将单字的拼音转换为一个独特的整数进行编码加入模型中,使模型掌握拼音信息。并且在预测阶段通过拼音生成topk的备选单字,考虑不同位置topk汉字之间的转移得分,最终解码获得最优路径。
模型结构

(1)汉字编码器: Roberta
(2)
Pinyin Enhanced Candidate Generator 拼音加强的候选汉字生成器
pi是拼音embeding(将不含声调的拼音当作一个整体,进行编码),wi是汉字embeding,hi是roberta输出

vm是第m个候选汉字对应的可训练参数。根据(5)计算出来的得分,选择top k个候选汉字(k应该设置成多少呢?如果采样不对,就一定无法修正了)
(3)计算相邻候选之间得得分(图中右半部分)
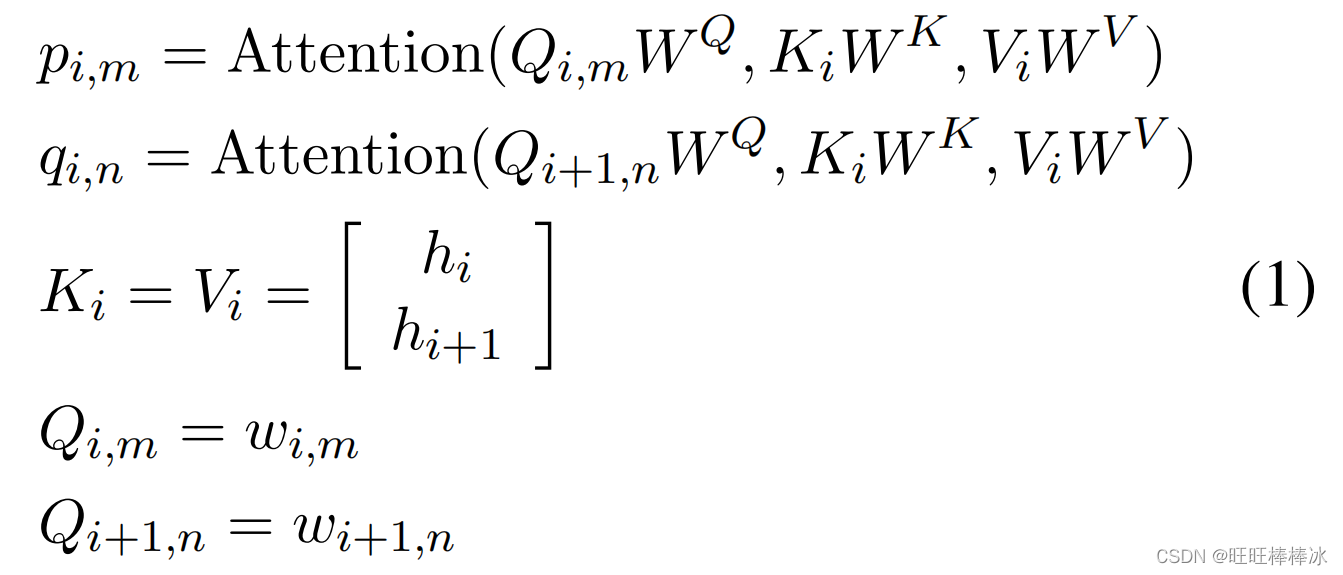
i是汉字位置索引,m,n分别是第i个位置与第i+1个位置的候选汉字索引
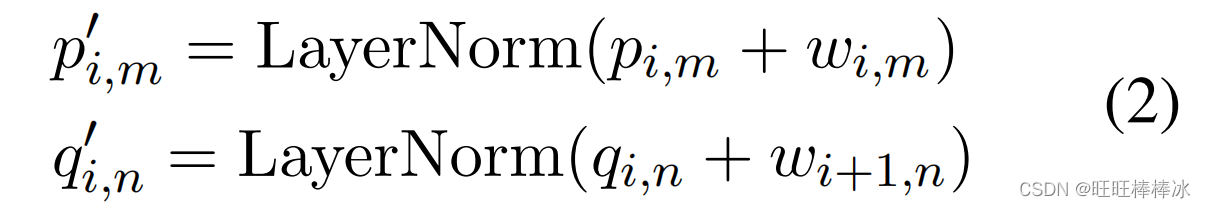
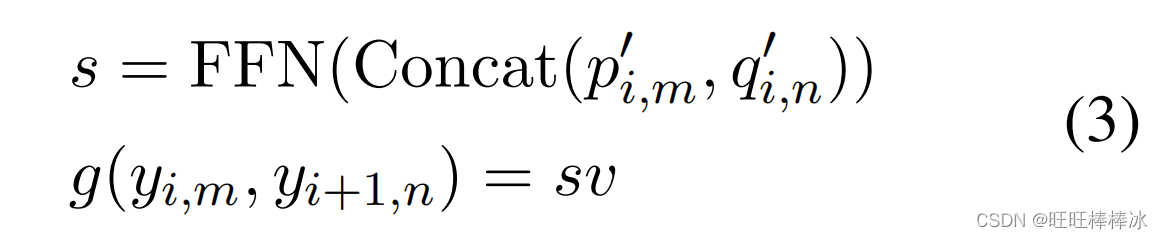
通过以上方式,计算出了第i个位置第m个候选汉字与第i+1个位置第n个候选汉字之间的得分,V是可训练的参数。
每个位置有k个候选汉字,所以可能的路径就是k的n次方,每条路径的得分如下:
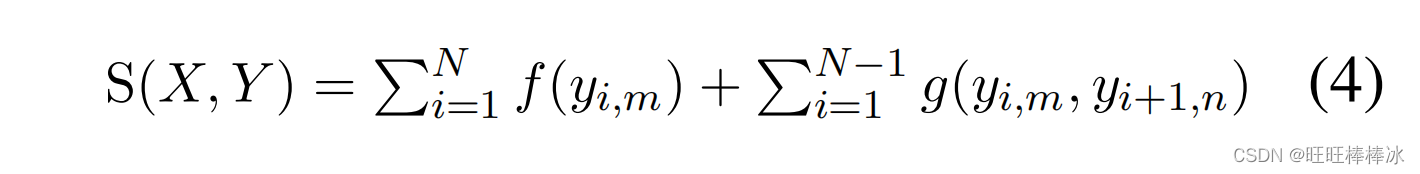
y为对应位置的汉字,前面一部分是预测得分,后面一部分是考虑相邻汉字输出的得分。
最终选择得分最高的路径。
版权声明:本文为ltochange原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。