TF的fine-grained API为分布式程序的设计和开发提供了非常的灵活性,用户可以将不同的分布式架构与TF结合。PS-Worker是一种经典的分布式架构,它在大规模分布式机器学习、深度学习领域得到了广泛的应用。TF提供对PS-worker架构支持,并将其推荐为标准分布式编程框架。
本节主要介绍TF分布式程序的编程框架,以graph形式展现分布式程序的主要流程。目前大多数分布式程序均采用数据并行的模式加速模型训练,TF也为此专门设计了synchronized_optimizer,以便用户快速构建分布式程序。TF提供的Supervisor可以有效地提升模型训练过程的鲁棒性,同时简化模型fine-tune和retrain的过程。
PS-worker架构概述
PS-worker architecture 有效解决了大规模参数在分布式存储和更新时的一致性问题,兼具通用性和高效性。
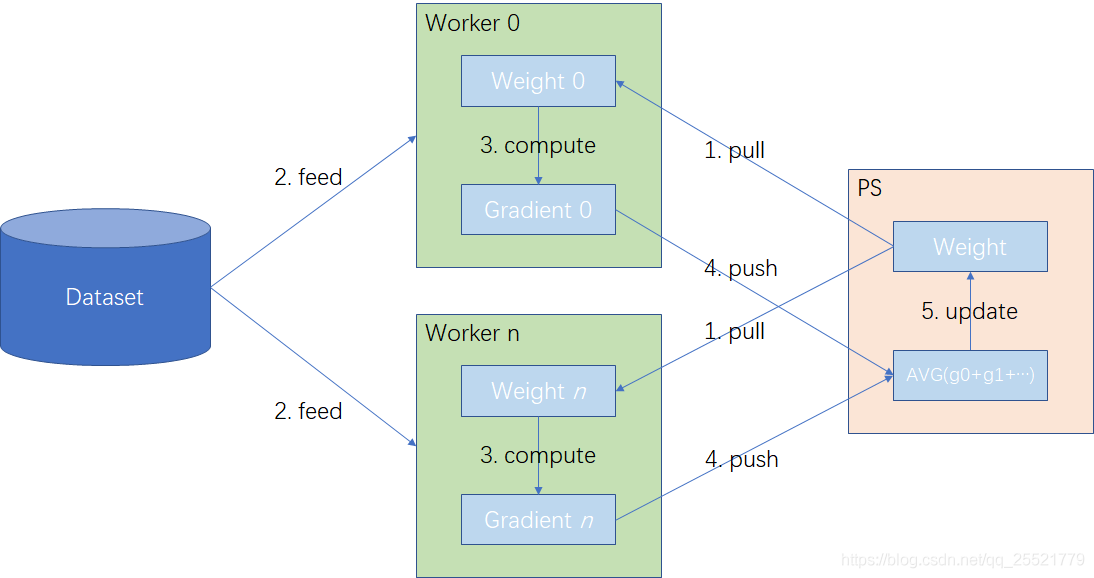
典型的PS-worker架构如下所示:
所有参数唯一地存储在PS内存中,当模型参数规模超过一台服务器内存大小时,则需要分布式的存储在多个PS中。最简单的分布式策略为循环:按照用户定义模型参数的顺序,将参数依次循环保存到各个PS中,尽可能地保证每个PS中存储的参数个数相等。假如模型共有90个参数,按照循环策略分布式存储在3个PS中,则各PS存储的参数分别是[3i+1], [3i+2], [3i],
i
∈
[
0
,
90
]
i \in [0, 90]
i∈[0,90]。模型训练过程中的前向计算和反向计算均是worker完成。训练数据集存储在共享文件系统或分布式文件系统中。
注,本节仅讨论数据并行模式,即各worker数据流图的拓扑结构相同,填充的数据不同。
为了简单清晰的描述,我们先假设模型都存储在一个PS上,在这种情况下,PS-worker架构训练分布式模型的流程如下:
- pull:各worker根据数据流图的拓扑结构,从PS拉取最新的模型参数
- feed:各worker按照一定的规则填充不同批次的批数据。
- comput:各worker使用相同的模型参数和不同的批数据计算梯度,得出不同的梯度值。
- push:各worker将计算得到的梯度推送到PS。
- update:PS汇总n个worker的梯度,求出平均梯度后更新模型参数。
PS-worker的核心思想是将模型和训练解耦合,将一个模型的训练过程分为两类作业(job):一类是模型相关作业,包括模型参数的存储、分发、汇总、更新,由PS执行;另一类是训练相关作业,包括推理计算和梯度计算等,由worker执行。同类job内部可以包含多个并行执行的task,每个task的工作流程相同,但是处理的任务不同。
分布式程序框架概述
分布式程序是指多个进程协同执行的程序。在TF分布式编程框架中,每个PS和worker都是有单独线程实现的。
编写分布式程序主要分为创建集群,创建分布式graph,以及创建并运行分布式会话。
- 创建集群:包括定义集群中所有进程对应的服务器主机名和端口,并启动各个服务。
- 创建分布式graph:graph上的节点包括表示输入的占位符、保存模型参数的变量、前向图和后向图计算操作,以及专门为分布式设计的synchronized optimizer和同步队列(sync_token_queue)的初始化操作。
