计。对交叉验证的详细了解,请移步如下——
CSDN博主详解交叉验证
2.2.3 压缩估计(正则化)
不同于2.2.1中的对特征的选择,正则化是对已确定的特征中的回归系数进行约束,该约束可以显著的降低模型的方差。一般的操作是将回归系数往零的方向压缩。
著名的正则化是 L2正则化(岭回归)和 L1正则化(Lasso回归)
正则化
详解(引用)
2.2.4 降维
所谓降维,就是将原始的特征空间投影到一个低维的空间,以实现变量的减少。
降维的
本质
——学习一个映射函数 f : x — y,其中x是原始数据点的表达,y是数据点映射后的低维向量表达,一般情况下,y的维度是小于x的维度,而 f 可能是显式的或者隐式的表达式,线性或者非线性的。
降维的
作用
——因为原始的数据中在所要应用的模型中存在冗余的信息以及噪音信息,通过降维处理,去冗余去噪音(提高信噪比),进而减少训练模型过程中的误差,提高实际应用的准确度。
降维的一个常见方法——
主成分分析(PCA)详解