作者 | 派派星 编辑 | CVHub
点击下方
卡片
,关注“
自动驾驶之心
”公众号
ADAS巨卷干货,即可获取
点击进入→
自动驾驶之心【深度估计】技术交流群
后台回复
【深度估计综述】
获取单目、双目深度估计等近5年内所有综述!

Title: Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation
Paper: https://arxiv.org/pdf/2211.13202.pdf
Code: https://github.com/noahzn/Lite-Mono
导读
自监督单目深度估计近年来引起了人们的关注。设计轻量但有效的模型,使它们能够部署在边缘设备上是非常有趣的。许多现有的架构受益于使用heavier的backbones,为了深度性能而牺牲了模型的大小。在本文中,研究者使用一个
轻量级
的体系结构来实现了具有竞争力的结果。具体来说,论文
研究了CNN和Transformer的有效组合
,并设计了一个混合结构Lite-Mono。提出了一种
连续扩张卷积
(CDC)模块和一个
局部-全局特征交互
(LGFI)模块。前者用于提取丰富的多尺度局部特征,后者利用自注意机制将随机的全局信息编码到局部特征中。实验表明,论文的完整模型在
精度上大大优于Monodepth2,模型参数减少了约80%。
动机
-
由于
缺乏
大规模精确的
ground truth深度数据集
,从
单目视频
中寻找监督信号的
自监督
方法是有利的。 -
CNN
中的卷积操作有一个局部接受域,不能捕获长期的全局信息,
更深的主干或更复杂的架构导致更大的模型规模
-
最近引入的Vision Transformer能够建模全局上下文进行单目深度估计,以获得更好的结果。然而,与CNN模型相比,
Transformer中多头自注意力模块的昂贵计算
阻碍了轻量级和快速推理模型的设计
贡献
本文提出了一个追求轻量级和高效的
混合CNN和Transformer
的
自监督单目深度估计
模型。在该编码器的每个阶段,都采用了一个连续扩张卷积模块来捕获增强的多尺度局部特征。然后,论文使用一个局部-全局特征交互模块来计算多头注意力,并将全局上下文编码到特征中。为了降低计算复杂度,论文还计算了信道维数而不是空间维数上的交叉协方差注意。该方法的贡献可以分为三个方面:
