本文总结在牛客刷题过程中,遇到的错题及相关的高赞评论解析。
数据结构
正确答案: C 你的答案: C
A、O(1)
B、O(n)
C、O(1og2n)
D、O(n2)
辅助存储空间 = 时间复杂度
额外存储空间 = 空间复杂度
快速排序对待排序序列得划分大约是log
2
n次,因为快速排序是通过递归算法来实现的,递归深度大约是log
2
n,所以所需得辅助空间为log
2
n
正确答案: B D 你的答案: B D
A、基数排序
B、冒泡排序
C、桶排序
D、希尔排序
1、基于比较的排序算法有:(1)直接插入排序;(2)冒泡排序;(3)简单选择排序;(4)希尔排序;(5)快速排序;(6)堆排序;(7)归并排序。
2、基数排序、桶排序都属于分配式排序,且都是稳定排序算法。
正确答案: C 你的答案: C
A、堆排序
B、归并排序
C、冒泡排序
D、希尔排序
笔记:递归时间可能长于比较时间
正确答案: D 你的答案: D
A、如果一个问题可以找到一个能在多项式的时间里解决它的算法,那么这个问题就属于P问题
B、NP问题是指可以在多项式的时间里验证一个解的问题
C、所有的P类问题都是NP问题
D、NPC问题不一定是个NP问题,只要保证所有的NP问题都可以约化到它即可
P: 能在多项式时间内解决的问题
NP: 不能在多项式时间内解决或不确定能不能在多项式时间内解决,但能在多项式时间验证的问题
NPC: NP完全问题,所有NP问题在多项式时间内都能约化(Reducibility)到它的NP问题,即解决了此NPC问题,所有NP问题也都得到解决。
NP hard:NP难问题, 所有NP问题在多项式时间内都能约化(Reducibility)到它的问题(不一定是NP问题)。
int main(){fork()||fork();}共创建几个进程:
正确答案: C 你的答案: C
A、1
B、2
C、3
D、4
E、5
F、6
fork()
给子进程返回一个零值,而给父进程返回一个非零值;
在main这个主进程中,首先执行
fork()|| fork()
, 左边的fork()返回一个非零值,根据
||
的短路原则,前面的表达式为真时,后面的表达式不执行,故包含main的这个主进程创建了一个子进程,由于子进程会复制父进程,而且子进程会根据其返回值继续执行,就是说,在子进程中,
fork()||fork()
这条语句左边表达式的返回值是0, 所以
||
右边的表达式要执行,这时在子进程中又创建了一个进程,即main进程->子进程->子进程,一共创建了3个进程。
操作系统
以下哪个命令用于查看tar(backup.tar)文件的内容而不提取它?()
正确答案: B 你的答案: B
A、tar -xvf backup.tar
B、tar -tvf backup.tar
C、tar -svf backup.tar
D、none of these
- *.tar 用 tar –xvf 解压
- *.gz 用 gzip -d或者gunzip 解压
- *.tar.gz和*.tgz 用 tar –xzf 解压
- *.bz2 用 bzip2 -d或者用bunzip2 解压
- *.tar.bz2用tar –xjf 解压
- *.Z 用 uncompress 解压
- *.tar.Z 用tar –xZf 解压
- *.rar 用 unrar e解压
- *.zip 用 unzip 解压
正确答案: D 你的答案: D
A、指令就是命令,它用来规定CPU执行什么操作
B、指令是构成程序的基本单位,程序是由一连串指令组成的
C、指令采用二进位表示
D、指令一般由4个部分组成
指令一般由两部分组成:
操作码:该指令完成操作的类型或性质
地址码:操作对象的地址
正确答案: D 你的答案: D
A、挂起队列
B、阻塞队列
C、就绪队列
D、后备队列
高级调度:从后备作业队列(作业控制块)中将作业调入进就绪进程队列,所以作业控制块中存放的是后背作业队列。
中级调度:是为了提高内存的使用率,将一些暂时不能运行的进程从内存移动到外存上去,即内存外出不断交换,所以中级调度会涉及到虚拟存储器。暂时不能运行的进程,由就绪挂起队列,阻塞挂起队列。而阻塞队列里的进程会由于等待时间过长自动调入到阻塞挂起队列里面去。
低级调度(短程调度)分两类,非抢占式调度和抢占式调度,从就绪进程队列中选取合适进程送到CPU上运行。
正确答案: A 你的答案: A
A、摒弃互斥条件
B、摒弃请求和保持条件
C、摒弃不剥夺条件
D、摒弃环路等待条件
-
互斥条件:一个资源每次只能被一个进程使用。
不可破坏
-
