547. 省份数量
题目
有
n
个城市,其中一些彼此相连,另一些没有相连。如果城市
a
与城市
b
直接相连,且城市
b
与城市
c
直接相连,那么城市
a
与城市
c
间接相连。
省份
是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n
的矩阵
isConnected
,其中
isConnected[i][j] = 1
表示第
i
个城市和第
j
个城市直接相连,而
isConnected[i][j] = 0
表示二者不直接相连。
返回矩阵中
省份
的数量。
示例 1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mLzqZ6QV-1634779731926)(pic/graph1.jpg)]](https://img-blog.csdnimg.cn/d8452365ba294b63bcfec2e2cb9889db.png)
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]]
输出:2
示例 2:
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]]
输出:3
提示:
-
1 <= n <= 200
-
n == isConnected.length
-
n == isConnected[i].length
-
isConnected[i][j]
为
1
或
0
-
isConnected[i][i] == 1
-
isConnected[i][j] == isConnected[j][i]
题解
class Solution {
public:
int SearchRoot(int root, vector<int>& preArr)
{
int tmp;
int son;
son = root;
// 寻找当前位置的根节点
while (root != preArr[root]) {
root = preArr[root];
}
// 路径压缩
while (son != root) {
tmp = preArr[son];
preArr[son] = root;
son = tmp;
}
return root;
}
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
if (n == 0) {
return 0;
}
vector<int> preArr(n);
for (int i = 0; i < n; ++i) {
preArr[i] = i;
}
for (int i = 0; i < isConnected.size(); ++i) {
for (int j = i + 1; j < n; ++j) {
if (isConnected[i][j] == 0) {
continue;
}
int rootI = SearchRoot(i, preArr);
int rootJ = SearchRoot(j, preArr);
if (rootI == rootJ) {
continue;
}
preArr[rootJ] = rootI;
}
}
int res = 0;
for (int i = 0; i < n; ++i) {
if (preArr[i] == i) {
res++;
}
}
return res;
}
};
684. 冗余连接
题目
树可以看成是一个连通且
无环
的
无向
图。
给定往一棵
n
个节点 (节点值
1~n
) 的树中添加一条边后的图。添加的边的两个顶点包含在
1
到
n
中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为
n
的二维数组
edges
,
edges[i] = [ai, bi]
表示图中在
ai
和
bi
之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着
n
个节点的树。如果有多个答案,则返回数组
edges
中最后出现的边。
示例 1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aOOutVOn-1634779816078)(pic/1626676174-hOEVUL-image.png)]](https://img-blog.csdnimg.cn/8890e130aa2b4c59afbcc0c86cdee02a.png)
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
示例 2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZgOMGe88-1634779816079)(pic/1626676179-kGxcmu-image.png)]](https://img-blog.csdnimg.cn/acf459624de045a784a1fc0ff4d353ec.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAT3JhbmdlIFd1,size_14,color_FFFFFF,t_70,g_se,x_16)
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
提示:
-
n == edges.length
-
3 <= n <= 1000
-
edges[i].length == 2
-
1 <= ai < bi <= edges.length
-
ai != bi
-
edges
中无重复元素 - 给定的图是连通的
解答
#include <functional>
#include <iostream>
#include <vector>
#include <algorithm>
#include <stack>
#include <string>
#include <deque>
#include <set>
using namespace std;
int SearchRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
int n = edges.size();
vector<int> preArr(n + 1);
for (int i = 0; i <= n; ++i) {
preArr[i] = i;
}
for (auto e : edges) {
int rootA = SearchRoot(e[0], preArr);
