说在前面的话
你或许找了很久的方案来到了这里,当你看到本文章时,我默认你已经发现,淘宝的反扒措施是 webdriver和chromedriver的识别。所以我不会贴过多图片,不讲分析思路,直接给你鱼,文章最后直接上全部代码demo。
若帮助到你了,转发请注明出处,若阿里巴巴的朋友发现,请联系我删帖,谢谢。
背景
简单说下背景,最近某厂为了818,双11,12等需要分析友商数据,做竞价比较。所以就让研究抓取淘宝商品信息,百度资料博客一大堆,屁用都没有,淘宝在7月左右就必须要登陆才能进入商品页了,所以登陆淘宝是爬取数据的第一道门槛,然后就看到了滑块验证,selenium + chromedriver 模拟用户登陆。
然后
想法很简单,现实很残酷,淘宝又不都是傻子。滑块被检验出来为 webdriver 驱动,或许你已经看过用fiddler工具 或者 mitmproxy 代理设置response,拦截index.js 118.js 115.js修改js,加上webdriver 的参数为false.目的就是为了改window.navigator.webdriver属性。再后来支付宝登陆??微博登陆???
思路ok,方法屁用。
两个问题入手
1,跳过检测特有标识$cdc_lasutopfhvcZLmcfl
2,跳过检验window.navigator.webdriver 为false
破解(两步缺一不可)
1:改chromedriver的全量标识。
mac 和 linux 很好改,自己看,直接略过,我就来个别人都避重就轻的不说的windows的修改方法。
现根据自己的谷歌浏览器版本下载对应驱动:
selenium 谷歌驱动下载
,放到python 的Script目录下。
先把exe文件.bak 备份一波
下载一个nodepadd++ 编辑器,右击打开 chromedriver.exe ,一群乱码,莫慌,莫随意打空格或者其他操作,可能会导致文件损坏。打开it,如下图(本文章计划唯一的一张图),ctrl + F, 输入 $cdc ,好了,就把下面那 红色框住的那一坨改了,就是它,淘宝就是检测的它。fuck…..
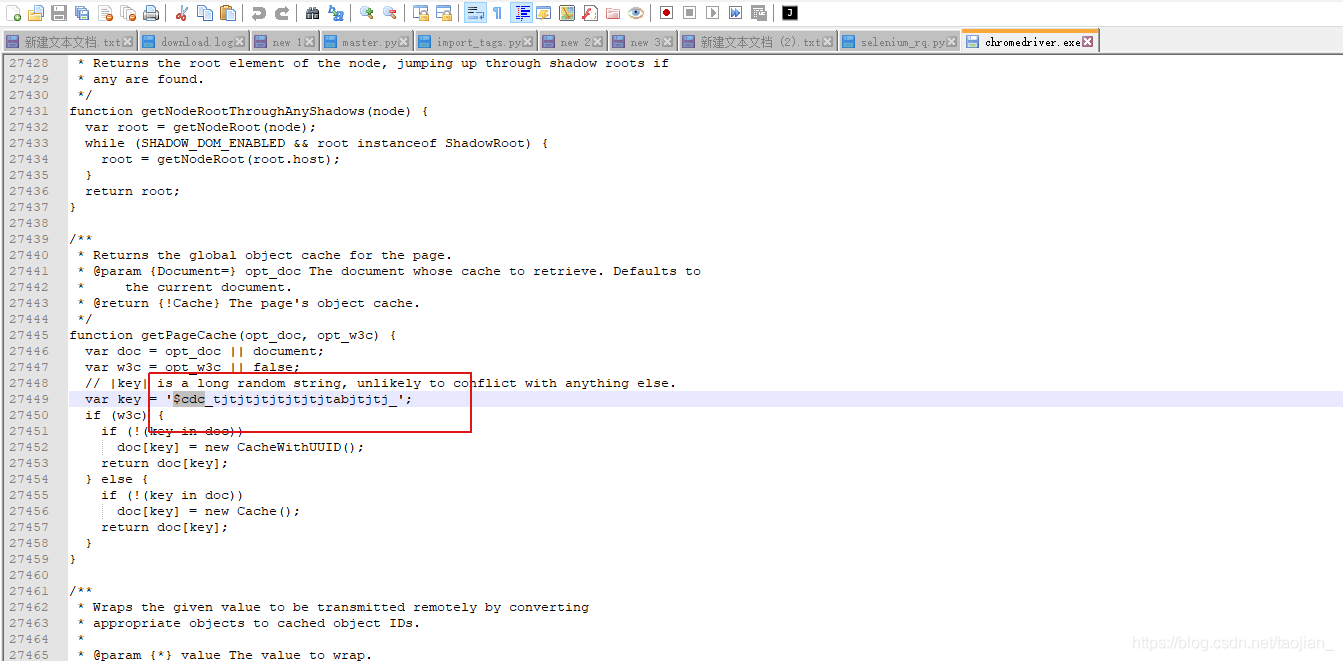
the most 恶心的地方来了,你以为改过了就完事了???????fuck,下面划横线,说重点的事情三遍。
我的改成自己的名字了,别人debug的时候,能装个逼,$cdc_tjtjtjtjtjtjtjtabjtjtj_
修改后的字符长度要和原来的一致!