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
一次性分配:要么全给,要么啥也不给。
-
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
设置优先级,高优先级可要求低优先级让出资源。
-
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
对资源进行编号,按照编号顺序申请访问
正确答案: C 你的答案: C
A、交互性
B、多路性
C、成批性
D、独占性
分时系统具有多路性、交互性、独占性和及时性的特征。
多路性指,伺时有多个用户使用一台计算机,宏观上看是多个人同时使用一个CPU,微观上是多个人在不同时刻轮流使用CPU。
交互性是指,用户根据系统响应结果进一步提出新请求(用户直接干预每一步)。
独占性是指,用户感觉不到计算机为其他人服务,就像整个系统为他所独占。
及时性指,系统对用户提出的请求及时响应。
实时操作系统
基本特征:及时性,可靠性
正确答案: A 你的答案: A
A、总线是用于连接CPU、内存、外存和各种I/O设备并在它们之间传输信息的一组共享的传输线及其控制电路
B、I/O总线是用于连接CPU和内存的总线
C、CPU总线是连接内存和I/O设备(包括外存)的总线
D、计算机总线中只包含CPU总线
总线按功能和规范可分为五大类型:
- 数据总线(Data Bus):在CPU与RAM之间来回传送需要处理或是需要储存的数据。
- 地址总线(Address Bus):用来指定在RAM(Random Access Memory)之中储存的数据的地址。
- 控制总线(Control Bus):将微处理器控制单元(Control Unit)的信号,传送到周边设备,一般常见的为USB Bus和1394 Bus。
- 扩展总线(Expansion Bus):可连接扩展槽和电脑。
- 局部总线(Local Bus):取代更高速数据传输的扩展总线。
数据库
正确答案: A C 你的答案: A C
A、START TRANSACTION
B、START
C、BEGIN
D、BEIGN TRANSACTION
- BEGIN或START TRANSACTION;显示地开启一个事务
- COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改称为永久性的
- ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改
- SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT
- RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常
- ROLLBACK TO identifier;把事务回滚到标记点
- SET TRANSACTION;用来设置事务的隔离级别。InnoDB存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。
正确答案: D 你的答案: D
A、数据结构化
B、数据的冗余度小
C、较高的数据独立性
D、程序的标准化
数据库系统的特点 数据结构化 数据共享性高,冗余度低,易扩充 数据独立性高
下面有关sql 语句中 delete truncate的说法正确的是?()
正确答案: A C 你的答案: A C
A、论清理表数据的速度,truncate一般比delete更快
B、truncate命令可以用来删除部分数据。
C、truncate只删除表的数据不删除表的结构
D、delete能够回收高水位
- 处理效率:drop>trustcate>delete
- drop删除整个表;trustcate删除全部记录,但不删除表;delete删除部分记录
- delete不影响所用extent,高水线保持原位置不动;trustcate会将高水线复位。
计算机网络
正确答案: A D 你的答案: A D
A、1**:这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束
B、3**:表示服务端无法响应
C、4**:表示服务端错误
D、5**:表示服务器端错误
1XX(信息状态码)接受请求正在处理
2XX(成功状态码) 请求正常处理完毕
3XX(重定向状态码) 需要附加操作已完成请求
4XX(客户端错误状态码) 服务器无法处理请求