int rootB = SearchRoot(e[1], preArr);
if (rootA == rootB) {
return e;
}
preArr[rootB] = rootA;
}
return {};
}
int main()
{
vector<vector<int>> arr = {{1,4},{3,4},{1,3},{1,2},{4,5}};
//{{1, 2}, {1, 3}, {2, 3}};{{1,2}, {2,3}, {3,4}, {1,4}, {1,5}}
vector<int> res = findRedundantConnection(arr);
for (auto i : res) {
cout << i << " ";
}
cout<<endl;
return 0;
}
200. 岛屿数量
题目
难度中等1373收藏分享切换为英文接收动态反馈
给你一个由
'1'
(陆地)和
'0'
(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
提示:
-
m == grid.length
-
n == grid[i].length
-
1 <= m, n <= 300
-
grid[i][j]
的值为
'0'
或
'1'
解答
class Solution {
public:
int SearchRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
int numIslands(vector<vector<char>>& grid)
{
int m = grid.size();
int n = grid[0].size();
int numOfSpcace = 0;
vector<int> preArr(m * n, -1);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == '0') {
numOfSpcace++;
}
preArr[i * n + j] = i * n + j;
}
}
vector<vector<int>> edges;
for (int i = 0; i < m; i++) {
for (int j = 1; j < n; j++) {
if (grid[i][j] == '1' && grid[i][j - 1] == '1') {
edges.push_back({i * n + j - 1, i * n + j});
}
}
}
for (int j = 0; j < n; j++) {
for (int i = 1; i < m; ++i) {
if(grid[i][j] == '1' && grid[i - 1][j] == '1') {
edges.push_back({(i - 1) * n + j, i * n + j});
}
}
}
//sort(edges.begin(), edges.end());
for (auto e : edges) {
int rootA = SearchRoot(e[0], preArr);
int rootB = SearchRoot(e[1], preArr);
if (rootA == rootB) {
continue;
}
preArr[rootA] = rootB;
}
// int dx[2] = {0, 1};
// int dy[2] = {1, 0};
// for (int i = 0; i < m; i++) {
// for (int j = 0; j < n; j++) {
// if (grid[i][j] == '0') {
// numOfSpcace++;
// continue;
// }
// for (int k = 0; k < 2; k++) {
// int ni = i + dx[k];
// int nj = j + dy[k];
// if (ni < m && nj < n && grid[ni][nj] == '1') {
// int rootOld = SearchRoot(i * n + j, preArr);
// int rootNew = SearchRoot(ni * n + nj, preArr);
// if (rootOld == rootNew) {
// continue;
// }
// preArr[rootNew] = rootOld;
// }
// }
// }
// }
int res = 0;
for (int i = 0; i < m * n; i++) {
if (preArr[i] == i) {
res++;
}
}
return res - numOfSpcace;
}
};
737. 句子的相似性||
题目
给定两个句子
words1
,
words2
(每个用字符串数组表示),和一个相似单词对的列表
pairs
,判断是否两个句子是相似的。
例如,当相似单词对是
pairs = [["great", "fine"], ["acting","drama"], ["skills","talent"]]
的时候,
words1 = ["great", "acting", "skills"] 和 words2 = ["fine", "drama", "talent"]
是相似的。
注意相似关系是 具有 传递性的。
例如,如果
“great”
和
“fine”
是相似的,
“fine”
和
“good”
是相似的,则
“great”
和
“good”
是相似的。
而且,相似关系是具有对称性的。
例如,
“great”
和
“fine”
是相似的相当于
“fine”
和
“great”
是相似的。
并且,一个单词总是与其自身相似。
例如,句子
words1 = [“great”]
,
words2 = [“great”]
,
pairs = []
是相似的,尽管没有输入特定的相似单词对。
最后,句子只会在具有相同单词个数的前提下才会相似。
所以一个句子
words1 = [“great”]
永远不可能和句子
words2 = [“doubleplus”,“good”]
相似。
注:
words1
and
words2
的长度不会超过 1000。
pairs
的长度不会超过 2000。
每个
pairs[i]
的长度为 2。
每个
words[i]
和
pairs[i][j]
的长度范围为 [1, 20]。
解题
#include <iostream>
#include <vector>
#include <string>
#include <unordered_map>
using namespace std;