-
论文
提出了一种新的轻量级架构
,称为Lite-mono,
同时利用CNN和Transformer
用于自监督单目深度估计。论文证明了它对模型大小和FLOPs的有效性。 -
与更大的模型相比,Lite-mono在KITTI数据集上显示出更高的精度。它以
最少的可训练参数达到了最先进的水平
。在Make3D数据集上进一步验证了该模型的
泛化能力
。论文还进行了额外的笑容实验来验证不同设计选择的有效性。 -
在Nvidia Titan XP和Jetson Xavier平台上测试了该方法的推理时间,证明了该方法
在模型复杂性和推理速度之间的良好权衡
。
方法
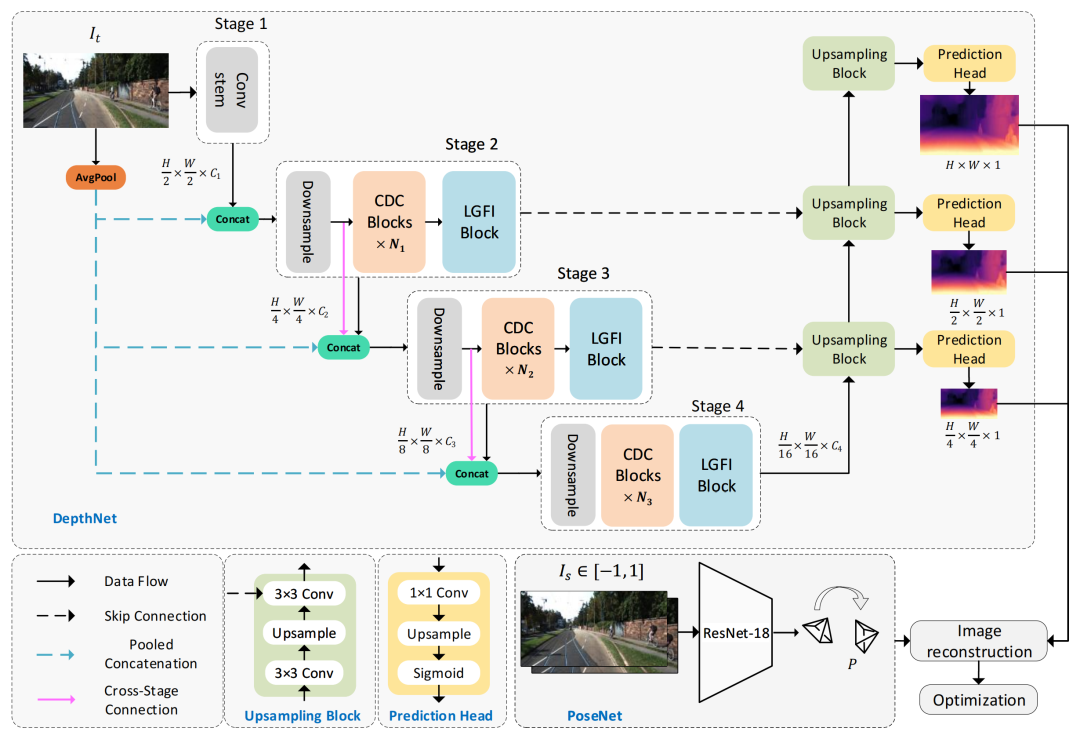
上图显示了Lite-Mono的体系结构。它由一个encoder-decoder
DepthNet
和一个
PoseNet
组成。DepthNet估计输入图像的多尺度深度图,而PoseNet估计两个相邻帧之间的摄像机运动。然后,生成一个重建的目标图像,并计算损失以优化模型。
Low-computation global information
DepthNet
Depth encoder
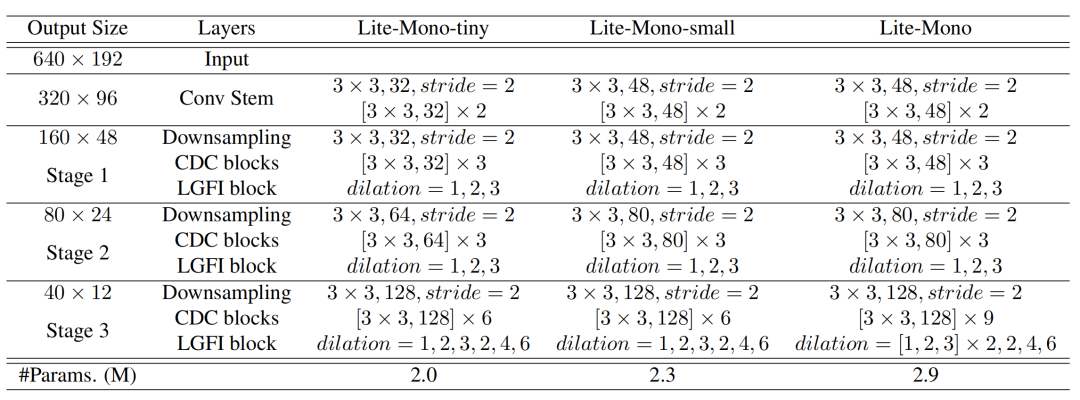
上图显示了本文提出的depth encoder的不同变体,Lite-Mono聚合了四个阶段的多尺度特征,意味着一个CDC块使用3×3内核大小来输出C通道,并
重复N次
。
Consecutive Dilated Convolutions (CDC)
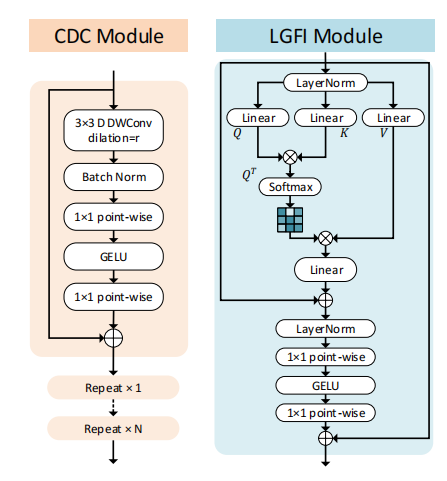
浅层CNN的感受域非常有限,而
使用扩张卷积有助于扩大感受域
。如上图所示,通过叠加所提出的连续扩张卷积(CDC),网络能够在更大的区域内“观察”输入,而不引入额外的训练参数。
论文所提出的CDC模块利用扩张卷积来提取多尺度的局部特征,在每个阶段插入
几个具有不同扩张率
的连续扩张卷积,以实现足够的多尺度上下文聚合.