5XX(服务器错误状态码) 服务器处理请求出错
正确答案: C 你的答案: C
A、应用层
B、表示层
C、会话层
D、传输层
第一层:物理层
第二层:数据链路层 802.2、802.3ATM、HDLC、FRAME RELAY
第三层:网络层 IP、IPX、APPLETALK、ICMP
第四层:传输层 TCP、UDP、SPX
第五层:会话层 RPC、SQL、NFS 、X WINDOWS、ASP
第六层:表示层 ASCLL、PICT、TIFF、JPEG、 MIDI、MPEG
第七层:应用层 HTTP、FTP、SNMP等
Java
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
public void bark(){
System.out.println("狗可以吠叫");
}
}
public class TestDog{
public static void main(String args[]){
Animal a = new Animal();
Animal b = new Dog();
a.move();
b.move();
b.bark();
}
}
正确答案: D 你的答案: D
A、 动物可以移动
狗可以跑和走
狗可以吠叫
B、 动物可以移动
动物可以移动
狗可以吠叫
C、 运行错误
D、 编译错误
编译看左边,运行看右边。 父类型引用指向子类型对象,无法调用只在子类型里定义的方法
正确答案: D 你的答案: D
A、一旦一个对象成为垃圾,就立刻被收集掉。
B、对象空间被收集掉之后,会执行该对象的finalize方法
C、finalize方法和C++的析构函数是完全一回事情
D、一个对象成为垃圾是因为不再有引用指着它,但是线程并非如此
以前我是堆,你是栈
你总是能精准的找到我,给我指明出路
后来有一天我明白了
我变成了栈,你却隐身堆海
我却找不到你了,空指针了我不愿意如此,在下一轮full gc前
我找到了object家的finalize
又找到了你,这次我不会放手在世界重启前,一边躲着full gc一边老去
1、在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行。
2、
一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法, 并且在
下一次
垃圾回收动作发生时,才会
真正的
回收对象占用的内存(《java 编程思想》)
3、在C++中,对象的内存在哪个时刻被回收,是可以确定的,在C++中,析构函数和资源的释放息息相关,能不能正确处理析构函数,关乎能否正确回收对象内存资源。
在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行
,在java中,所有的对象,包括对象中包含的其他对象,它们所占的内存的回收都依靠垃圾回收器,因此不需要一个函数如C++析构函数那样来做必要的垃圾回收工作。当然存在本地方法时需要finalize()方法来清理本地对象。在《java编程思想》中提及,finalize()方法的一个作用是用来回收“本地方法”中的本地对象
4、
“但是线程并非如此”不理解,希望大佬补充
下面哪段程序能够正确的实现了GBK编码字节流到UTF-8编码字节流的转换:
byte[] src,dst;
正确答案: B 你的答案: B
A、dst=String.fromBytes(src,"GBK").getBytes("UTF-8")
B、dst=new String(src,"GBK").getBytes("UTF-8")
C、dst=new String("GBK",src).getBytes()
D、dst=String.encode(String.decode(src,"GBK")),"UTF-8" )
选B,先通过GBK编码还原字符串,在该字符串正确的基础上得到“UTF-8”所对应的字节串。
socket编程中,以下哪个socket的操作是不属于服务端操作的()
正确答案: C 你的答案: C
A、accept
B、listen
C、connect
D、close
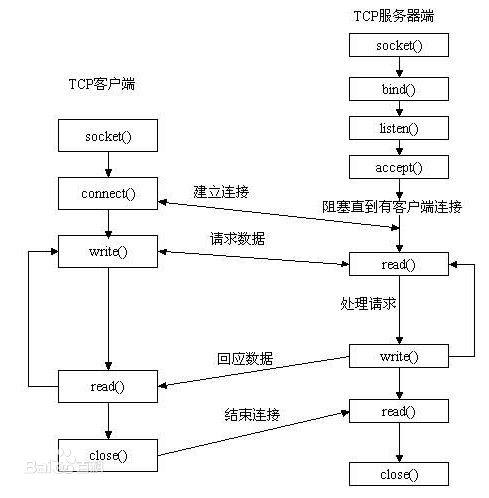
TCP客户端:
- 建立连接套接字,设置Ip和端口监听,socket()
- 建立连接 connect
- write() 获取网络流对象 发送数据
- read()获取网络流对象 接收数据
- 关闭套接字
TCP服务器端
- 建立端口监听 socket()