string SearchRoot(string root, unordered_map<string, string>& preArr)
{
string son = root;
while (root != preArr[root]) {
root = preArr[root];
}
while (son != root) {
string tmp = preArr[son];
preArr[son] = root;
son = tmp;
}
return root;
}
bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<vector<string>>& pairs)
{
int words1Len = words1.size();
int words2Len = words2.size();
if (words1Len != words2Len) {
return false;
}
int pairsLen = pairs.size();
unordered_map<string, string> preArr;
for (auto pair : pairs) {
preArr[pair[0]] = pair[0];
preArr[pair[1]] = pair[1];
}
for (auto pair : pairs) {
string rootA = SearchRoot(pair[0], preArr);
string rootB = SearchRoot(pair[1], preArr);
if (rootA == rootB) {
continue;
}
preArr[rootA] = rootB;
}
for (int i = 0; i < words1Len; ++i) {
if (words1[i] != words2[i]) {
if (preArr[words1[i]] != preArr[words2[i]]) {
return false;
}
}
}
return true;
}
int main()
{
vector<string> w1 = {"great", "acting", "skillss"};
vector<string> w2 = {"fine", "drama", "talent"};
vector<vector<string>> pairs = {{"great", "fine"}, {"acting", "drama"}, {"skills", "talent"}};
if(areSentencesSimilarTwo(w1, w2, pairs)) {
cout<<"1"<<endl;
} else {
cout<<"2"<<endl;
}
return 0;
}
1102. 最高得分路径
题目
给你一个
R
行
C
列的整数矩阵
A
。矩阵上的路径从
[0,0]
开始,在
[R-1,C-1]
结束。
路径沿四个基本方向(上、下、左、右)展开,从一个已访问单元格移动到任一相邻的未访问单元格。
路径的得分是该路径上的 最小 值。例如,路径
8 → 4 → 5 → 9
的值为
4
。
找出所有路径中得分 最高 的那条路径,返回其 得分。
示例 1:
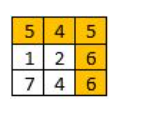
输入:[[5,4,5],[1,2,6],[7,4,6]]
输出:4
解释:
得分最高的路径用黄色突出显示。
示例 2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sD2ZDwFW-1634780102868)(pic/image-20211015091817002-16342606982752.png)]](https://img-blog.csdnimg.cn/e4b1e51cdbba463a9eb948ff941176ef.png)
输入:[[2,2,1,2,2,2],[1,2,2,2,1,2]]
输出:2
示例 3:
输入:[[3,4,6,3,4],[0,2,1,1,7],[8,8,3,2,7],[3,2,4,9,8],[4,1,2,0,0],[4,6,5,4,3]]
输出:3
提示:
1.
1 <= R, C <= 100
2.
0 <= A[i][j] <= 10^9
解答
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <algorithm>
using namespace std;
struct Point {
int x;
int y;
int val;
Point(int mx, int my, int mVal) : x(mx), y(my), val(mVal) {}
};
struct Cmp {
bool operator()(Point& a, Point& b)
{
return a.val < b.val; // 大顶堆
}
};
// 优先队列BFS
int MaximumMinimumPath0(vector<vector<int>>& A)
{
int rows = A.size();
int cols = A[0].size();
int i = 0;
int j = 0;
int res = min(A[0][0], A[rows - 1][cols - 1]);
priority_queue<Point, vector<Point>, Cmp> q;
q.push(Point(i, j, A[j][j]));
vector<vector<bool>> visited(rows, vector<bool>(cols, false));
visited[0][0] = true;
vector<vector<int>> dir = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
while (!q.empty()) {
res = min(res, q.top().val);
i = q.top().x;
j = q.top().y;
q.pop();
if (i == rows - 1 && j == cols - 1) {
return res;
}
for (auto d : dir) {
int ni = i + d[0];
int nj = j + d[1];
if (ni >= 0 && ni < rows && nj >= 0 && nj < cols && !visited[ni][nj]) {
q.push(Point(ni, nj, A[ni][nj]));
visited[ni][nj] = true;
}
}
}
return res;
}
// 二分查找
