文章目录
-
WFST,HCLG
-
lattice
-
-
两种lattice结构The Lattice type 和Compact lattices
-
Lattice的产生
-
获取raw lattice,并将其转换为最终形式。
-
Lattices in archives
-
再lattices上的一些操作
-
-
Pruning lattices 剪枝
-
Computing the best path through a lattice 计算最优路径
-
Computing the N-best hypotheses
-
Probability scaling
-
Determinization of lattices
-
Lattice union
-
Lattice projection
-
Lattice composition
-
Lattice interpolation
-
Language model rescoring
-
Conversion of lattices to phones
-
Lattice equivalence testing
-
Removing alignments from lattices
-
Error boosting in lattices
-
LatticeBoost()
-
Computing posteriors from lattices
-
Copying lattices
-
-
WFST,HCLG
首先看博客:
传送门
同时可以参考如何去查看里面的各个文件:
传送门
了解HCLG.fst由哪四部分构成的,他们的构成的先后顺序是怎么样的,以及构成每一步的时候他们的输入输出文件是什么。
HCLG.fst由四部分构成
-
G:语言模型WFST,输入输出符号相同,实际是一个WFSA(acceptor接受机),为了方便与其它三个WFST进行操作,将其视为一个输入输出相同的WFST。
-
L:发音词典WFST,输入符号:monophone,输出符号:词;
-
C:上下文相关WFST,输入符号:triphone(上下文相关),输出符号:monophnoe;
-
H:HMM声学模型WFST,输入符号:HMMtransitions-ids,输出符号:triphone。
将四者逐层合并,即可得到最后的图。
HCLG= asl(min(rds(det(H’omin(det(Co min(det(Lo G)))))))
然后生成一下*.fst文件的图片,看一下网络结构。

lattice
首先在了解lattice之前,要先去看一下什么是半环,半环和群的定义:
传送门
然后看一下这个中文博客,初步了解一下:
传送门
最后看kaldi官网的描述和代码:
传送门
两种lattice结构The Lattice type 和Compact lattices
Lattice结构:
FST的形式,weight包括两部分(graph cost和acoustic cost),输入是transition-ids,输出是words。
其中weight的graph cost包含LM+transition+pronunciation三部分。
CompactLattice结构
和lattice相似,区别在于它是接收机,输入和输出一样(都是words),weight包含两部分(权重和transition-ids),相比于Lattice,CompactLattice把输入的
transition-ids转移到weight上面。
lattice保证每一个word-sequence只对应lattice中的一条路径。
代码部分:
Lattice:
lattice只是一个模板在特定半环上的fst。在kaldi lattice.h中,我们创建一个typedef:
typedef fst::VectorFst<LatticeArc> Lattice;
其中,LatticeArc是在LatticeWeight上模板化的标准圆弧类型:
typedef fst::ArcTpl<LatticeWeight> LatticeArc;
latticeWeight还是一个typedef,它使用basefloat作为浮点类型来实例化latticeWeightTPL模板。
typedef fst::LatticeWeightTpl<BaseFloat> LatticeWeight;
下面是一个相似的权重
LexicographicWeight<TropicalWeight, TropicalWeight>
LatticeWeightTpl的构造函数,里面包含的属性:
LatticeWeightTpl &operator=(const LatticeWeightTpl &w) {
value1_ = w.value1_;
value2_ = w.value2_;
return *this;
}
两个weight的区别在于:
假设a表示graph cost,b表示acoustic cost,那么
LatticeWeight表示为(a,b)
LexicographicWeight表示为(a+b,a-b)
LatticeWeight背后的基本目标是保持采用最低成本路径(其中总成本是图形加声学成本)的语义,同时分别“记住”声学和图形成本是什么。
lattice相关的算法在Lattice上面更为高效,因为CompactLattice的weight包含有transition-ids,当take best path的时候就涉及到transition-ids的拼接操作。
可以使用ConvertLattice()函数将Lattice转化为CompactLattice。lattice转化:
Lattice lat;
// initialize lat.
CompactLattice compact_lat;
ConvertLattice(lat, &compact_lat);
lattice寻找最短路径
Lattice lat;
// initialize lat.
Lattice best_path;
fst::ShortestPath(lat, &best_path);
Compact lattices (the CompactLattice type):
CompactLattice以及他的弧和权重的定义
typedef fst::VectorFst<CompactLatticeArc> CompactLattice;
typedef fst::ArcTpl<CompactLatticeWeight> CompactLatticeArc;
typedef fst::CompactLatticeWeightTpl<LatticeWeight, int32> CompactLatticeWeight;
CompactLatticeWeightPL的模板参数是一个基础权重(此处为LatticeWeight)和一个整数类型(此处为Int32)。
它包含两个数据成员:权重和整数序列:
template<class WeightType, class IntType>
class CompactLatticeWeightTpl {
...