Local-Global Features Interaction (LGFI)
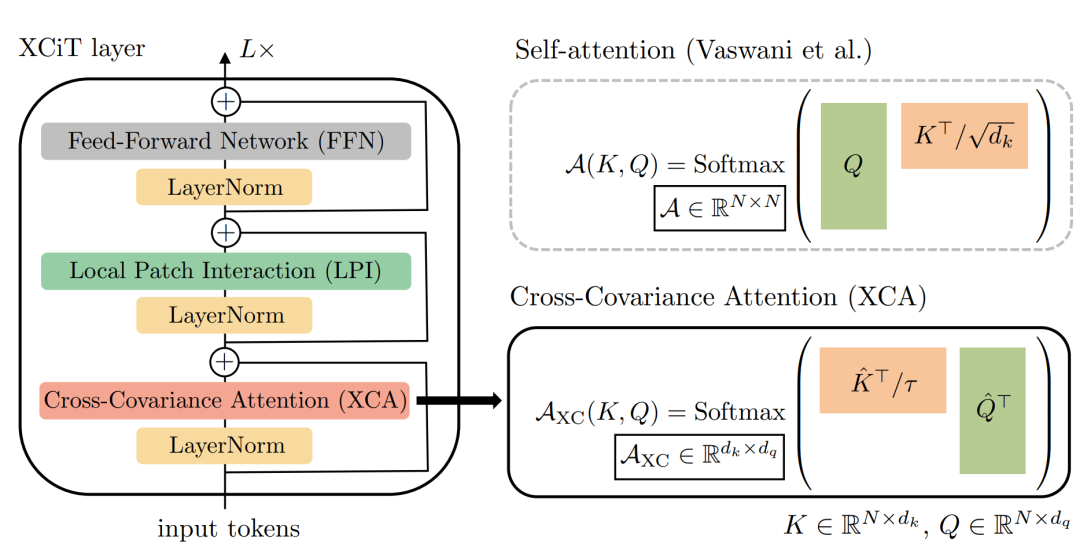
论文选用Transformer进一步增强全局信息。但是原始的Transformer中的
Attention是每个特征间做自相关
,因此复杂度与特征数量的平方成正比,这样做会对使大图片显存消耗翻倍增加。论文所提出的
局部-全局特征交互(LGFI)模块
参照XCiT
[1]
的做法,
不计算跨token的注意力
,而是计算
跨特征通道的注意力
,其中交互基于
K
和
Q
之间的
交叉协方差矩阵
,称为互协方差注意力(XCA,cross-covariance attention):
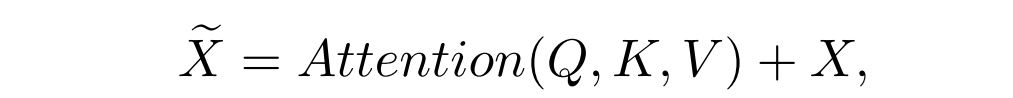
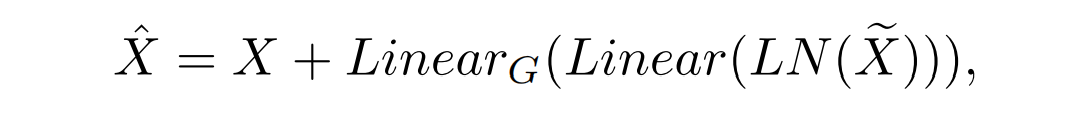
如上面的LGFI示意图所示,与原始的自注意力相比,它将
空间复杂度
从降低到,
时间复杂度
从降低到到,其中为注意头数量。
Depth decoder
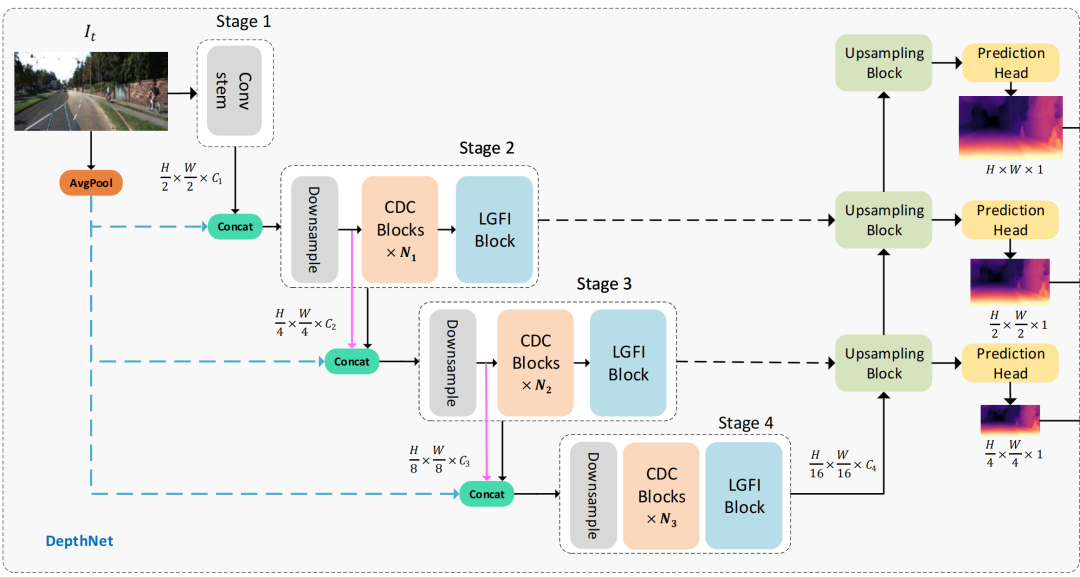
深度解码器部分,论文使用双线性上采样来增加空间维度,并使用卷积层来连接来自编码器的三个阶段的特征。每个上采样块跟着一个预测头,分别以全分辨率、 和的分辨率输出逆深度图。
PoseNet
论文使用一个预先训练过的ResNet18被用作