bool FindPath(vector<vector<int>>& A, vector<vector<bool>> visited, int i, int j, int val)
{
vector<vector<int>> dir = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
visited[i][j] = true;
if (i == A.size() - 1 && j == A[0].size() - 1) {
return true;
}
for (auto &d : dir) {
int x = i + d[0];
int y = j + d[1];
if (x >= 0 && x < A.size() && y >= 0 && y < A[0].size() && !visited[x][y] && A[x][y] >= val) {
if (FindPath(A, visited, x, y, val)) {
return true;
}
}
}
return false;
}
int MaximumMinimumPath1(vector<vector<int>>& A)
{
int m = A.size();
int n = A[0].size();
int l = 0;
int r = min(A[0][0], A[m - 1][n - 1]);
int res = r;
while (l <= r) {
vector<vector<bool>> visited(m, vector<bool>(n, false));
int midVal = l + (r - l) / 2;
if (FindPath(A, visited, 0, 0, midVal)) {
res = midVal;
l = midVal + 1;
} else {
r = midVal - 1;
}
}
return res;
}
// 并查集
bool Cmp(Point& a, Point& b)
{
return a.val > b.val;
}
int FindRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
void UnionRoot(int x, int y, vector<int>& preArr)
{
int root1 = FindRoot(x, preArr);
int root2 = FindRoot(y, preArr);
if (root1 != root2) {
preArr[root1] = root2;
}
}
int MaximumMinimumPath(vector<vector<int>>& A)
{
int m = A.size();
int n = A[0].size();
vector<int> preArr(m * n, 0);
vector<Point> pointVec;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
preArr[i * n + j] = i * n + j;
pointVec.push_back(Point(i, j, A[i][j]));
}
}
int res = min(A[0][0], A[m - 1][n - 1]);
// 按照得分,从大到小排序,非常重要
sort(pointVec.begin(), pointVec.end(), Cmp);
vector<vector<bool>> visited(m, vector<bool>(n, false));
visited[0][0] = true;
visited[m - 1][n - 1] = true;
vector<vector<int>> dir = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
int bId = 0;
int eId = m * n - 1;
for (auto p : pointVec) {
res = min(res, p.val);
int x = p.x;
int y = p.y;
int rootIndex = x * n + y;
visited[x][y] = true;
for (auto &d : dir) {
int nx = x + d[0];
int ny = y + d[1];
// 找到大的已经访问过的
if (nx >= 0 && nx < m && ny >= 0 && ny < n && visited[nx][ny]) {
int rootNIndex = nx * n + ny;
UnionRoot(rootIndex, rootNIndex, preArr);
}
}
if (FindRoot(bId, preArr) == FindRoot(eId, preArr)) {
break;
}
}
return res;
}
int main()
{
vector<vector<int>> arr = {{5, 4, 5}, {1, 2, 6}, {7, 4, 6}};
cout<<MaximumMinimumPath(arr)<<endl;
return 0;
}
1135. 最低成本联通所有城市
题目
想象一下你是个城市基建规划者,地图上有
N
座城市,它们按以
1
到
N
的次序编号。
给你一些可连接的选项
conections
,其中每个选项
conections[i] = [city1, city2, cost]
表示将城市
city1
和城市
city2
连接所要的成本。(连接是双向的,也就是说城市
city1
和城市
city2
相连也同样意味着城市
city2
和城市
city1
相连)。
返回使得每对城市间都存在将它们连接在一起的连通路径(可能长度为 1 的)最小成本。该最小成本应该是所用全部连接代价的综合。如果根据已知条件无法完成该项任务,则请你返回 -1。
示例 1:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EJTtluFr-1634780670800)(pic/image-20211016172459545.png)]](https://img-blog.csdnimg.cn/93c2fd5331db4d0789990ad7f2f4bfeb.png)
输入:N = 3, conections = [[1,2,5],[1,3,6],[2,3,1]]
输出:6
解释:
选出任意 2 条边都可以连接所有城市,我们从中选取成本最小的 2 条。