private:
WeightType weight_;#声学加上语言模型的代价
vector<IntType> string_;#transion_id 的序列
};
乘法对应于将权重相乘并将字符串附加在一起。当加入两个CompactLatticeWeights时,我们首先比较权重分量,如果其中一个权重比另一个权重“多”,我们就取这个权重及其对应的字符串。如果不是(即,如果两个权重相同),我们使用字符串上的顺序来判断关系。如果他们的长度不一样的话,我们使用的排序顺序就是选择长度较短的那个字符串,否则使用字典序来判断(我们不能只使用词序,还需要其他的方式来一起判断,或它会违反一个半环公理,这是乘法的分配比加法)。
注意,我们在上面讨论过一个权重比另一个权重“多”,我们假设如果两者都不比另一个权重多,那么它们是相等的。只有当半环上有一个总的阶时,这才是真的,这是对模板的权分量的一个要求(这个要求对于格权和热带权是满足的)访问此顺序的“OpenFst”方法是使用模板“NaturalLess”,该模板给定a和b,查找(a+b)是等于a还是等于b。出于效率原因,我们不这样做:我们假设在权重类型上定义了一个Compare()函数,该函数根据比较返回-1、0或1我们为LatticeWeightTpl模板定义了这样一个函数为了使CompactLatticeWeightTPL能够被实例化为TropicalWeight,这是为了测试的目的,我们为该权重类型定义了一个适当的比较函数。
比较两个lattice的话有专门定义的函数Compare() :
Lattice
int fst::Compare( const LatticeWeightTpl< FloatType > & w1,
const LatticeWeightTpl< FloatType > & w2 )
Compare returns :这里的w是指概率的意思,cost越小,w的概率越大
if w1 < w2 , return -1
if w1 > w2 , return +1
if w1 == w2 , return 0
先比较graph cost+acoustic cost
如果graph cost+acoustic cost相等,则比较 graph cost
template<class FloatType>
inline int Compare (const LatticeWeightTpl<FloatType> &w1,
const LatticeWeightTpl<FloatType> &w2) {
//这边直接把图cost和声学cost的两个代价value1和value2直接相加
FloatType f1 = w1.Value1() + w1.Value2(),
f2 = w2.Value1() + w2.Value2();
if (f1 < f2) { return 1; } // having smaller cost means you're larger
// in the semiring [higher probability]
else if (f1 > f2) { return -1; }
// mathematically we should be comparing (w1.value1_-w1.value2_ < w2.value1_-w2.value2_)
// in the next line, but add w1.value1_+w1.value2_ = w2.value1_+w2.value2_ to both sides and
// divide by two, and we get the simpler equivalent form w1.value1_ < w2.value1_.
else if (w1.Value1() < w2.Value1()) { return 1; }
else if (w1.Value1() > w2.Value1()) { return -1; }
else { return 0; }
}
CompactLattice
int fst::Compare ( const CompactLatticeWeightTpl< WeightType, IntType > & w1,
const CompactLatticeWeightTpl< WeightType, IntType > & w2
)
这里的比较首先比较权重;如果相同,则比较字符串。字符串的比较是:首先比较长度,如果这是相同的,使用字典顺序。我们不能仅仅使用词典编纂顺序,因为这会破坏乘法对加法的分配性质,同时考虑加法使用比较法。“compare”的字符串元素在实际中并不是非常重要;它只需要确保plus总是给出一致的答案并且是对称的。
template<class WeightType, class IntType>
inline int Compare(const CompactLatticeWeightTpl<WeightType, IntType> &w1,
const CompactLatticeWeightTpl<WeightType, IntType> &w2) {
//首先比较权重
int c1 = Compare(w1.Weight(), w2.Weight());
//如果权重不同,则直接输出权重的比较结果
if (c1 != 0) return c1;
int l1 = w1.String().size(), l2 = w2.String().size();
// Use opposite order on the string lengths, so that if the costs are the same,
// the shorter string wins.
//比较字符串的长度
if (l1 > l2) return -1;
else if (l1 < l2) return 1;
//如果字符串的长度相同的话,比较字典序的大小,也就是从第一位开始比较他们的ASCII码
for(int i = 0; i < l1; i++) {
if (w1.String()[i] < w2.String()[i]) return -1;
else if (w1.String()[i] > w2.String()[i]) return 1;
}
return 0;
}
Lattice的产生
1.目前,生成 lattice 的唯一解码器是定义在 decoder/lattice-simple-decoder.h 中的类 LatticeSimpleDecoder,它被 gmm-latgen-simple.cc中调用。
LatticeSimpleDecoder的kaldi文档
2.LatticeSimpleDecoder 是由 SimpleDecoder 修改得到的
SimpleDecoder是一种直接实现的Viterbi 集束搜索(Beam Search Algorithm )算法,只有一个可调参数:the pruning beam(修建光束)。
LatticeSimpleDecoder有一个更重要的可调参数:lattice beam (或 lattice-delta),它通常应该小于 pruning beam。
详细了解集束算法参考博客:
传送门
3.基本情况是,latticesimpledder首先生成一个状态级格,并用 lattice-delta对其进行修剪,然后在最后运行一个特殊的确定算法,该算法只为每个字序列保留最佳路径。
对应的类 LatticeSimpleDecoder,流程包括:
- 产生state级别的lattice
- 使用lattice-delta对lattice剪枝
- 使用特殊的确定化算法对每一个word sequence只保留最优路径
4.在 SimpleDecoder 中,有引用计数的回溯(reference-counted tracebacks)
在 LatticeSimpleDecoder 中,单个回溯是不够的,因为网格具有更复杂的结构。
实际上,存储前向链接比后向链接更方便。
为了释放 lattice-delta pruning(剪枝) 时不需要的链接,我们需要做的比引用计数更多,实际上也没有做引用计数。