- 创建并运行分布式会话:涉及实用模型训练管理组件(Supervisor)创建分布式会话,然后在会话中执行graph中的各项操作。
创建TF集群
TF集群是指完成一次完整的深度学习训练或推理工作所需的分布式运行实体及其相关的资源集合。TF集群中的每个任务在运行时映射到OS中的一个进程。任务按照所属Job类型,可分为PS和worker两类,同类任务通过不同的task index加以区分。
一般我们将任务编号为0的worker称为chief worker。它与其它worker任务略有不同,除了按部就班地训练型外,还需要在训练开始时初始化全局变量,以及在训练过程中将全局变量保存到checkpoint file。
典型分布式应用程序的进程包含两部分:
- Server:相应集群内其他任务的服务请求,负责协调会话的运行以及本地设备上的局部图执行。
- Client:维护用户创建的数据流图和会话,通过访问服务端执行Session。
TF cluster可以使用tf.train.ClusterSpec类定义,该类的构造方法接收一个描述集群中所有任务的字典,其键为作业名称,值为输入该作业类型的所有任务的主机名和端口。用户需要显式地指定该字典,以确保每个task能够以点到点的方式与集群中任意其他任务通信。TF任务内部的服务器抽象是tf.train.server类,其构造方法的主要输入为tf.train.ClusterSpec示例,以及当前任务的作业名称和任务编号。
服务器抽象是指集群中特定任务(PS or worker)中的一种上层抽象,而不是物理服务器。
TF没有提供一次性启动整个集群的解决方案,所以用户需要在每台机器上手动启动一个集群的所有PS和Worker任务。为了能够以同一份代码启动不同的任务,我们需要将所有worker任务的主机名和端口,所有PS任务的主机名和端口、当前任务的作业名称和任务编号进行参数化。通过输入不同的命令行参数组合,用户就可以使用同一份代码正确地启动每一个任务。
- job_name,作业名称,例如“worker”
- task_index,任务编号,例如“0”
- ps_hosts,所有PS任务的主机名和端口,例如“10.0.0.1:5000”
- worker_hosts,所有worker任务的主机名和端口,例如“10.0.0.2:3389, 10.0.0.2:3389”
创建TF cluster示例代码:
import tensorflow as tf
import argparse
parser = argparse.ArgumentParser("TF cluster")
# create TF clusters' parameters
parser.add_argument('--task_index', default=None, type=int,
help='worker task index should >= 0.' \
'task_index=0 is the master worker task that performs the initialization of variables.')