示例 2:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8VkC5dnp-1634780670802)(pic/image-20211016172507080.png)]](https://img-blog.csdnimg.cn/655920e44e8940b59b6d699efa4d0b53.png)
输入:N = 4, conections = [[1,2,3],[3,4,4]]
输出:-1
解释:
即使连通所有的边,也无法连接所有城市。
提示:
-
1 <= N <= 10000
-
1 <= conections.length <= 10000
-
1 <= conections[i][0], conections[i][1] <= N
-
0 <= conections[i][2] <= 10^5
-
conections[i][0] != conections[i][1]
题解
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <algorithm>
using namespace std;
struct Connection {
int A;
int B;
int cost;
Connection(int mA, int mB, int mC) : A(mA), B(mB), cost(mC) {}
};
bool Cmp(Connection &A, Connection &B)
{
return A.cost < B.cost;
}
int FindRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
void UnionRoot(int a, int b, vector<int>& preArr)
{
int rootA = FindRoot(a, preArr);
int rootB = FindRoot(b, preArr);
if (rootA != rootB) {
preArr[rootB] = rootA;
}
}
int minimumCost(int N, vector<vector<int>>& connections) {
int n = connections.size();
if (n < N - 1) {
return -1;
}
vector<int> preArr(N + 1, 0);
for (int i = 1; i <= N; i++) {
preArr[i] = i;
}
vector<Connection> conVec;
for (auto &c : connections) {
conVec.push_back(Connection(c[0], c[1], c[2]));
}
sort(conVec.begin(), conVec.end(), Cmp);
vector<bool> visited(N + 1, false);
int res = 0;
for (auto c : conVec) {
if (visited[c.A] && visited[c.B] && FindRoot(c.A, preArr) == FindRoot(c.B, preArr)) {
continue;
}
visited[c.A] = true;
visited[c.B] = true;
res += c.cost;
UnionRoot(c.A, c.B, preArr);
}
int rootVal = FindRoot(1, preArr);
for (int i = 2; i <= N; ++i) {
if (rootVal != FindRoot(i, preArr)) {
return -1;
}
}
return res;
}
int main()
{
vector<vector<int>> arr = {{1,2,5},{1,3,6},{2,3,1}};
cout << minimumCost(3, arr) << endl;
return 0;
}
class Solution {
private:
vector<int> fatherMap;
vector<int> sizeMap;
int getFather(int a){
int fa = fatherMap[a];
if(fa != a) fa = getFather(fa);
// 把并查集变扁平
fatherMap[a] = fa;
return fa;
}
int merge(int a, int b){
// 确认两个点为父节点,并且不相连
int fa = getFather(a), fb = getFather(b);
if(fa == fb) return sizeMap[fa];
if(sizeMap[fa] > sizeMap[fb]) {
// 当 b 所在的并查集元素较小时, 把 b 指向 a 所在的并查集
sizeMap[fa] += sizeMap[fb];
fatherMap[fb] = fa;
}
else {
sizeMap[fb] += sizeMap[fa];
fatherMap[fa] = fb;
}
return max(sizeMap[fa], sizeMap[fb]);
}
public:
int minimumCost(int N, vector<vector<int>>& conections) {
if(N == 1) return 0;
// 若城市个数大于 连接个数 + 1 不可能联通
if(N > conections.size() + 1) return -1;
// 初始化并查集
fatherMap.resize(N), sizeMap.resize(N);
for(int i=0; i<N; i++) {
fatherMap[i] = i;
sizeMap[i] = 1;
}
int res = 0, total = 0;
// 按照每条连接的权重排序
sort(conections.begin(), conections.end(),
[](vector<int>& a, vector<int>& b){ return a[2] < b[2]; });
for(int i=0; i<conections.size(); i++){
int fa = getFather(conections[i][0]-1), fb = getFather(conections[i][1]-1);
// 已经属于一个并查集了,不需要加入此连接
if(fa == fb) continue;
total = merge(fa, fb);
// 加上当前权重
res += conections[i][2];