修剪算法的最终目标如下。首先,假设对于每个帧,对于在该帧上处于活动状态的每个状态,我们创建了某种结构或标记,对于其中的每个弧(对于未修剪的状态),我们创建了某种链接记录。让我们使用单词“token”来表示我们为特定帧上的特定图形状态创建的结构,使用“link”来表示从一个token到另一个token的前向链接(注意:由于解码图中的epsilon弧,这些链接可以在帧内也可以跨帧)。剪枝算法最简单的版本是:首先,我们解码到文件的末尾,保持解码过程中活动的所有token和link。当我们到达文件末尾时,我们希望
应用lattice-delta光束,这样,任何不在最佳路径的lattice-delta成本范围内的路径上的状态或弧都将被剪除
。不幸的是,这不是一个非常实用的算法,因为我们很快就会耗尽内存:在每一帧上,通常有成千上万个状态处于活动状态,我们不能等到话语结束时才删除它们。
但是有一种有效的方法可以在话语结束前剪掉这些标记。周期性地(默认情况下每25帧),我们从当前帧向后扫描到开始帧。在这个向后扫描中,我们为每个token计算一个“delta”数量。“delta”是最佳路径的开销和token所在的最佳路径的开销之间的差异,它可以在后向扫描中计算(我们需要的“前向”信息已经在token中,并且是静态的)我们可以为前向链路定义一个类似的“delta”量。每当这个“delta”超过“lattice delta”波束时,我们就删除相关的token或link。对于当前活动帧上的token,我们将“delta”设置为零;我们可以证明这是正确的做法也就是说,有了这个算法,我们只会剪掉那些我们最终会用之前那个算法剪掉的东西。
从表面上看,我们的剪枝算法可能需要话语长度的时间平方(因为我们访问整个话语直到当前点的每25帧),但实际上它更像是线性的,因为我们可以检测特定帧的所有标记的“delta”值何时没有改变我们可以及时停止倒退我们希望在很长的一段时间里,我们通常只会向后修剪一两秒钟。即使不是因为这个特性,算法在实际情况下也会被一个线性时间分量所支配,因为绝大多数的令牌在算法第一次访问时被删除。
我们注意到,在实现这一点上有一些复杂性。一个是因为我们有前向链接,而剪枝算法在时间上是向后的,当我们删除()标记时,存在创建“悬挂”前向链接的危险,因此我们必须避免删除()标记,直到我们从上一帧剪除前向链接。另一个问题是,我们必须特别对待最终的框架,因为我们需要考虑最终的概率。
获取raw lattice,并将其转换为最终形式。
当我们到达话语的结尾时,我们产生了两个阶段的lattice。
第一个阶段是创建raw lattice这是一个state-level FST,它使用lattice delta进行修剪,但存在不确定性,因此它有许多对应于每个字序列的可选路径。
raw lattice的创建非常简单,它包括获取令牌和链接结构并将它们转换为openfst结构。如果我们被要求寻找最佳路径(例如获取文本),我们只需在这个raw lattice上运行openfst的shortestpath算法。
如果我们需要lattice,有两种选择:
第一个选项是:解码器支持直接输出raw state-level lattice (set–determinize lattice=false)。如果要使用同一棵树构建的系统进行声学重采样,这一点非常有用。之后,在将lattiice存储在磁盘上很长一段时间(因为raw state-level lattice 相当大)之前,您可能希望使用lattice-determinize 程序确定lattice。
第二个选项,我们假设输出的是determinized lattice 。对于raw lattice中允许的每个字序列,determinized lattice 假设只有一条路径能够通过它。
我们可以通过创建一个CompactLattice,去掉epsilon并确定来实现这一点,但这将是非常低效的。相反,我们运行一个称为determinizelatice()的特殊确定算法。该算法将epsilon去除和确定结合起来。
在这方面,它类似于我们的算法determinizestar(),但是determinizelatice()算法使用的数据结构是针对这种情况专门优化的。
问题是将长串的输入符号加在一起的成本开销(符号序列长度只与一个单词的最大帧数有关,但这相当长)。也就是说,如果以最简单的方式表示为向量,那么将一个符号添加到n个符号的列表中并分别存储结果将花费时间o(n)。相反,我们使用的数据结构就能使其花费恒定的时间。
DeterminizeLattice()接受lattice格式作为输入,因为这是输入的最自然形式,并且以CompactLattice格式输出。然而,它实际上应该被看作是compactlattice格式的确定:也就是说,它只有在将其视为compactlattice上的操作时才保持等价性。
DeterminizeLattice() :
bool DeterminizeLattice (const Fst< ArcTpl< Weight > > & ifst,
MutableFst< ArcTpl< Weight > > * ofst,
DeterminizeLatticeOptions opts = DeterminizeLatticeOptions(),
bool * debug_ptr = NULL
)
此函数实现determinizelatice的普通版本,其中输出字符串使用弧序列表示,除第一个字符串外,其他字符串的输入端都有一个epsilon。
debug_ptr参数是指向bool的可选指针,如果在算法执行时变为true,算法将打印回溯并终止(用于fstdeterminizestar.cc debug non-termining determination)。如果ifst是在输入标签上进行弧形排序,则效率更高。如果弧的数目超过max_states,它将抛出std::runtime_错误(否则此代码不使用异常)。这主要用于调试。
{
ofst->SetInputSymbols(ifst.InputSymbols());
ofst->SetOutputSymbols(ifst.OutputSymbols());
LatticeDeterminizer<Weight, IntType> det(ifst, opts);
if (!det.Determinize(debug_ptr))
return false;
det.Output(ofst);
return true;
}
Lattices in archives
生成lattice的命令如下:
gmm-latgen-simple --beam=13.0 --acoustic-scale=0.0625 exp/tri/1.mdl \
exp/graph_tri/HCLG.fst ark:test_feats.ark "ark,t:|gzip -c > exp/lats_tri/1.lats.gz"
在这之后,我们可以看lattice如下:
gunzip -c exp/decode_tri2a_bg_latgen_eval92/7.lats.gz | \
utils/int2sym.pl -f 3 data/words.txt | head
444c0410
0 1 <s> 5.27832,0,
1 2 <UNK> 8.08116,1099.84,
1 3 A 12.8737,8342.93,3_1_1_1_1_1_1_1_1_1_1_12_18_17_17_17_17_17_17_17_17_17_3\
464_3596_3632_3_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_\
1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_12_18_17_17_18562_18561_18604_18\
603_18603_18618_604_603_603_638
1 4 IF 10.2262,8096.64,3_1_1_1_1_1_1_1_1_1_1_12_18_17_17_17_17_17_17_13708_137\
28_13806_12654_12670_12676_3_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1\
_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_12_18_17_17_17_1856\
2 5 NOT 12.4568,10548.7,3_1_1_1_1_1_1_1_1_1_1_12_18_17_17_17_17_17_17_17_20_26\
...
