|
|
|
掌握SQL程序设计基本规范,熟练运用SQL语言实现数据基本查询,包括单表查询,分组统计查询和连接查询。 |
|
计算机、MySQL,Navicat |
|
针对TPC-H数据库设计各种单表查询SQL语句、分组统计查询语句;设计单个表针对自身的连接查询,设计多个表的连接查询。理解和掌握SQL查询语句各个子句的特点和作用,按照SQL程序设计规范写出具体的SQL查询语句,并调试通过。 说明:简单地说,SQL程序设计规范包含SQL关键字大写、表名、属性名、存储过程名等标识符大小写混合,SQL程序书写缩进排列等编程规范。
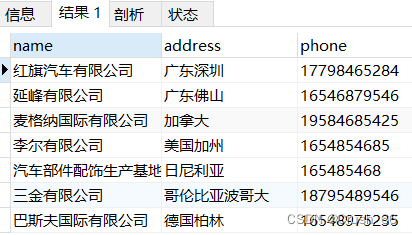
1)单表查询(实现投影操作) SELECT name,address,phone FROM Supplier;
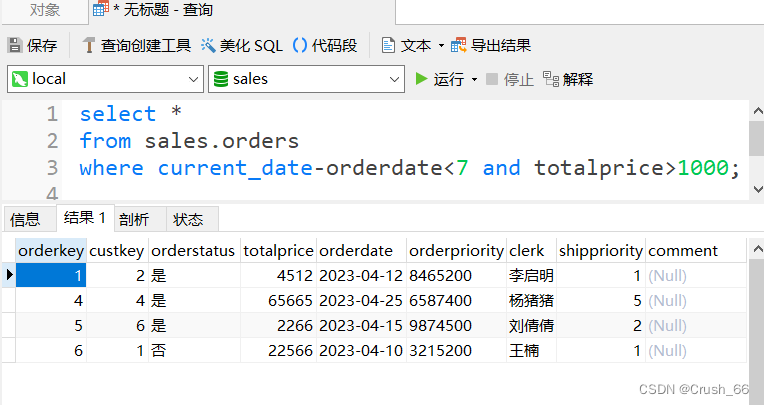
2)单表查询(实现选择操作) SELECT* FROM sales.orders
WHERE current_date-orderdate<7 AND totalprice>1000;
3)不带分组过滤条件的分组统计查询 统计每个顾客的订购金额 SELECT C.custkey,SUM(O.totalprice)/*对每个组,作用聚集函数sum*/ FROM customer C, orders O WHERE C.custkey=O.custkey /*两个表的链接条件*/ GROUP BY C.custkey; /*按照c.custkey分组*/
4)带分组过滤条件的分组统计查询 查询订单平均金额超过1000元的顾客编号及其姓名。 SELECT C.custkey,c.name /*对每个组,作用聚集函数sum*/ FROM customer C,orders O WHERE C.custkey=O.custkey /*两个表的链接条件*/ GROUP BY C.custkey; /*按照c.custkey分组*/ HAVING AVG(orders.totalprice)>1000;
5)单表自身连接查询 查询与“红旗汽车有限公司”在同一国家的供应商编号、名称和地址信息。 SELECT S.suppkey,S.name,S.address FROM supplier S,supplier F/*单表自连接*/ WHERE F.name=’红旗汽车有限公司’ AND S.nationkey=F.nationkey/*连接条件*/
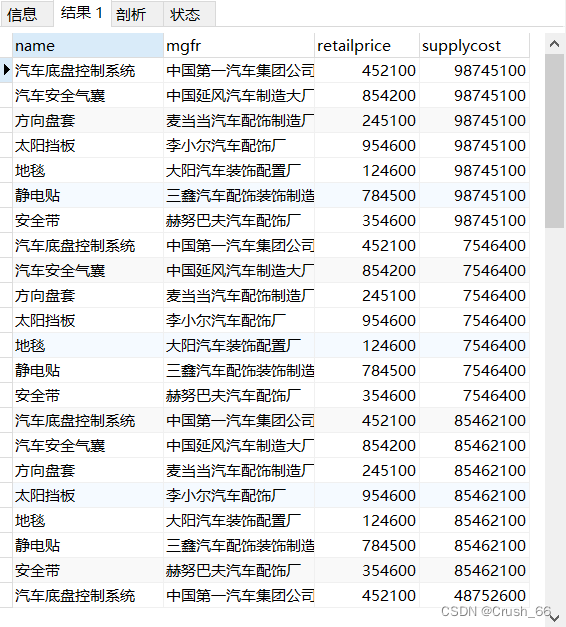
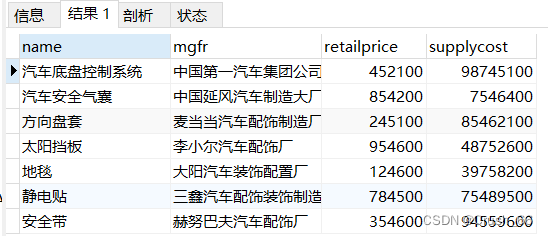
6)两表连接查询(普通连接) 查询供应价格大于零售价格的零件名、制造商名、零售价格和供应价格。 SELECT P.name,P.mgfr,P.retailprice,S.supplycost FROM part P,partsupp S WHERE P.retailprice<S.supplycost;