// 通过返回值,可以提前终止迭代过程
if(total == N) return res;
}
return -1;
}
};
261. 以图辨树
题目
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lCEy2KqO-1634780909187)(pic/image-20211016192210607.png)]](https://img-blog.csdnimg.cn/f56cf99e64924c5eb3d113c91ff0ab58.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAT3JhbmdlIFd1,size_20,color_FFFFFF,t_70,g_se,x_16)
解答
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <algorithm>
using namespace std;
int FindRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
void UnionRoot(int a, int b, vector<int>& preArr)
{
int rootA = FindRoot(a, preArr);
int rootB = FindRoot(b, preArr);
if (rootA != rootB) {
preArr[rootB] = rootA;
}
}
bool validTree(int n, vector<vector<int>>& edges)
{
int len = edges.size();
if (len != n - 1) {
return false;
}
if (len == 0 && n == 1) {
return true;
}
vector<int> preArr(n, 0);
for (int i = 0; i < n; i++) {
preArr[i] = i;
}
vector<bool> used(n, false);
for (auto &e : edges) {
if (used[e[0]] && used[e[1]] && preArr[e[0]] == preArr[e[1]]) {
return false;
}
used[e[0]] = true;
used[e[1]] = true;
UnionRoot(e[0], e[1], preArr);
}
int rootVal = FindRoot(0, preArr);
for (int i = 1; i < n; i++) {
if (FindRoot(i, preArr) != rootVal) {
return false;
}
}
return true;
}
int main()
{
vector<vector<int>> arr = {{0,1}, {1, 2}, {2,3},{1,3}, {1,4}};
if(validTree(5, arr)) {
cout<<"1"<<endl;
} else {
cout<<"0"<<endl;
}
return 0;
}
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <algorithm>
using namespace std;
int FindRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
void UnionRoot(int a, int b, vector<int>& preArr)
{
int rootA = FindRoot(a, preArr);
int rootB = FindRoot(b, preArr);
if (rootA != rootB) {
preArr[rootB] = rootA;
}
}
bool validTree0(int n, vector<vector<int>>& edges)
{
int len = edges.size();
if (len != n - 1) {
return false;
}
if (len == 0 && n == 1) {
return true;
}
vector<int> preArr(n, 0);
for (int i = 0; i < n; i++) {
preArr[i] = i;
}
vector<bool> used(n, false);
for (auto &e : edges) {
if (used[e[0]] && used[e[1]] && preArr[e[0]] == preArr[e[1]]) {
return false;
}
used[e[0]] = true;
used[e[1]] = true;
UnionRoot(e[0], e[1], preArr);
}
int rootVal = FindRoot(0, preArr);
for (int i = 1; i < n; i++) {
if (FindRoot(i, preArr) != rootVal) {
return false;
}
}
return true;
}
bool validTree(int n, vector<vector<int>>& edges)
{
int len = edges.size();
if (len != n - 1) {
return false;
}
if (len == 0 && n == 1) {
return true;
}
vector<int> preArr(n, 0);
for (int i = 0; i < n; i++) {
preArr[i] = i;
}
vector<bool> used(n, false);
for (auto &e : edges) {
int rootA = FindRoot(e[0], preArr);
int rootB = FindRoot(e[1], preArr);
if (rootA == rootB) {
return false;
}
if (e[0] < e[1]) {
preArr[e[1]] = rootA;
} else {
preArr[e[0]] = rootB;
}
}
return true;
}
int main()
{
vector<vector<int>> arr = {{0,1}, {1, 2}, {2,3},{1,3}, {1,4}};
if(validTree(5, arr)) {
cout<<"1"<<endl;
} else {
cout<<"0"<<endl;