- 绑定指定端口 bind()
- listen 进行端口监听
- accept() 阻塞式 直到有客户端访问
- read()获取客户端发送数据
- write()发送返回数据
- close关闭端口监听
正确答案: B C 你的答案: B C
A、原子性
B、有序性
C、可见性
D、持久性
synchronized保证三大性,原子性,有序性,可见性,volatile保证有序性,可见性,不能保证原子性
正确答案: A D 你的答案: A D
A、新生代串行收集器
B、老年代串行收集器
C、并行收集器
D、新生代并行回收收集器
E、老年代并行回收收集器
F、cms收集器
两个最基本的java回收算法:
复制算法和标记清理算法
复制算法:两个区域A和B,初始对象在A,继续存活的对象被转移到B。此为新生代最常用的算法
标记清理:一块区域,标记可达对象(可达性分析),然后回收不可达对象,会出现碎片,那么引出
标记整理算法:多了碎片整理,整理出更大的内存放更大的对象
两个概念:新生代和老年代
新生代:初始对象,生命周期短的
老年代:长时间存在的对象
整个java的垃圾回收是新生代和老年代的协作,这种叫做分代回收。
Serial New收集器是针对新生代的收集器,采用的是复制算法
Parallel New(并行)收集器,新生代采用复制算法,老年代采用标记整理
Parallel Scavenge(并行)收集器,针对新生代,采用复制收集算法
Serial Old(串行)收集器,新生代采用复制,老年代采用标记整理
Parallel Old(并行)收集器,针对老年代,标记整理
CMS收集器,基于标记清理
G1收集器:整体上是基于标记 整理 ,局部采用复制综上:新生代基本采用复制算法,老年代采用标记整理算法。cms采用标记清理。
正确答案: C 你的答案: C
A、64M
B、500M
C、300M
D、100M
Xms
起始内存
Xmx
最大内存
Xmn
新生代内存
Xss
栈大小。 就是创建线程后,分配给每一个线程的内存大小
-XX:NewRatio=n
:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n
:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n
:设置持久代大小
收集器设置
-XX:+UseSerialGC
:设置串行收集器
-XX:+UseParallelGC
:设置并行收集器
-XX:+UseParalledlOldGC
:设置并行年老代收集器
-XX:+UseConcMarkSweepGC
:设置并发收集器
垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并行收集器设置
-XX:ParallelGCThreads=n
:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n
:设置并行收集最大暂停时间
-XX:GCTimeRatio=n
:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode
:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n
:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
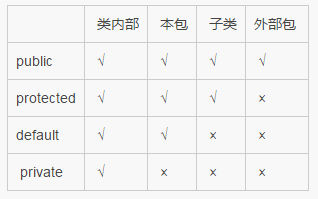
要使某个类能被同一个包中的其他类访问,但不能被这个包以外的类访问,可以( )
正确答案: A 你的答案: A
A、让该类不使用任何关键字
B、使用private关键字
C、使用protected关键字
D、使用void关键字
default和protected的区别是:
前者只要是外部包,就不允许访问。
后者只要是子类就允许访问,即使子类位于外部包。总结:default拒绝一切包外访问;protected接受包外的子类访问
jvm中垃圾回收分为scanvenge gc和full GC,其中full GC触发的条件可能有哪些
正确答案: C D E 你的答案: C D E
A、栈空间满
B、年轻代空间满
C、老年代满
D、持久代满
E、System.gc()
垃圾收集机制:新生代、老年代、持久代