姿态编码器
,并且它接收一对彩色图像作为输入。利用具有四个卷积层的
姿态解码器
来估计
相邻图像之间
对应的
6自由度相对姿态
Self-supervised learning
论文使用单目深度估计任务中常见的方法:
将深度估计任务转换为图像重建的任务
,学习目标被建模为
最小化
目标图像与重构目标图像之间的
图像重建损失
,以及约束在预测
深度图上的边缘感知平滑损失。
Image reconstruction loss
光度重投影损失的定义为:
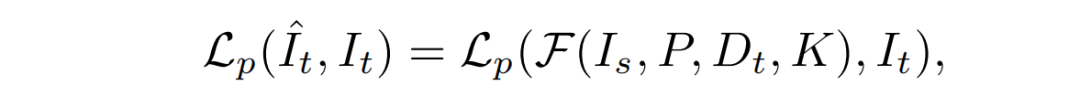
上面公式相当于
两个相机坐标系下的转换
,即
源图像
(一般为前后帧)先用内参的逆转换到它的
相机坐标系
,再用旋转平移矩阵转到
目标图像相机坐标系
,再用内参转到
目标图像的图像坐标系
得到重构的目标图像,计算
目标图像
和
重构目标图像
之间的损失:
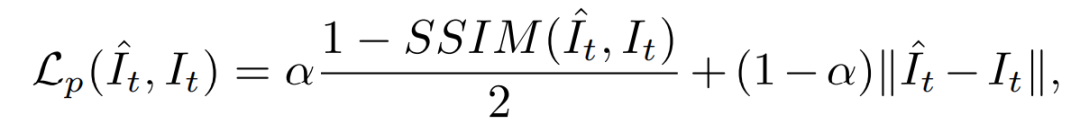
Edge-aware smoothness loss
为了平滑生成的逆深度图,论文计算一个
边缘感知的平滑损失
:
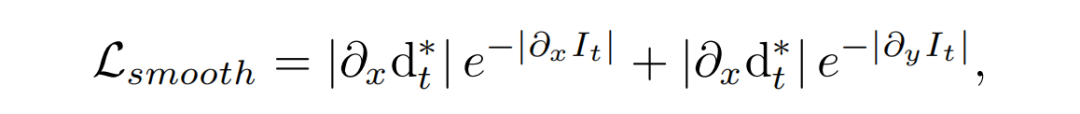
其中表示mean-normalized的逆深度。总损失可表示为:
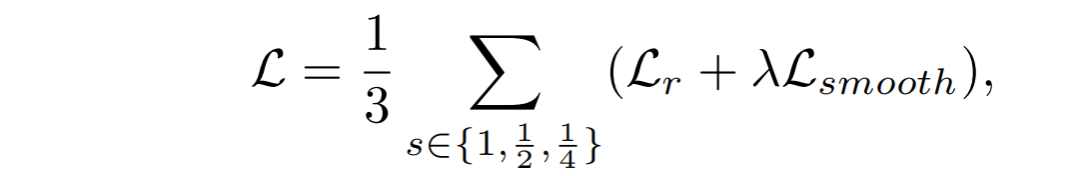
其中s为深度解码器输出的不同比例输出。
实验