parser.add_argument('--ps_hosts', default=None, type=str, help='comma-separated list of hostname:port pairs')
parser.add_argument('--worker_hosts', default=None, type=str, help='comma-separated list of hostname:port pairs')
parser.add_argument('--job_name', type=str, default=None, choices=['worker', 'ps'])
args=parser.parse_args()
def main():
PS_spec = args.ps_hosts.split(',')
worker_spec = args.worker_hosts.split(',')
# define TF cluster
cluster= tf.train.ClusterSpec({'ps': PS_spec, 'worker': worker_spec})
server = tf.train.Server(cluster, job_name=args.job_name, task_index=args.task_index)
if args.job_name==' ps':
server.join()
is_chief = (args.task_index == 0)
操作放置到目标设备
如果将所有任务都是用同一份代码启动,那么必须将各任务的操作放置到对应的设备上执行。TF提供的with tf.device语句指定某一代码作用域对应的目标设备。tf.device方法的简单用法是直接传入代表设备名称的字符串,该字符串由作业名称、任务编号和可选的设备编号组成,示例代码如下:
# 放置变量w1, b1到PS0任务所在设备上:
with tf.device('/job:PS/task:0'):
w1 = tf.Variable()
b1 = tf.Variable()
with tf.device('/job:PS/task:1'):
w2 = tf.Variable()
b1 = tf.Variable()
# 将计算操作放到worker1任务所在设备上:
with tf.device('/job:worker/task:1'):
x = tf.placeholder([None, 128, 128, 3], tf.float32)
layer1 = tf.nn.relu(tf.matmul(x, w1) + b1)
logits = tf.matmul(layer1, w2) + b2
此外,tf.device()还支持以“设备名称生成函数作为参数”。这种方式有利于设计更高级的操作放置策略,简化实现代码。TF内置了设备设置器方法tf.train.replica_device_setter(),它能够返回tf.device所接受的设备名称生成函数,主要用于在数据并行的场景下的放置操作。主要输入参数包括
- worker_device:worker任务绑定的设备名称
- ps_device:PS任务绑定的设备名称
- cluster:TF cluster实例
示例代码如下:
if args.num_gpus > 0:
if flags.num_gpus < num_workers:
raise ValueError('number of GPUs is less than number of workers')
gpu = args.task_index % args.num_gpus
worker_device = "/job:worker/task{}:/gpu:{}".format(args.task_index, gpu)
elif args.num_gpus == 0:
cpu = 0
worker_device = "/job:worker/task{}:/cpu:{}".format(args.task_index, cpu)
with tf.device(tf.train_relica_device_setter(worker_device=worker_device,
ps_device="/job:ps/cpu:0", cluster)):
...
数据并行模式
一般采用数据并行的方式加速模型训练,在这种方式下,所有worker共享PS上存储的模型参数,并按照相同的拓扑结构的graph进行计算。因为不同的worker接受了不同的batch data,所以会得到不同的gradients。PS汇总所有的gradients后,采用平均梯度对模型参数进行更新。该方法能够有效避免单批数据噪声对优化方向的影响。
根据Graph的构建模式,我们可以将数据并行分为一下两类:
- 图内复制(in-graph replication)
单进程、单机多卡的数据并行训练,需要用户自己实现梯度的汇总和平均计算。典型示例见models/tutorials/image/cifa10/cifar10_multi_gpu_train.py中的CIFAR-10的多GPU训练。 - 图间复制(between-graph replication)
多进程、可跨多机的分布式并行训练,用户需要调用SyncReplicaOptimizer,实现分布式模型的梯度计算核模型参数更新。典型示例见tensorflow/tools/dist_test/python/mnist_replica.py中的MNIST分布式模型。
【问】这个图内复制和图间复制什么意思?