- 新生代:(1)所有对象创建在新生代的Eden区,当Eden区满后触发新生代的Minor GC,将Eden区和非空闲Survivor区存活的对象复制到另外一个空闲的Survivor区中。(2)保证一个Survivor区是空的,新生代Minor GC就是在两个Survivor区之间相互复制存活对象,直到Survivor区满为止。
- 老年代:当Survivor区也满了之后就通过Minor GC将对象复制到老年代。老年代也满了的话,就将触发Full GC,针对整个堆(包括新生代、老年代、持久代)进行垃圾回收。
- 持久代:持久代如果满了,将触发Full GC。
正确答案: A B D 你的答案: A B D
A、HashSet 它是线程安全的,不允许存储相同的对象
B、ConcurrentHashMap 它是线程安全的,其中存储的键对象可以重复,值对象不能重复
C、Collection接口是List接口和Set接口的父接口,通常情况下不被直接使用
D、ArrayList线程安全的,允许存放重复对象
线程安全(Thread-safe)的集合对象:
- Vector
- HashTable
- StringBuffer
非线程安全的集合对象:
- ArrayList
- LinkedList
- HashMap
- HashSet
- TreeMap
- TreeSet
- StringBulider
若有定义语句: int a=10 ; double b=3.14 ; 则表达式 ‘A’+a+b 值的类型是()
正确答案: C 你的答案: C
A、char
B、int
C、double
D、float
char < short < int < float < double 不同类型运算结果类型向右边靠齐。
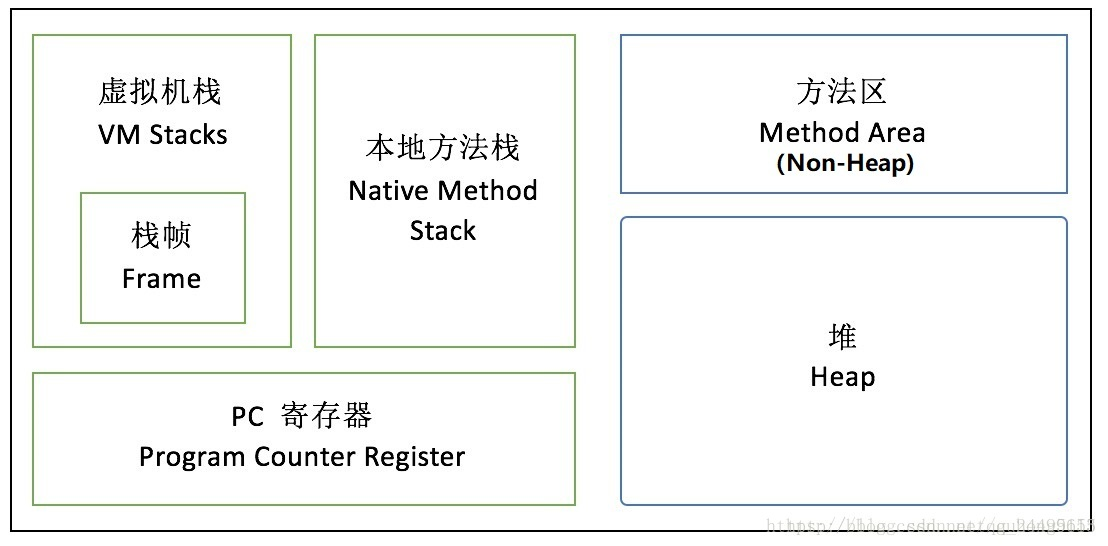
正确答案: D 你的答案: D
A、Stacks
B、PC寄存器
C、Heap
D、Heap Frame
JVM内存五大区域
public class MyClass{
static int i;
public static void main(String argv[]){
System.out.println(i);
}
}
正确答案: D 你的答案: D
A、有错误,变量i没有初始化。
B、null
C、1
D、0
类变量在不设置初始值时,会进行默认值赋值,而局部方法中声明的变量则必须进行初始化,他不会进行默认值赋值。
class X{
Y y=new Y();
public X(){
System.out.print("X");
}
}
class Y{
public Y(){
System.out.print("Y");
}
}
public class Z extends X{
Y y=new Y();
public Z(){
System.out.print("Z");
}
public static void main(String[] args) {
new Z();
}
}
正确答案: C 你的答案: C
A、ZYXX
B、ZYXY
C、YXYZ
D、XYZX
初始化过程:
- 初始化父类中的静态成员变量和静态代码块 ;
- 初始化子类中的静态成员变量和静态代码块 ;
- 初始化父类的普通成员变量和代码块,再执行父类的构造方法;
- 初始化子类的普通成员变量和代码块,再执行子类的构造方法;
执行过程:
(1)初始化父类的普通成员变量和代码块,执行
Y y=new Y();
输出Y
(2)再执行父类的构造方法;输出X
(3)初始化子类的普通成员变量和代码块,执行
Y y=new Y();
输出Y
(4)再执行子类的构造方法;输出Z
(5)所以输出YXYZ
笔记
正确答案: B 你的答案: B
A、多道批处理系统
B、分时系统
C、实时系统
D、分布式系统
操作系统分类
批处理操作系统
(Batch Processing Operating System)它的特点是:多道和成批处理。
分时操作系统
(Time Sharing Operating System,简称TSOS) 分时系统具有多路性、交互性、“独占”性和及时性的特征。多路性指,伺时有多个用户使用一台计算机,宏观上看是多个人同时使用一个CPU,微观上是多个人在不同时刻轮流使用CPU。交互性是指,用户根据系统响应结果进一步提出新请求(用户直接干预每一步)。“独占”性是指,用户感觉不到计算机为其他人服务,就像整个系统为他所独占。及时性指,系统对用户提出的请求及时响应。
实时操作系统
(Real Time Operating System,简称RTOS) 实时操作系统要追求的目标是:对外部请求在严格时间范围内做出反应,有高可靠性和完整性。其主要特点是资源的分配和调度首先要考虑实时性然后才是效率。此外,实时操作系统应有较强的容错能力。