存在一个让人困惑的地方,标签出现再transition中,有 graph and acoustic scores,但是没有输入的标签。必须认识到,只有在通过FST的整个路径上求和(或附加)时,图形和声学分数以及输入标签序列才有效。不能保证它们相互之间或与单词标签同步。
lattice通常以CompactLattice格式存储在存档中,如前所述,我们使用存档中的声学权重不缩放的约定,因此对于对声学权重敏感的操作(如修剪),相应的命令行程序将采用–acoustic scale选项,并在执行此类操作之前缩放声学权重(然后取消缩放)
再lattices上的一些操作
Pruning lattices 剪枝
我们可以使用特定的pruning beam做一写剪枝,移除不在lattice最佳路径,或者也不在cost很接近最佳路径cost的那种次优路径上的弧和状态。对于每一个lattice,我们的程序lattice-prune首先使用特定的acoustic scale对我们的acoustic weight声学代价进行缩放,然后我们调用OpenFst’s Prune()的函数,最后反转声学权重的缩放。
lattice-prune --acoustic-scale=0.1 --beam=5 ark:in.lats ark:out.lats
以下比较一下lattice-prune前后某句话对应的lattice的结构(第一张为剪枝前,第二张为剪枝后):
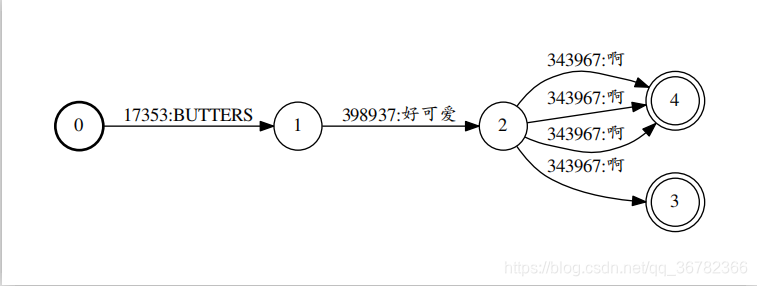
注意:为了提高效率,修剪操作是在lattice格式中完成的,但是我们在输出lattice之前先要将lattice转换为compactlattice。
PruneLattice() 函数的解析:
bool kaldi::PruneLattice ( BaseFloat beam,
LatType * lat
)
删除了一些变量的定义,拿出关键的函数来分析一下:
{
typedef typename LatType::Arc Arc;
typedef typename Arc::Weight Weight;
typedef typename Arc::StateId StateId;
KALDI_ASSERT(beam > 0.0);
if (!lat->Properties(fst::kTopSorted, true)) {
if (fst::TopSort(lat) == false) {
KALDI_WARN << "Cycles detected in lattice";
return false;
}
}
// We assume states before "start" are not reachable, since
// the lattice is topologically sorted.
int32 start = lat->Start();
int32 num_states = lat->NumStates();
if (num_states == 0) return false;
//std::numeric_limits<double>::infinity()的值是整数的正无穷大
std::vector<double> forward_cost(num_states,
std::numeric_limits<double>::infinity()); // viterbi forward.
forward_cost[start] = 0.0; // lattice can't have cycles so couldn't be
// less than this.
double best_final_cost = std::numeric_limits<double>::infinity();
// Update the forward probs.
// Thanks to Jing Zheng for finding a bug here.
//相当于在跑一个最短路的算法,forward_cost[x]指的是从开始的状态到状态x最小路径代价
for (int32 state = 0; state < num_states; state++) {
double this_forward_cost = forward_cost[state];
for (fst::ArcIterator<LatType> aiter(*lat, state);
!aiter.Done();
aiter.Next()) {
const Arc &arc(aiter.Value());
StateId nextstate = arc.nextstate;
KALDI_ASSERT(nextstate > state && nextstate < num_states);
double next_forward_cost = this_forward_cost +
ConvertToCost(arc.weight);
if (forward_cost[nextstate] > next_forward_cost)
forward_cost[nextstate] = next_forward_cost;
}
//这个好像是如果state是结束状态的话,他有一个终止状态的权重。
Weight final_weight = lat->Final(state);
//ConvertToCost(final_weight);就是将graph cost和acoustic cost相加
double this_final_cost = this_forward_cost +
ConvertToCost(final_weight);
//选择最小的结束代价
if (this_final_cost < best_final_cost)
best_final_cost = this_final_cost;
}
//增加一个状态
int32 bad_state = lat->AddState(); // this state is not final.