}
return 0;
}
1061. 按字典序排列最小的等效字符串
题目
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cl6huVya-1634781036967)(pic/1.png)]](https://img-blog.csdnimg.cn/b562974cf0bd415aa93ff6362cd44f0c.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAT3JhbmdlIFd1,size_20,color_FFFFFF,t_70,g_se,x_16)
解答
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
unordered_map<char, char> mp;
char FindRoot(char ch)
{
char son = ch;
while (mp[ch] != ch) {
ch = mp[ch];
}
while (son != ch) {
char tmp = mp[son];
mp[son] = ch;
son = tmp;
}
return ch;
}
void UnionRoot(char ch1, char ch2)
{
char root1 = FindRoot(ch1);
char root2 = FindRoot(ch2);
if (root1 != root2) {
if (root1 < root2) {
mp[root2] = root1;
} else {
mp[root1] = root2;
}
}
}
string smallestEquivalentString(string A, string B, string S)
{
int sizeA = A.size();
int sizeB = B.size();
if (sizeA != sizeB) {
return "";
}
for (int i = 0; i < sizeA; ++i) {
if (A[i] > B[i]) {
mp[B[i]] = B[i];
mp[A[i]] = B[i];
} else if (A[i] < B[i]) {
mp[A[i]] = A[i];
mp[B[i]] = A[i];
} else {
mp[A[i]] = A[i];
mp[B[i]] = B[i];
}
}
for (int i = 0; i < sizeA; ++i) {
UnionRoot(A[i], B[i]);
}
for (int i = 0; i < S.size(); ++i) {
if (mp.find(S[i]) != mp.end()) {
S[i] = mp[S[i]];
}
}
return S;
}
int main()
{
string s1 = "leetcode";//"parker";//"hello";
string s2 = "programs";//"morris";//"world";
string s3 = "sourcecode";//"parser";//"hold";
cout<<smallestEquivalentString(s1, s2, s3)<<endl;
return 0;
}
323. 无向图中连通分量的数目
题目
给定编号从 0 到 n-1 的 n 个节点和一个无向边列表(每条边都是一对节点),请编写一个函数来计算无向图中连通分量的数目。
示例 1:
输入: n = 5 和 edges = [[0, 1], [1, 2], [3, 4]]
0 ********3
|**********|
1 — 2 ** 4
输出: 2
示例 2:
输入: n = 5 和 edges = [[0, 1], [1, 2], [2, 3], [3, 4]]
0 *********4
| **********|
1 — 2 — 3
输出: 1
-
注意:
你可以假设在 edges 中不会出现重复的边。而且由于所以的边都是无向边,[0, 1] 与 [1, 0] 相同,所以它们不会同时在 edges 中出现。
解答
#include <iostream>
#include <vector>
using namespace std;
int FindRoot(int root, vector<int>& preArr)
{
int son = root;
while (root != preArr[root]) {
root = preArr[root];
}
while (son != root) {
int tmp = preArr[son];
preArr[son] = root;
son = tmp;
}
return root;
}
int countComponents(int n, vector<vector<int>>& edges)
{
vector<int> preArr(n, 0);
for (int i = 0; i < n; ++i) {
preArr[i] = i;
}
for (auto &e : edges) {
int root1 = FindRoot(e[0], preArr);
int root2 = FindRoot(e[1], preArr);
if (root1 == root2) {
continue;
}
preArr[root2] = root1;
}
int res = 0;
for (int i = 0; i < n; ++i) {
if (preArr[i] == i) {
res++;
}
}
return res;
}
int main()
{
vector<vector<int>> arr= {{0, 1}, {1, 2}, {2, 3}, {3, 4}};// {{0, 1}, {1, 2}, {3, 4}};
cout<<countComponents(5, arr)<<endl;
return 0;
}
924. 尽量减少恶意软件的传播
题目
难度困难63收藏分享切换为英文接收动态反馈
在节点网络中,只有当
graph[i][j] = 1
时,每个节点
i
能够直接连接到另一个节点
j
。
一些节点
initial
最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设
M(initial)
是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
如果从初始列表中移除某一节点能够最小化
M(initial)
, 返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