网络操作系统
(Network Operating System,简称NOS)通常运行在服务器上的操作系统,是基于计算机网络的,其目标是相互通信及资源共享。
分布式操作系统
(Distributed Software Systems)是为分布计算系统配置的操作系统。大量的计算机通过网络被连结在一起,可以获得极高的运算能力及广泛的数据共享。
分布式操作系统是网络操作系统的更高形式,它保持了网络操作系统的全部功能,而且还具有透明性、可靠性和高性能等。网络操作系统和分布式操作系统虽然都用于管理分布在不同地理位置的计算机,但最大的差别是:网络操作系统知道确切的网址,而分布式系统则不知道计算机的确切地址;分布式操作系统负责整个的资源分配,能很好地隐藏系统内部的实现细节,如对象的物理位置等。这些都是对用户透明的。
正确答案: A 你的答案: A
A、并行,串行
B、串行,并行
C、并行,并行
D、串行,串行
并行数据传输: 是在传输中有多个数据位同时在设备之间进行的传输.一个编了码的字符通常是由若干位二进制数表示,如用ASCII码编码的符号是由8位二进制数表示的,则并行传输ASCII编码符号就需要8个传输信道,使表示一个符号的所有数据位能同时沿着各自的信道并排的传输.。
串行数据传输:是在传输中只有1个数据位在设备之间进行的传输.对任何一个由若干位二进制表示的字符,串行传输都是用一个传输信道,按位有序的对字符进行传输。
区别: 串行传输的速度比并行传输的速度要慢得多,但费用低.并行传输适用距离短,而串行传输适用远距离传输
正确答案: A B C D 你的答案: A B C D
A、session
B、Cookie
C、地址重写
D、隐藏域
会话跟踪是一种灵活、轻便的机制,它使Web上的状态编程变为可能。
HTTP是一种无状态协议,每当用户发出请求时,服务器就会做出响应,客户端与服务器之间的联系是离散的、非连续的。当用户在同一网站的多个页面之间转换时,根本无法确定是否是同一个客户,会话跟踪技术就可以解决这个问题。当一个客户在多个页面间切换时,服务器会保存该用户的信息。
有四种方法可以实现会话跟踪技术:URL重写、隐藏表单域、Cookie、Session。
- 隐藏表单域:,非常适合步需要大量数据存储的会话应用。
- URL重写:URL可以在后面附加参数,和服务器的请求一起发送,这些参数为名字/值对。
- Cookie:一个Cookie是一个小的,已命名数据元素。服务器使用 SET-Cookie 头标将它作为HTTP响应的一部分传送到客户端,客户端被请求保存Cookie值,在对同一服务器的后续请求使用一个Cookie头标将之返回到服务器。与其它技术比较,Cookie的一个优点是在浏览器会话结束后,甚至在客户端计算机重启后它仍可以保留其值
- Session:使用 setAttribute(String str,Object obj)方法将对象捆绑到一个会话
正确答案: C 你的答案: C
A、分区
B、关系型
C、树型
D、网状
windows操作系统的目录结构是树形结构。就像一棵树,它的树干就是根目录,然后第一个分枝之后是第一层目录
正确答案: B 你的答案: B
A、文件夹
B、文件
C、inode
D、软链接
Linux系统下,一切都是文件,硬件设备也是文件
下列进程通信机制中, UNIX 系统中没有采用的机制是( )
正确答案: B 你的答案: B
A、信号量集
B、管程机制
C、软中断信号
D、套接字
Linux进程间通信:管道、信号、消息队列、共享内存、信号量、套接字(socket)
Linux线程间通信:互斥量(mutex),信号量,条件变量
Windows进程间通信:管道、消息队列、共享内存、信号量(semaphore)、套接字(socket)
Windows线程间通信:互斥量(mutex),信号量(semaphore)、临界区(critical section)、事件(event)
IPv4地址32位
MAC地址48位
IPv6地址128位
网络状态码
| 状态码 | 英文 | 解释 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy |
使用。所请求的资源必须通过 访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required |