//beam我认为是个阈值,我们可以允许与最优路径的代价相差不到beam代价的路径存在,超过的路径上的状态和弧都要被剪掉
double cutoff = best_final_cost + beam;
// Go backwards updating the backward probs (which share memory with the
// forward probs), and pruning arcs and deleting final-probs. We prune arcs
// by making them point to the non-final state "bad_state". We'll then use
// Trim() to remove unnecessary arcs and states. [this is just easier than
// doing it ourselves.]
std::vector<double> &backward_cost(forward_cost);
for (int32 state = num_states - 1; state >= 0; state--) {
double this_forward_cost = forward_cost[state];
//state是结束状态的话,他有一个终止状态的权重。
double this_backward_cost = ConvertToCost(lat->Final(state));
//如果前向的代价加上后向的代价大于我们设定的阈值并且结束代价不是无穷大的话,剪枝这个状态节点。
if (this_backward_cost + this_forward_cost > cutoff
&& this_backward_cost != std::numeric_limits<double>::infinity())
lat->SetFinal(state, Weight::Zero());
//lattice是有向无环图,因为接出来的路径是对应的帧,那肯定是有先后顺序,所以是有向的。
for (fst::MutableArcIterator<LatType> aiter(lat, state);
!aiter.Done();aiter.Next()) {
Arc arc(aiter.Value());
StateId nextstate = arc.nextstate;
KALDI_ASSERT(nextstate > state && nextstate < num_states);
double arc_cost = ConvertToCost(arc.weight),
arc_backward_cost = arc_cost + backward_cost[nextstate],
this_fb_cost = this_forward_cost + arc_backward_cost;
//从这个节点往后的各个路径中,找最小后向代价的路径
if (arc_backward_cost < this_backward_cost)
this_backward_cost = arc_backward_cost;
//剪枝弧的方法就是将这条弧指向的state改变为我们之前设置的那个bad_state
if (this_fb_cost > cutoff) { // Prune the arc.
arc.nextstate = bad_state;
aiter.SetValue(arc);
}
}
backward_cost[state] = this_backward_cost;
}
//Removes arcs to the non-coaccessible state.
//删除到不可接受状态的弧
fst::Connect(lat);
return (lat->NumStates() > 0);
}
Computing the best path through a lattice 计算最优路径
程序lattice-best-path计算通过lattice的最佳路径,并输出相应的输入符号序列(对齐)和输出符号序列(转录)。像往常一样,输入和输出是以档案的形式进行的命令行示例如下:
lattice-best-path --acoustic-scale=0.1 ark:in.lats ark:out.tra ark:out.ali
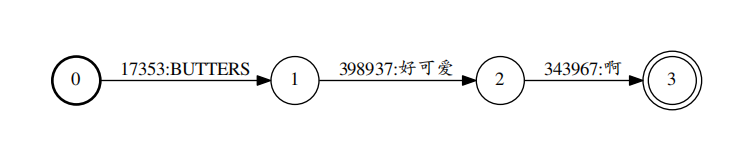
以下是对一个lattice通过lattice-best-path计算出最好的那个路径(第一张为lattice,第二张为计算出的最优路径):

lattice-best-path.cc 的代码解析:对于每一句话的lattice,首先运行CompactLatticeShortestPath()跑个最短路,计算出最优路径的lattice,然后输出一下他的抄本和对齐。接下来就主要分析一下CompactLatticeShortestPath()这个函数的代码及其实现。
CompactLatticeShortestPath()
void CompactLatticeShortestPath ( const CompactLattice & clat,
CompactLattice * shortest_path
)
最短路径/最佳路径算法的一种形式,专门为 CompactLattice。
clat 指的是要计算的lattice,shortest_path指的是计算得到的最短路径。
这个函数主要分为三个部分去理解:
第一部分,计算最短路:
一开始先初始化数组best_cost_and_pred。这个数组的含义:best_cost_and_pred[current]的值是一个pair,有两个值,第一值是指从开始state到current state的最短路径的长度(最小代价),第二个值指向的是上一个state,用来之后的回溯。
然后之后的循环主体的话,就是一个普通的迪杰斯特拉最短路,不懂的可以看看我之前最短路的acm题,有很多并且有详细的解释。(竟然没有用堆优化或者优先队列优化的最短路,hhhhhhh)
vector<std::pair<double, StateId> > best_cost_and_pred(clat.NumStates() + 1);
StateId superfinal = clat.NumStates();
for (StateId s = 0; s <= clat.NumStates(); s++) {
best_cost_and_pred[s].first = std::numeric_limits<double>::infinity();
best_cost_and_pred[s].second = fst::kNoStateId;
}
best_cost_and_pred[0].first = 0;
for (StateId s = 0; s < clat.NumStates(); s++) {
double my_cost = best_cost_and_pred[s].first;
for (ArcIterator<CompactLattice> aiter(clat, s);
!aiter.Done();
aiter.Next()) {
const Arc &arc = aiter.Value();
double arc_cost = ConvertToCost(arc.weight),
next_cost = my_cost + arc_cost;
if (next_cost < best_cost_and_pred[arc.nextstate].first) {
best_cost_and_pred[arc.nextstate].first = next_cost;
best_cost_and_pred[arc.nextstate].second = s;
}
}
double final_cost = ConvertToCost(clat.Final(s)),
tot_final = my_cost + final_cost;
if (tot_final < best_cost_and_pred[superfinal].first) {
best_cost_and_pred[superfinal].first = tot_final;
best_cost_and_pred[superfinal].second = s;
}
}
第二部分:从最后一个结点,按照best_cost_and_pred数组,每个结点都指向上一个最短路径的结点,不断回溯直到回到第一个state。
std::vector<StateId> states; // states on best path.
StateId cur_state = superfinal;
while (cur_state != 0) {
StateId prev_state = best_cost_and_pred[cur_state].second;
if (prev_state == kNoStateId) {
KALDI_WARN << "Failure in best-path algorithm for lattice (infinite costs?)";
return; // return empty best-path.