KITTI results
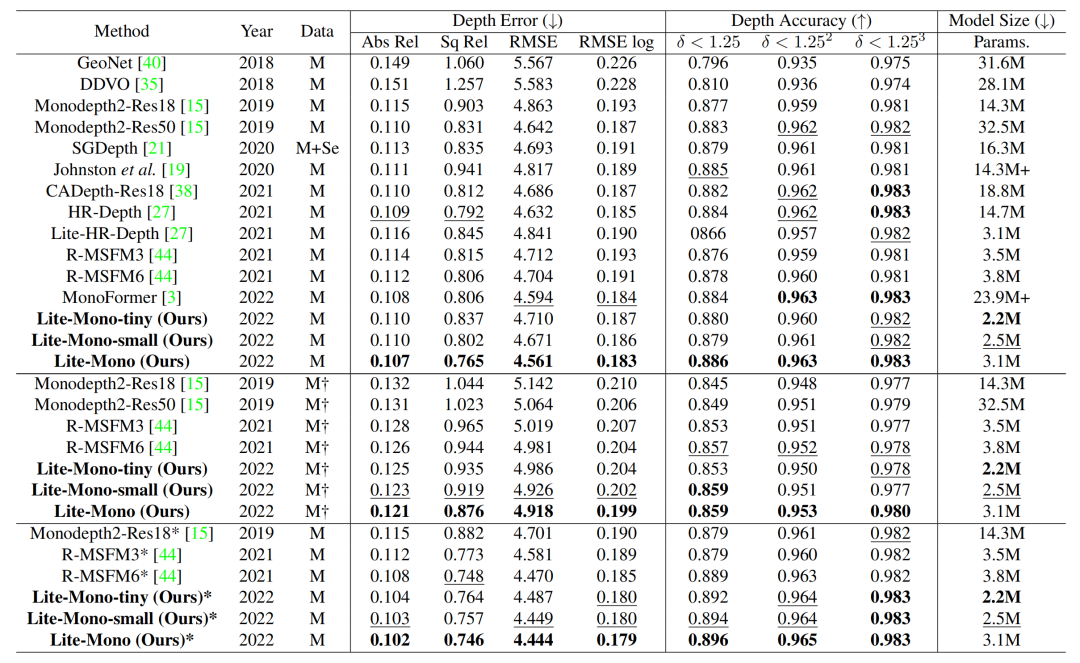
论文将所提出的框架与其他模型尺寸小于35M的代表性方法在
KITTI benchmark
进行了比较,结果如表2所示。
完整模型的Lite-Mono效果最好,论文的其他两个较小的模型也取得了令人满意的结果。
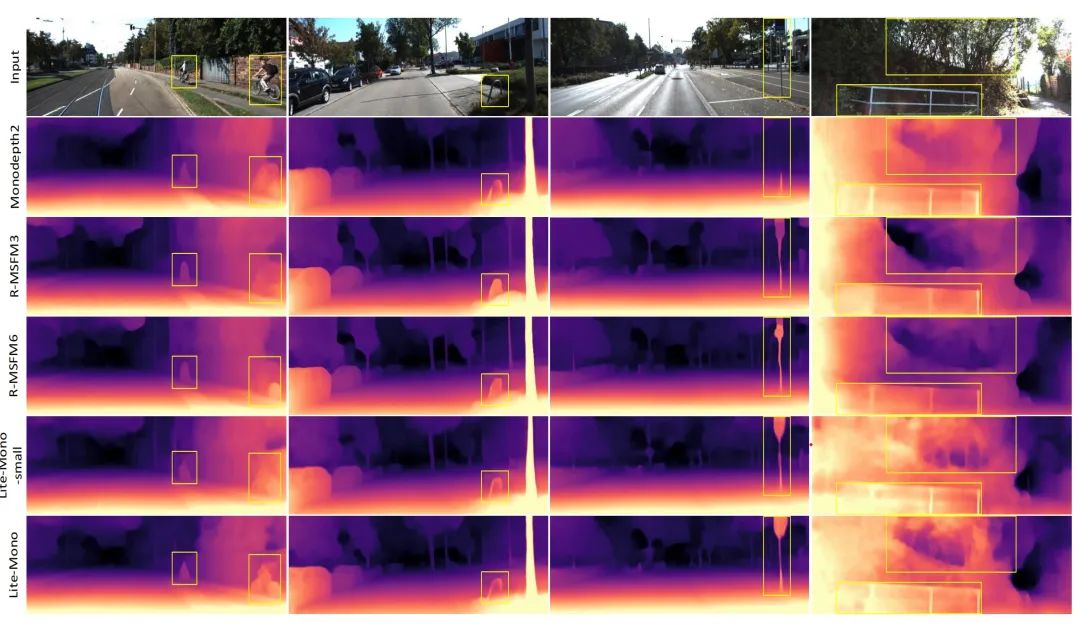
上图显示,所提出的Lite-Mono取得了令人满意的结果,即使是在
移动物体靠近相机
的具有挑战性
的图像
上(列1)。
Make3D results
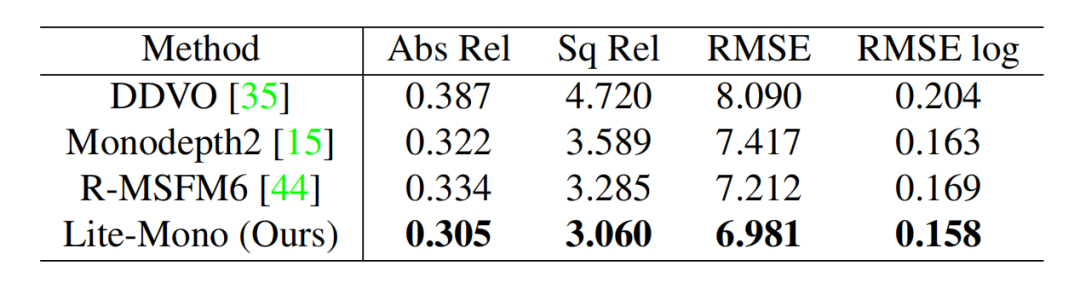
论文还在Make3D数据集上进行了评估,以
显示所提方法在不同室外场景中的泛化能力
。表3显示了Lite-Mono与其他三种方法的比较,其中
Lite-Mono表现最好
。

上图显示了一些定性的结果。由于所提出的特征提取模块,Lite-Mono能够建模局部和全局上下文,并感知不同大小的对象。
Complexity and speed evaluation

论文在Nvidia Titan XP和Jetson Xavier上对该模型的参数、FLOPs(浮点运算)和推理时间进行了评估,并与Monodepth2和R-MSFM进行了比较。表4显示,Lite-Mono设计在
模型尺寸和速度之间有很好的平衡
。虽然R-MSFM是一个轻量级的模型,但它是最慢的。论文的模型还可以在Jetson Xavier快速推理,这使得将它们部署
在边缘设备上成为可能。
消融实验

论文删除或调整了网络中的一些模块来进行消融实验,并在KITTI上报告了它们的结果,如表5所示。
总结
本文提出了一种新的
轻量级单目自监督单目深度估计
方法。设计了一种混合的 架构来建模
多尺度增强
的
局部特征
和
全局上下文信息
。在8个KITTI数据集上的实验结果证明了该方法的优越性。通过在提出的CDC块中
设置优化的扩张率
,并插入LGFI模块来获得
局部-全局特征相关性
,Lite-Mono可以
感知不同尺度的物体
,甚至是对靠近摄像机的移动物体。论文还验证了该模型在Make3D数据集上的泛化能力。此外,Lite-Mono
在模型复杂性和推理速度之间实现了良好的权衡
。
References
[1]
XCiT: Cross-Covariance Image Transformers: https://arxiv.org/pdf/2106.09681.pdf
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,
与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频
,期待交流!

【
自动驾驶之心
】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称