请求要求的身份认证,与401类似,但请求者应当使用 进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者***工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或***的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
设计模式分类
一、创建型模式
工厂模式(Factory Pattern)
抽象工厂模式(Abstract Factory Pattern)
单例模式(Singleton Pattern)
建造者模式(Builder Pattern)
原型模式(Prototype Pattern)
二、结构型模式
适配器模式(Adapter Pattern)
桥接模式(Bridge Pattern)
过滤器模式(Filter、Criteria Pattern)
组合模式(Composite Pattern)
装饰器模式(Decorator Pattern)
外观模式(Facade Pattern)
享元模式(Flyweight Pattern)
代理模式(Proxy Pattern)
三、行为型模式
责任链模式(Chain of Responsibility Pattern)
命令模式(Command Pattern)
解释器模式(Interpreter Pattern)
迭代器模式(Iterator Pattern)
中介者模式(Mediator Pattern)
备忘录模式(Memento Pattern)
观察者模式(Observer Pattern)
状态模式(State Pattern)
空对象模式(Null Object Pattern)
策略模式(Strategy Pattern)
模板模式(Template Pattern)
访问者模式(Visitor Pattern)
常用 ASCII 码值
空格为 32
数字0为 48
“A”为 65
“a”值为 97
JVM常用命令
- jps:查看本机java进程信息。
- jstack:打印线程的栈信息,制作线程dump文件。
- jmap:打印内存映射,制作堆dump文件
- jstat:性能监控工具
- jhat:内存分析工具
- jconsole:简易的可视化控制台
- jvisualvm:功能强大的控制台
数据库系统的三级模式结构
数据库系统的三级模式结构是指数据库系统是由
外模式
、
模式
和
内模式
三级构成.
为了能够在系统内部实现这 3 个抽象层次的联系和转换,数据库管理系统在这三级模式之间提供了两层映像:
外模式/模式映像
(映像定义通常包含在各自外模式的描述中,保证了数据与程序的逻辑独立性,简称
数据的逻辑独立性
,应用程序是依据外模式编写的)
模式/内模式映像
(包含在模式描述中,此映像是唯一的,它定义了数据全局逻辑结构与存储结构之间的对应关系,它保证了数据与程序的物理独立性,所以称为
数据的物理独立性
)
1NF,2NF,3NF
1NF : 属性是原子性的,即不可拆分的;例如姓名这个属性是一般不可拆分的;而社会保险号如果是由出生年月日与姓名缩写构成的话,就是可拆分的:包含可拆分的含义:出生年月日,姓名; 是否可拆分取决于对含义的解释;
2NF:解决了非主键属性对主键属性的部分依赖;如表(A, B, C, D),其中ABCD代表属性,假设(A, B)是主键,若C只依赖于B,则这个表是不符合2NF的,可拆分为(A, B, D)与 (B, C)两张表;很明显,如果主键只有一个属性,那么肯定是2NF
3NF:解决了非主键属性对主键属性的传递依赖;如表(A,B,C,D),如果主键是A, 而B依赖于A,C依赖于B,则这个表有传递依赖,是不符合3NF的;
范式的目的是为了
减少/消除冗余
共享锁/排他锁
共享锁【S锁】,又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁【X锁】,又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
事务的特性
原子性(Atomicity):是事务执行的最小单位。不允许分割。事务的原子性确保动作要么全部成功,要么全部失败
一致性(Consistency):执行事务的前后,数据保持不变
隔离性(Isolation):并发访问事务时,一个用户的事务数据不能被其他事务所干扰。各并发事务之间的数据库是独立的
持久性(Durability):一个事物被提交后,他对数据库的数据改变时持久的。即使数据库发生故障,也不应该对数据有影响