修改后的字符长度要和原来的一致!
修改后的字符长度要和原来的一致!
改成 $cdc_fuck_ $cdc_fuckfuck_ 都不行。好好数数多少位。
2:window.navigator.webdriver 为false
自己本地玩,弄个mitmproxy,拦截下,修改js没问题,代码如下:
from mitmproxy import ctx
# 所有的请求都会经过request
def request(flow):
info = ctx.log.info
# info(flow.request.url)
# info(str(flow.request.headers))
# info(str(flow.request.cookies))
# info(flow.request.host)
# info(flow.request.method)
# info(str(flow.request.port))
# info(flow.request.scheme)
# print('=' * 30)
# print(flow.request.method, ":", flow.request.url)
# print('=' * 30)
def response(flow):
info = ctx.log.info
if 'um.js' in flow.request.url or '118.js' in flow.request.url:
# 屏蔽selenium检测
flow.response.text = flow.response.text + \
'Object.defineProperties(navigator,{webdriver:{get:() => false}}); '
然而并没有什么卵用,要是linux机器多,部上去跑也麻烦。直接一行代码搞定
option = webdriver.ChromeOptions()
#开发者模式的开关,设置一下,打开浏览器就不会识别为自动化测试工具了
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(chrome_options=option)
总结 (代码)
本来某厂不能写博客连外网,没办法,CSDN之类网站的找个问题,都他么原封不动的复制下来,没人管它对不对,心累。共享学习心得分享资源是好事,希望大家共同努力一起进步。
我只写了一个demo,有心的同学可以自己改成class类,增加元素加载情况判断等等。本文目的只为破解滑块验证。
最后扔个炸弹,若是新设备电脑,首次登陆进去之后,有一个可爱的人机交互验证,它的问题是“请选出你最近购买的商品”,哈哈哈,傻逼了吧。。 哈哈哈,爬虫之路任重而道远,各位珍重。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains
import time
option = webdriver.ChromeOptions()
option.binary_location = r'E:\Chrome\Application\chrome.exe'
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# option.add_argument("--proxy-server=127.0.0.1:8080")
# 设置无头加载
# option.add_argument('--headless')
# 设置无图片模式
# prefs = {"profile.managed_default_content_settings.images": 2}
# option.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(chrome_options=option)
driver.maximize_window()
status = driver.get("https://login.taobao.com/member/login.jhtml")
print(status)
# pass
# 删除原来的cookie
driver.delete_all_cookies()
# cookie = "thw=cn; cna=yFJuFf/jBmkCAbRt3g+PNikw; v=0; t=ce6433b7d755f402b91d17670f77a2ef; sg=819; csg=d16db728; existShop=MTU2MTYwNzg5MQ%3D%3D; tracknick=%5Cu6843%5Cu6843520328; lgc=%5Cu6843%5Cu6843520328; dnk=%5Cu6843%5Cu6843520328; tg=0; mt=ci=9_1; uc1=cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D&cookie21=VT5L2FSpdet1FS8C2gIFaQ%3D%3D&cookie15=UIHiLt3xD8xYTw%3D%3D&existShop=false&pas=0&cookie14=UoTaGduh3ZQTWQ%3D%3D&tag=8&lng=zh_CN; _nk_=%5Cu6843%5Cu6843520328; _tb_token_=3ab35ef7b6b31; isg=BNrad6CZU8E-BN6SQyYSGTTBK4A8o13CtG3R4uRTgm04V3qRzJuu9aClIyNLgtZ9; l=bBNeS67nv7dTPyOoBOCanurza77OSIRYYuPzaNbMi_5LE6T_Z8bOkYnakF96Vj5RsUYB4ATie6p9-etkZ"
# c = cookie.split(';')
# ck = {}
# for i in c:
# key = i.split('=')[0].strip()
# val = i.split('=')[1].strip()
# ck.setdefault(key, val)
# 携带cookie打开
# driver.add_cookie(ck)
# 设置显示等待
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.ID, 'J_Quick2Static')))
# 打开淘宝二维码
i = driver.find_element_by_id("J_Quick2Static")
i.click()
user = driver.find_element_by_id("TPL_username_1")
user.send_keys('用户名')
password = driver.find_element_by_id("TPL_password_1")
password.send_keys('密码')
# 设置显示等待
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.ID, 'nc_1_n1z')))
bb = driver.find_element_by_id("nc_1_n1z")
# ActionChains(driver).click_and_hold(bb).perform()
# for x in range(258):
# ActionChains(driver).drag_and_drop_by_offset(
# xoffset=x, yoffset=0).perform()
# time.sleep(0.02)
bar_element = driver.find_element_by_id('nc_1_n1z')
ActionChains(driver).drag_and_drop_by_offset(bar_element, 258, 0).perform()
time.sleep(0.5)
ActionChains(driver).release().perform()
# 点击提交按钮
butt = driver.find_element_by_id('J_SubmitStatic')
butt.click()
driver.get("https://www.taobao.com")
# 设置显示等待
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located(
(By.CLASS_NAME, 'search-combobox-input-wrap')))
search = driver.find_element_by_class_name('search-combobox-input')
search.send_keys("苏宁易购")
search_butt = driver.find_element_by_class_name('btn-search')
search_butt.click()
print(driver.page_source)