}
states.push_back(prev_state);
KALDI_ASSERT(cur_state != prev_state && "Lattice with cycles");
cur_state = prev_state;
}
第三部分:构建最短路径的lattice,因为第二部分已经得到了最短路径的各个state,接下来就是把他们连接起来,然后把弧上的权重重新赋值就可以了。
std::reverse(states.begin(), states.end());
for (size_t i = 0; i < states.size(); i++)
shortest_path->AddState();
for (StateId s = 0; static_cast<size_t>(s) < states.size(); s++) {
if (s == 0) shortest_path->SetStart(s);
if (static_cast<size_t>(s + 1) < states.size()) { // transition to next state.
bool have_arc = false;
Arc cur_arc;
for (ArcIterator<CompactLattice> aiter(clat, states[s]);
!aiter.Done();
aiter.Next()) {
const Arc &arc = aiter.Value();
if (arc.nextstate == states[s+1]) {
if (!have_arc ||
ConvertToCost(arc.weight) < ConvertToCost(cur_arc.weight)) {
cur_arc = arc;
have_arc = true;
}
}
}
KALDI_ASSERT(have_arc && "Code error.");
shortest_path->AddArc(s, Arc(cur_arc.ilabel, cur_arc.olabel,
cur_arc.weight, s+1));
} else { // final-prob.
shortest_path->SetFinal(s, clat.Final(states[s]));
}
}
Computing the N-best hypotheses
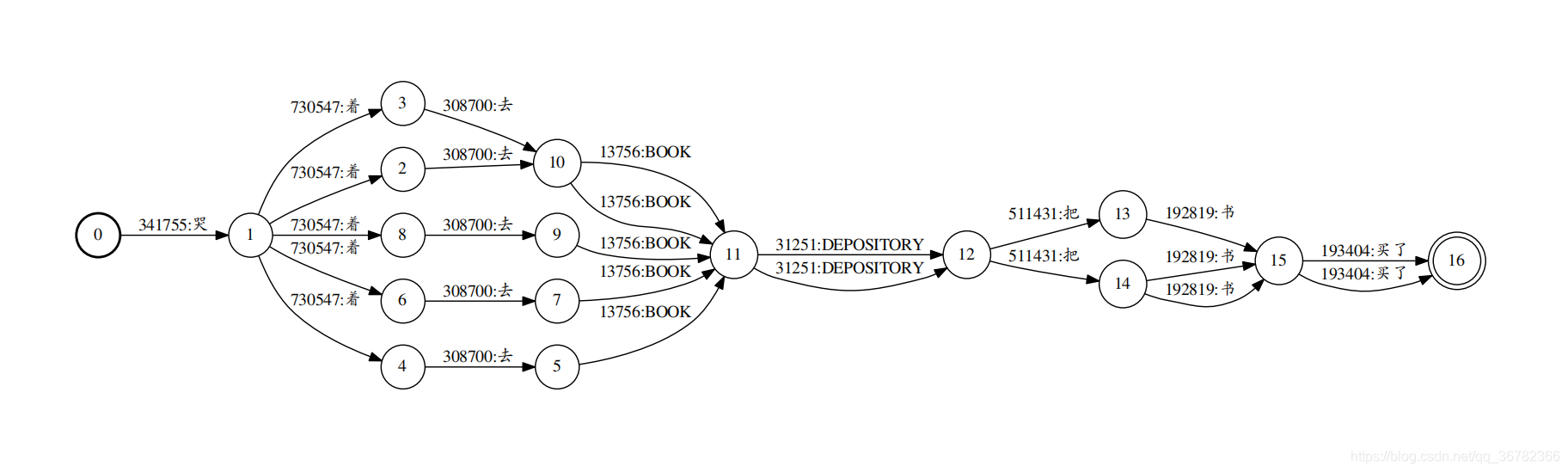
程序lattice-nbest计算通过lattice的N条最佳路径(使用OpenFst的ShortestPath()函数),并将结果输出为lattice(CompactLattice),但具有特殊的结构。如OpenFst中ShortestPath()函数的文档所述,开始状态将有(最多)n个弧,每个弧都指向一个单独路径的开始。注意,这些路径可以共享后缀。命令行示例如下:
lattice-nbest --n=10 --acoustic-scale=0.1 ark:in.lats ark:out.nbest
可以查看他的scp,发现他将一句话的lattice拆成了n份,每一份的lattice只有一条路径。
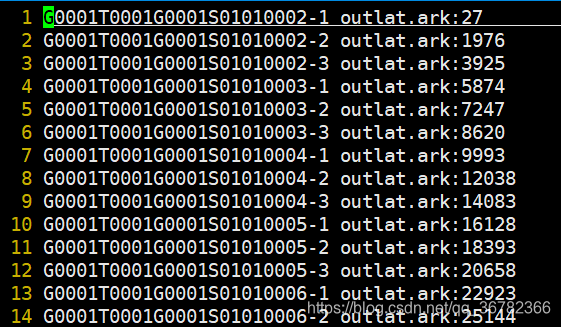
我这边是设了n=3,可以看到下面的scp的每一句话被化分成了好几份。
Probability scaling
可以使用一般的2×2矩阵来缩放lattice weight的概率。执行此操作的命令行程序是lattice-scale。命令行示例如下:
lattice-scale --acoustic-scale=0.1 --lm-scale=0.8 ark:in.lats ark:out.lats
这实际上不是一个经常使用的程序,因为我们希望通常档案中的acoustic weights应该是不标度的;
需要应用acoustic scale的程序通常接受-acoustic-scale选项。
此类程序通常应用比例,执行对其敏感的操作(如determinization or pruning),然后应用scale的逆。
对于大多数操作,我们不想缩放LM概率;但是,有时这样做可能是有用的,例如在鉴别训练discriminative training中,同时调整LM和acoustic scale可能是有用的。
lattice scale程序接受选项–lm2acoustic-scale 和 –acoustic2lm-scale。
这里特别介绍一下四种scale:
1.lm_scale:语言模型的尺度,对弧上的第一个weight也就是LM(graph)weight进行缩放
2.acoustic_scale:声学模型的尺度,对弧上的第二个weight也就是acoustic weight进行缩放。
3.acoustic2lm_scale:将声学模型的代价按照这个尺度加到语言模型的代价上面,也就是原始声学模型的代价乘以acoustic2lm_scale加到第一个weight(语言模型的代价)上面。
4.lm2acoustic_scale:将语言模型的代价按照这个尺度加到声学模型的代价上面,也就是原始语言模型的代价乘以lm2acoustic_scale加到第二个weight(声学模型的代价)上面。
关键的代码如下:
/*
