整理自:http://blog.echen.me/2011/07/18/introduction-to-restricted-boltzmann-machines/
0x01 intro
假设我们让一群用户给一堆电影进行评分(满分100)。在经典的因子分析中,我们可以试着用一堆潜在因素来解释用户和因子的关系。比如,像《星球大战》和《指环王》这样的电影和科幻高度相关,而《Wall-E》和《玩具总动员》的用户可能与潜在的“皮克斯”因素有很强的联系。
限制玻尔兹曼机可以理解为是因子分析的二进制版本,比如一个电影有没有科幻/搞笑/动作元素啥的。用户的输入只是它喜不喜欢啥电影,然后输出告诉我们这个用户可能是二次元/科幻/blablabla,相当于是用特定电影的喜好与否给用户画像。
技术上理解,受限玻尔兹曼机是随机神经网络。它由两层东西构成:
- 一层可视化层(对电影的评价)
- 一层隐藏层(这个用户喜欢啥风格)
当然,隐藏层和可见层的每个神经元都有偏置项。
一个典型的例子如下所示:
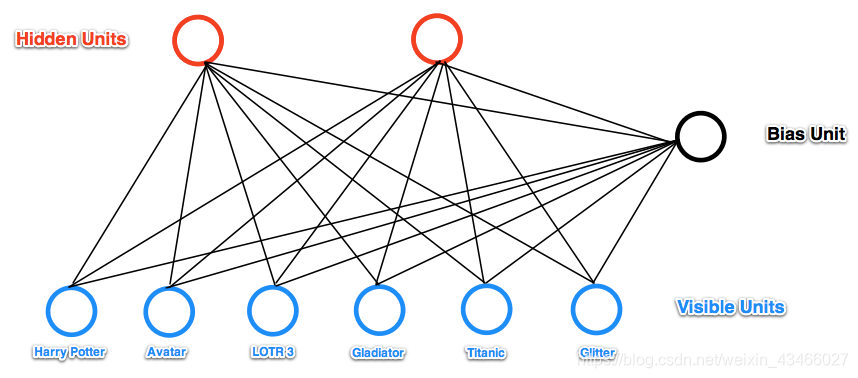
(这里,右边的那个黑点子是偏置项)
0x02 工作原理
和神经网络的全连接类似,受限玻尔兹曼机的两层之间也是全连接的,但是层内的神经元是不连接的。下面,我们来介绍一下受限玻尔兹曼机的使用原理。
以上图所示,我们输入用户对六个电影的打分结果(0-100分)。然后,我以分数百分比为概率对输入进行0-1取样,比如用户给哈利波特打90分,咱们就以90%的可能性把这个点取成1,10%的可能性取成0。
对每个输入点取过样之后,我们和神经网络前向传播一样,计算一个线性组合
∑
w
i
j
x
j
+
b
i
\sum w_{ij} x_j + b_i
∑
w
i
j
x
j
+
b
i
,这里
x
j
x_j
x
j
就是我们的每个输入,
b
i
b_i
b
i
是输出节点的bias。
得到的线性组合扔到sigmoid函数里,得到一个0-1之间的连续值。我们再以这个值为概率做一手前面说的0-1取样。
(概括一手,如果
w
i
j
w_{ij}
w
i
j
是正的,那么前后两个神经元就想共享同一个状态,比如《流浪地球》和科幻之间的
w
i
j
w_{ij}
w
i
j
肯定得是个超大的正数)
0x03 学习权重
可以发现,这里对网络的输出起作用的就是权重和偏置bias了。假设我们的测试用例是1行6列的二进制向量。在每个训练epoch,做下面的操作:
- 把测试用例扔到输入层里。
- 正向传播,并且以sigmoid函数值对每个隐藏层神经元做取样。
-
计算一下
ei
j
e_{ij}
e
i
j
,其定义为输入层第
ii
i
个单元和输出层第
jj
j
个单元是否都被激活(即值为1)。都被激活则为1,否则为0. - 下面,我们把3中隐藏层算出的值当成隐藏层的输入,根据这个输入向可见层做一个传播,做法仍然是线性组合之后再套一个sigmoid函数,只不过和2中的方向是反的。
-
再计算一个新的
fi
j
f_{ij}
f
i
j
,定义和3中类似。 -
更新:
wi
j
=
w
i
j
+
γ
(
e
i
j
−
f
i
j
)
w_{ij} = w_{ij} + \gamma (e_{ij} – f_{ij})
w
i
j
=
w
i
j
+
γ
(
e
i
j
−
f
i
j
)
这个步骤叫对比散度(contrastive divergence),但是本质上还是近似梯度下降。
0x04 why?
这里就放一个直观的理解:
-
ei
j
e_{ij}
e
i
j
表示的是我们希望网络学到的东西,学到哪些东西是要激活的。 -
在反向传播的阶段,RBM只是根据咱们正向传播的假设来生成可见层的值。
fi
j
f_{ij}
f
i
j
就表示没有固定输入的情况下测量网络本身生成的训练样本。
一个特殊的情况是,假设根据隐藏层构建的东西和原本输入的东西严格相等,这个时候网络就不用更新了,观察e和f,则有e和f严格相等。