请注意,如果某个节点已从受感染节点的列表
initial
中删除,它以后可能仍然因恶意软件传播而受到感染。
示例 1:
输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1]
输出:0
示例 2:
输入:graph = [[1,0,0],[0,1,0],[0,0,1]], initial = [0,2]
输出:0
示例 3:
输入:graph = [[1,1,1],[1,1,1],[1,1,1]], initial = [1,2]
输出:1
提示:
-
1 < graph.length = graph[0].length <= 300
-
0 <= graph[i][j] == graph[j][i] <= 1
-
graph[i][i] == 1
-
1 <= initial.length < graph.length
-
0 <= initial[i] < graph.length
解答
/**
* 从初始列表中删除一个节点。如果移除这一节点将最小化 M(initial),则返回该节点
* 解题思路 [阅读理解]
* 1、理解题意:题目描述很不易理解,首先理解输入graph、initial; 输出 求初始列表中的一个节点,移除这一节点将最小化感染
* a. 输入graph表示每个节点与其他节点的联通情况,以题目中示例一举例 graph = [[1,1,0],[1,1,0],[0,0,1]] 图如下图
* nodeId 0 1 2
* ————|————————————
* graph = 0 | 1, 1, 0
* 1 | 1, 1, 0
* 2 | 0, 0, 1
* 表示有三个节点,节点序号分别为 0,1,2.在节点网络中,只有当 graph[i][j] = 1 时,每个节点 i 能够直接连接到另一个节点 j
* 比如 0号节点可以与 1、2号节点有联通关系,那么 0 号节点与 1 号节点联通则可以表示为 graph[0][1] = 1;
* 0 号节点与 2 号节点不联通则可以表示为 graph[0][2] = 0;
* 节点自身与自身是联通的,也就是图中 graph[0][0] == graph[1][1] == graph[2][2] == 1
* 那么 graph 画图表示为下图, 0 与 1 相连, 没有节点与 2 相连
* 0
* /
* 1 2
* b. 输入initial表示初始被感染的节点,以题目中示例一举例 initial = [0,1] 表示一开始 0号节点与1号节点被感染了
* c. 输出 求初始列表中的一个节点,移除这一节点将最小化感染,注意这里“移除”的真正含义是,把该节点设置为未感染状态,
* 以题目中示例一举例,初始状态0、1被感染,那么我们不论移除0还是移除1,两个节点都会被感染,因为0 和 1 是联通的,移除一个后会被另一个重新传染,
* 要注意题目中最后一句话,“某个节点已从受感染节点的列表 initial 中删除,它以后可能仍然因恶意软件传播而受到感染。”
* d. 题目中其他条件理解,“如果有多个节点满足条件,就返回索引最小的节点”,还是以题目中示例一举例,我们知道从 输入initial
* 初始状态0、1被感染,那么我们不论移除0还是移除1,两个节点都会被感染
* 也就是移除 0 后感染的节点为 0(被1传染),1
* 也就是移除 1 后感染的节点为 0,1(被0传染)
* 这种情况下,我们直接返回 索引最小的节点 0,注意这儿的索引只的是节点的索引
* 上述就是对题意的理解,搞清楚题意后再去看官方解题思路便豁然开朗
*
*
* @param graph 节点网络
* @param initial 最初被恶意软件感染的节点
* @return 将最小化 M(initial)的节点
*/
class Solution {
public:
int FindRoot(int root, vector<int>& preArr)
{
while (root != preArr[root]) {
root = preArr[root];
}
return root;
}
void MergeRoot(int x, int y, vector<int>& preArr, vector<int>& size)
{
int rootX = FindRoot(x, preArr);
int rootY = FindRoot(y, preArr);
if (rootX == rootY) {
return;
}
if (size[rootX] < size[rootY]) {
swap(rootX, rootY);
}
preArr[rootY] = rootX;
size[rootX] += size[rootY];
}
int GetSize(int x, vector<int>& preArr, vector<int>& size)
{
return size[FindRoot(x, preArr)];
}
int minMalwareSpread(vector<vector<int>>& graph, vector<int>& initial) {
int n = graph.size();
vector<int> preArr(n, 0);
vector<int> size(n, 1);
for (int i = 0; i < n; ++i) {
preArr[i] = i;
}
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (graph[i][j] == 1) {
MergeRoot(i, j, preArr, size);
}
}
}
vector<int> cnt(n, 0);
for (auto i : initial) {
cnt[FindRoot(i, preArr)]++;
}
// 大于1的话,删哪个都会被再次感染
int res = INT_MAX;
int resSize = -1;
for (int i : initial) {
int tmp = FindRoot(i, preArr);
if (cnt[tmp] == 1) {
int coverSize = GetSize(tmp, preArr, size);
if (coverSize > resSize || (coverSize == resSize && tmp < res)) {
resSize = coverSize;
res = i;
}
}
}
if (res == INT_MAX) {
for (auto i : initial) {
res = min(res, i);
}
}
return res;
}
};