根据训练时模型参数的更新机制,数据并行可以分为一下两类:
- 异步训练
每个worker独立训练,计算出梯度后立即进行模型参数更新计算,每个worker无需阻塞等待其他worker的梯度计算完成。 - 同步训练
每个worker独立训练,直到所有worker计算出梯度后再进行模型参数汇总计算,并更新当前train step的模型参数。计算较快的worker需要阻塞等待计算较慢的worker。
以上两种训练机制都同时适用于图内复制和图间复制模式。一般同步训练的收敛速度更快、训练步数更少;异步训练的单步耗时更少,但是更容易受单批数据的影响,训练步数反而增加。
同步训练机制
同步训练机制基于同步标记队列和同步优化器,它们能够确保分布式模型每一步的训练过程中都是公平的,不受个别计算能力强的worker任务影响。
示例代码如下:
def model():
x = tf.placeholder(tf.float32, [None, 784], name='x')
gt = tf.placeholder(tf.float32, [None, 10], name='groundtruth')
with tf.variable_scope('layer1'):
w1 = tf.get_variable('weight1', [784, 1024], initializer=tf.random_normal_initializer())
b1 = tf.get_variable('bias1', [1024], initializer=tf.constant_initializer(0.0))
h = tf.matmul(x, w1) + b1
with tf.variable_scope('layer2'):
w2 = tf.get_variable('weight2', [1024, 10], initializer=tf.random_normal_initializer())
b2 = tf.get_variable('bias2', [10], initializer=tf.constant_initializer(0.0))
y = tf.matmul(h, w2) + b2
# losses
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=gt, logits=y))
# Adam Optimizer
optimizer = tf.train.AdamOptimizer(args.lr)
# create synchronized optimization
if args.sync_replicas:
if args.replicas_to_aggregate is None:
replicas_to_aggregate = num_workers
else:
replicas_to_aggregate = args.replicas_to_aggregate
optimizer = tf.train.SyncReplicasOptimizer(optimizer, replicas_to_aggregate,
total_num_replicas=num_workers, name='mnist_sync_replicas')
train_step = optimizer.minimize(cross_entropy, global_step=global_step)
上面的代码,是在普通优化器的基础上,包装出了同步优化器。同步优化器的主要参数:
- replicas_to_aggregate:并行副本数,num_workers
- total_num_replicas:实际副本数或worker任务数,num_workers
- nonevariable_averages:是否使用ExponentialMovingAverage,默认值None
- variables_to_average:需要进行平均值计算的模型参数列表,默认值None
num_workers是用户在集群配置的worker_hosts参数中声明的worker任务数量。TF的worker任务是承担梯度计算的实体,副本是模型训练过程中单独处理一份批数据的抽象。