(7)两表连接查询(自然连接) 查询供应价格大于零售价格的零件名、制造商名、零售价格和供应价格。 SELECT P.name,P.mgfr,P.retailprice,S.supplycost FROM part P,partsupp S/*两表自然连接*/ WHERE P.partkey=S.partkey AND P.retailprice<S.supplycost;/*连接条件和限定条件*/
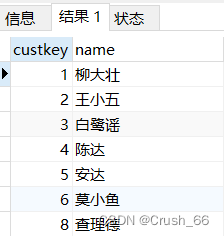
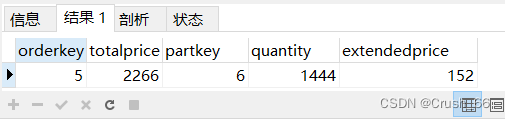
(8)三表连接查询 查询顾客“莫小鱼”订购的订单编号、总价及其订购的零件编号、数量和明细价格。 SELECT O.orderkey,O.totalprice,Lpartkey,L.quantity,L.extendedprice FROM customer C,lineitem L,orders O/*三表连接*/ WHERE C.name=”莫小鱼” AND L.orderkey=O.orderkey AND C.custkey=O.custkey;
问题:查询结果不准确或不完整 解决方法:在SQL语句中,常常会出现语法错误,例如拼写错误、大小写错误、语句不完整等。此时可以仔细检查SQL语句,确保语法正确。在进行查询操作时,需要注意数据类型的匹配问题,例如字符型、数值型、日期型等。如果数据类型不匹配,可能会导致查询结果不准确或报错。 问题:多表连接失败 解决方法:在进行多表查询时,需要使用多表关联查询。在使用多表关联查询时,需要注意关联的表和字段,避免查询结果不准确或报错。 |
|
(1) 不在GROUP BY子句出现的属性,是否可以出现在SELECT子句中?请举例并上机验证 在GROUP BY子句中指定的属性,会按照该属性的值进行分组,而不在GROUP BY子句中指定的属性,会按照任意值进行分组。 因此,如果不在GROUP BY子句中出现的属性出现在SELECT子句中,就需要指定该属性的聚合函数,例如SUM、AVG、MAX、MIN、COUNT等。 下面是一个例子,假设有一个销售数据表sales,包含以下字段:id、product、price、quantity、date。现在要查询每个产品的总销售额和平均销售额。 查询语句如下: 在这个查询语句中,GROUP BY子句指定了按照product属性进行分组,而SELECT子句中出现了不在GROUP BY子句中的属性price和quantity。由于price和quantity不是聚合函数,因此需要使用SUM和AVG函数对它们进行聚合计算,得出每个产品的总销售额和平均销售额。 上机验证可以使用MySQL等关系型数据库管理系统进行操作。 (2)where和having的差别 “having”和”where”是SQL语言中的两个关键字,用于筛选和过滤数据。
假设有一个名为 “orders” 的表,其中包含以下列:订单编号、客户编号、订单日期和订单总额。现在我们想要查询客户编号为 123 的客户在 2021 年之前的订单总额。
|