scale[0][0] = lm_scale;
scale[0][1] = acoustic2lm_scale;
scale[1][0] = lm2acoustic_scale;
scale[1][1] = acoustic_scale;
*/
{
// Without the next special case we'd get NaNs from infinity * 0
if (w.Value1() == std::numeric_limits<FloatType>::infinity())
return LatticeWeightTpl<FloatType>::Zero();
return LatticeWeightTpl<FloatType>(scale[0][0] * w.Value1() + scale[0][1] * w.Value2(),
scale[1][0] * w.Value1() + scale[1][1] * w.Value2());
}
Determinization of lattices
程序lattice-determinize实现了lattice-determinization,它本质上包括对lattice中的每个字序列只保留 transition-ids的最佳评分序列。
一般来说,这个过程对acoustic scale 很敏感(因为”best-scoring”取决于scale),但是如果之前确定了lattice,然后仅以“词级”的方式处理了格,即每个词序列仍然只有一个transition-ids序列,那么acoustic scale无关紧要。
acoustic scale唯一可能起作用的时间是生成state-level lattices,,例如使用–determinize lattice=false生成lattice。这个程序还有其他选项,这些选项主要与determinization “blows up”时的操作有关,即耗尽内存,但一般来说,您可以将它们保留为默认值。
这主要是因为以前的决定版本倾向于耗尽内存。如果希望作为同一程序的一部分进行 剪枝pruning,则可能需要设置–prune=true,但请注意,这仅在将声学比例设置为适当值时才有意义;在这种情况下,还可能需要设置–beam选项。
使用方法:
lattice-determinize ark:1.lats ark:det.lats
或
lattice-determinize --acoustic-scale=0.08333 ark:state_level.lats ark:1.lats
lattice-determinize-pruned.cc
Determinize lattices,只保留每个输入符号序列的最佳路径(声学状态序列)。此版本将修剪作为确定算法的一部分,该算法效率更高,可防止内存爆炸。
代码部分的话只要是调用了DeterminizeLatticePruned() 进行一个剪枝以及之后进行的一个最小化。
剪枝方法参考上面的:Pruning lattices
Lattice union
程序 lattice-union 计算两个lattice的并集(与其他程序一样,此程序迭代存档中的lattice集合)。这种方法的主要用途是用于鉴别训练 discriminative training(特别是MMI),以确保分母lattice中存在正确的转录。命令行示例如下:
lattice-union ark:num_lats.ark ark:den_lats.ark ark:augmented_den_lats.ark
这个程序调用OpenFst的Union()函数,然后lattice确定每个单词序列只有一个路径,然后写出lattice。实际上,在许多情况下,合并lattice并没有意义(例如,在使用不同特征或模型计算的格上进行并没有多大意义)。
仔细看一下源代码,发现具体的过程就是将同一句话对应的lattice进行合并,然后在进行我上一个解释的操作 DeterminizeLattice,确保一个字序列只保留他评分最高的那个transition-ids路径。
for (; !lattice_reader1.Done(); lattice_reader1.Next()) {
std::string key = lattice_reader1.Key();
Lattice lat1 = lattice_reader1.Value();
lattice_reader1.FreeCurrent();
if (lattice_reader2.HasKey(key)) {
const Lattice &lat2 = lattice_reader2.Value(key);
Union(&lat1, lat2);
n_union++;
} else {
KALDI_WARN << "No lattice found for utterance " << key << " in "
<< lats_rspecifier2 << ". Result of union will be the "
<< "lattice found in " << lats_rspecifier1;
n_no_lat++;
}
Invert(&lat1); // so that word labels are on the input.