并行副本数:单步训练中需要参与并行计算的副本数量,即用户期望单步运行的并行数据个数
实际副本数:单步训练中实际参与计算的worker任务数。
通过配置不同的replicas_to_aggregate和total_num_replicas,可以实现灵活的同步训练机制即多样化的模型参数更新模式。
- replicas_to_aggregate 等于 total_num_replicas,即“全民参与”模式。每个worker任务都领取一份不同的批数据进行训练,每一步训练一般都会有所有worker共同参与计算。
- replicas_to_aggregate 大于 total_num_replicas,即“能者多劳”模式,因为需要的并行副本数大于worker任务数,因此始终存在某个worker计算多次梯度。
- replicas_to_aggregate 小于 total_num_replicas,即“替补等位”模式,因为需要的并行副本数并不多,因此存在某些worker空闲。但是这种冗余机制,能够确保TF分布式训练过程的高可用性。
同步优化器在计算梯度时与普通优化器没有区别,均直接调用基类Optimizer的compute_gradients()成员方法。但是,在应用梯度更新模型参数时,它为分布式程序做了独特的设计。同步优化器重写了Optimizer的apply_gradients()成员方法。
同步优化器的两个主要组件:
-
梯度聚合器(gradients accumulator)
存储梯度值的队列。以模型参数作为区分,每个模型参数拥有一个单独的队列,队列收集来自于不同worker、根据不同批数据计算出来的该模型参数对应的梯度值。 -
同步标记队列(synchronized token queue)
存储同步标记的队列。同步标记决定worker是否能够执行梯度计算任务。当队列中没有同步标记时,worker无法从PS获取更新后的模型参数,也就无法进行梯度计算。
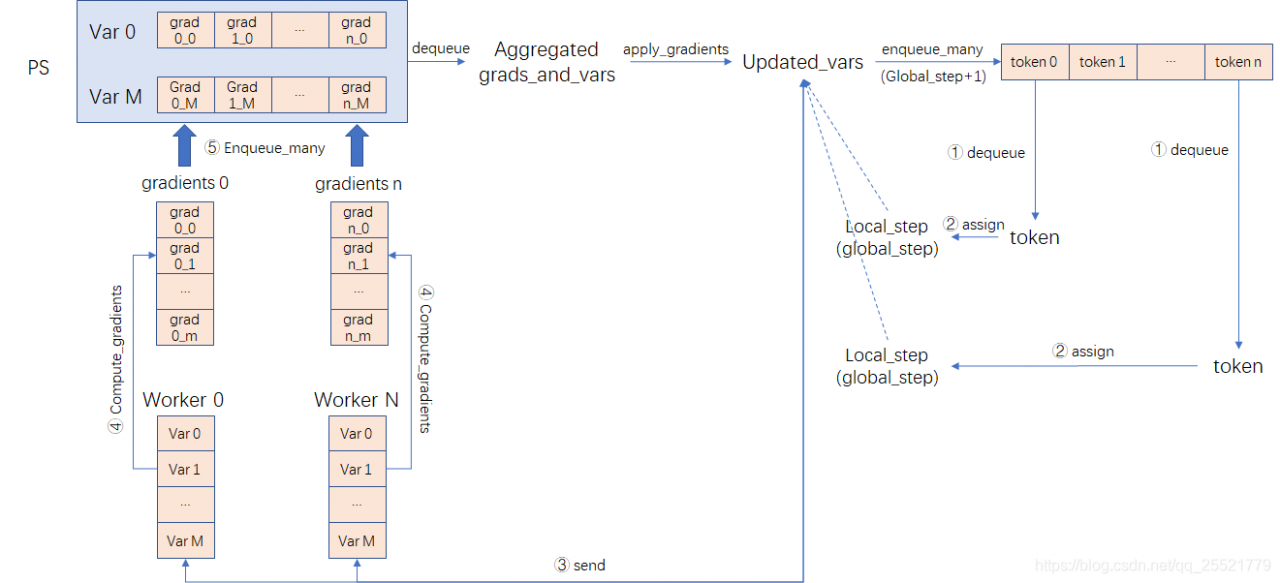
上图是同步优化器在“全民参与”模式下的工作流程。
其中,worker具体工作步骤如下:
- 从sync_token_queue中取出一个值为global_step、表示全局训练步数的token;
- 将token的值赋予worker的本地训练步数(local_step);
- 从PS中获取最新模型参数;
- N个worker单独计算M个模型参数对应的M个梯度值;
- 每个worker将M个梯度值分别推送到对应的梯度队列中;
PS具体工作步骤如下:
- 梯度聚合器收集worker计算的梯度值,当每个梯度队列收集到N份梯度值,就开始计算平均梯度。当所有的梯度队列都计算出平均梯度后,就可以得到M对{模型参数,平均梯度值}的聚合元组(aggregated_grads_and_vars)。
- 将平均梯度值更新到对应的模型参数,得到更新后的模型参数。
- 向同步标记队列推送下一步训练需要的N个同步token,值为global+1。
同步更新机制是一种基于全局同步时序更新模型参数的机制。在gradients accumulator 和 synchronized token queue的配合下,同步优化器能够确保每一步训练时,各个worker在不同批数据上计算出的梯度能够正确的进行聚合平均,然后一次性同步到PS的模型参数中。
同步更新机制实现了真正的数据并行,所有参与计算的worker共同组成了一个拥有更强算力的虚拟计算设备,以此提升模型训练速度。
同步更新机制依赖于synchronize token queue的状态。每一步训练启动的前提是同步标记队列参数被填满了N个值为global_step的同步tokens。第一次训练时,由于PS没有更新模型参数,所以不会向同步标记队列中入队tokens。因此需要执行一个初始化synchronize token queue的操作——sync_init_op。它不依赖模型参数的更新操作,而是直接向synchronize token queue填充N个值为0的tokens。
除了初始化synchronize token queue以外,分布式模型训练开始前,还需要执行一些其他的初始化操作:
- optimizer.local_step_init_op,设置local_step的初始值
- optimizer.chief_init_op,设置global_step的初始值
- optimizer.ready_for_local_init_op,为未初始化的Variable设置初始值
- optimizer.get_init_tokens_op(),获得sync_init_op,初始化synchronize token queue
- tf.global_variables_initializer(),为全局Variables设置初始值
典型初始化示例:
if args.sync_replicas:
# 非chief worker:为local_step设置初始值
local_step_init_op = optimizer.local_step_init_op
# chief worker
if is_chief:
global_step_init_op = optimizer.chief_init_op
ready_for_local_init_op = optimizer.ready_for_local_init_op
# 定义启动sychronize token queue的QueueRunner实例
chief_queue_runner = optimizer.get_chief_queue_runner()
# 定义对sychonize token queue初始化的操作
sync_init_op = optimizer.get_init_token_op()
# 定义全局变量初始化操作
init_op = tf.global_variables_initializer()
异步训练机制
使用TF异步训练分布式模型时,不需要创建同步优化器实例,也不需要执行额外的初始化操作。异步训练机制的本质是将存储在PS上的模型参数共享给所有的worker,每个worker计算出的梯度值都直接用于更新模型参数,不用等待其他worker。程序不做梯度聚合器校验和梯度收集,也不需要从sychronize token queue中获取token。所有的worker的训练行为和单机模型训练基本一致,唯一不同在于模型参数需要从PS任务获取。当不同的worker同时进行参数更新和拉取操作时,TF内部的加锁机制保证模型参数的数据一致性。
Supervisor管理模型训练
在使用TF训练模型过程中,难免出现意外导致训练异常结束。为了提升模型训练过程的鲁棒性,TF为用户提供了训练管理类——Supervisor。该类同时支持单机和分布式模型训练的管理。具有以下功能:
- 在模型训练过程中,定期保存模型参数到checkpoint file
- 在重新启动训练程序时,从checkpoint file读取和恢复模型参数,并继续训练
- 在异常发生时,处理程序关闭和异常退出,同时完成内存回收等清理工作
Supervisor将大部分定期操作和异常处理封装成接口。用户只需要在初始化时设置好参数,之后便不需要做额外的逻辑控制和条件判断。Supervisor本质上是对三个类的封装:Saver, SessionManager & Coordinator。
Saver负责模型参数的存储和恢复,此外还能定期进行汇总操作,并将输出结果序列化保存到汇总事件文件中,用于不同类型的可视化。
Coordinator主要负责监控训练程序中启动的多个线程是否运行正常。在模型训练过程中,任何服务抛出异常时都会向Supervisor报告。此时,Coordinator会将程序的停止条件设置为True,Supervisor随机停止模型训练,并清理工作现场。
SessionManager为模型训练提供了实际运行环境。SessionManager帮助用户创建并管理单机或分布式会话,以便简化graph算法的生命周期维护逻辑。
使用Supervisor管理模型训练的典型流程:
- 创建一个Supervisor实例,向其构造方法传入checkpoint file和汇总event file的存储目录(logdir)
- 调用tf.train.Supervisor.managed_session()方法,从Supervisor实例获取一个会话实例。
- 使用该会话执行训练操作,并在训练过程中检查停止条件,以确保模型训练正确。