CompactLattice clat_out;
DeterminizeLattice(lat1, &clat_out);
// The determinization obviates the need to convert to conpact lattice
// format using ConvertLattice(lat1, &clat_out);
compact_lattice_writer.Write(key, clat_out);
n_done++;
}
看以下两张图,上面的是合并之前,下面的合并之后,因为合并之后会有一个DeterminizeLattice的过程,所以第二张的lattice的路径只有一条了。


Lattice projection
projection是一种FST操作,它通过将输出符号复制到输入,或将输入符号复制到输出,从而将FST转换为接受方,因此它们都是相同的。lattice project的默认设置是将单词标签复制到输入端(这在对lattice的分数进行interpolation插值时非常有用)。例如:
lattice-project ark:1.lats ark:- | \
lattice-compose ark:- ark:2.lats ark:3.lats
例子参考fst官网:
传送门
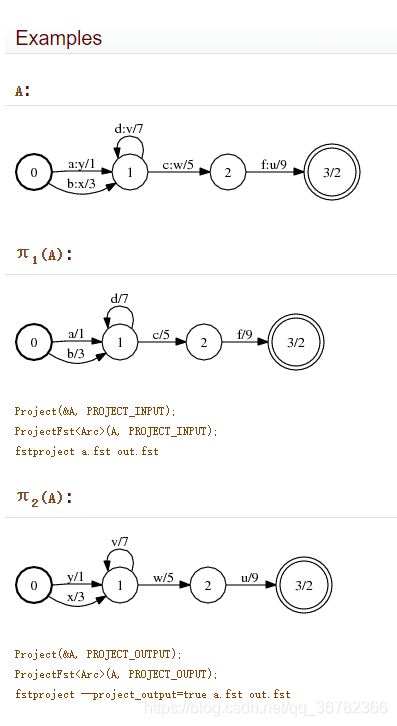
lattice-project.cc
"Project lattices (in their transducer form); by default makes them\n"
"word->word transducers (set --project-output=false for tid->tid).\n"
"Usage: lattice-project [options] lattice-rspecifier lattice-wspecifier\n"
" e.g.: lattice-project ark:1.lats ark:word2word.lats\n"
"or: lattice-project --project-output=false ark:1.lats ark:tid2tid.lats";
–project-output=true,这个参数默认是true,也就是将lattice的输出端复制到输入端。
–project-output=true的时候将输入端复制到输出端。
代码的话,kaldi这边只是循环每一个lattice,然后调用fst的project()
Lattice composition
程序lattice-compose有几种工作模式。一个与其他lattice组成lattice。这是以传感器形式完成的,即将lattice视为从transition-ids到words的传感器。这通常是在第一次将一组lattice投影到输出后(将输出端复制到输入端,也就是lattice投影之后的输入端和输出端都是投影前的输出端)完成的(得到一个字到字的转换器)。典型用法可能是:
lattice-project ark:1.lats ark:- | \
lattice-compose ark:- ark:2.lats ark:3.lats
现在,3.lats的路径上的权重为1.lats和2.lats的权重之和。您可以使用程序lattice-interp在“一个包”中完成相同的任务(参见下一节)。
另一种模式是用一个固定的FST compose一组lattice。为此,FST被动态地转换为一个lattice;FST权重被解释为lattice weight的“graph part”,即元组的第一部分。使用这一点的一个例子是将lattice转换为phone,然后用词典compose,以转换回单词,例如:
lattice-to-phone-lattice final.mdl ark:1.lats ark:- | \
lattice-compose ark:- Ldet.fst ark:words.lats
这是一个简单的例子;您需要做进一步的处理,从lattice中删除原始的“graph score”,并添加回语法和转换分数。此外,LDET.FST是词典的一种特殊处理版本:具有消歧符号的词典(但没有#0到#0通过语言模型消歧符号的循环),确定并消除歧义符号。
上面描述的模式也可以用于语言模型重新筛选;但是,它也有不同的版本,如下所示(这对于将LM分数添加到lattice中非常有用,假设我们删除了旧的LM分数):
lattice-compose --phi-label=13461 ark:1.lats G.fst ark:2.lats
这里,G.fst是语法,包括输入端的特殊“退避符号”#0,13461是退避符号的数字标签。这种形式的处理将退避符号作为故障转移(使用OpenFST的PimaTHER),这仅在所请求的标签不存在的情况下进行:因此,我们把G.fst当作退避语言模型(backoff language)。
这种方式的compose比把#0变成ε(epsilon)更精确,并且这种composing 使用的频率很高,因为它防止我们在非回退弧存在时采取退避弧(这相当于对语言模型的误解)。实际上,由于处理最终概率的方式,程序lattice-compose要做的事情比用OpenFst的PhiMatcher调用compose复杂一些。因为Compose在计算最终概率时不使用匹配器,所以在计算最终概率时可能无法提取回退弧。因此,在调用合成算法之前,lattice-compose程序必须通过“跟踪”phi弧来修改最终概率。请注意,如果我们把句号符号作为G中的一个标签,这个问题就不存在了,但是在一些脚本中,我们更喜欢移除它。还要注意的是,“phi composition”一般不会正常工作,如果带有phi的FST在同一侧有epsilons。因此,首先从G中去掉epsilons是有意义的。
放两个compose的例子:
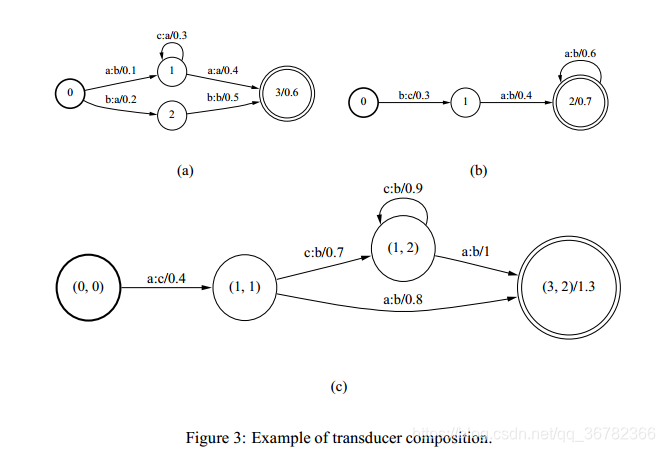

lattice-compose.cc
Composes lattices (in transducer form, as type Lattice).
Depending on the command-line arguments, either composes lattices with lattices,
or lattices with FSTs (rspecifiers are assumed to be lattices, and rxfilenames are assumed to be FSTs,
which have their weights interpreted as "graph weights" when converted into the Lattice format.
Usage: lattice-compose [options] lattice-rspecifier1 (lattice-rspecifier2|fst-rxfilename2) lattice-wspecifier
e.g.: lattice-compose ark:1.lats ark:2.lats ark:composed.lats
or: lattice-compose ark:1.lats G.fst ark:composed.lats
先看一下一个lattice和一个fst的组合方式的代码:
可以主要是根据phi_lable的值去调用fst的compose代码。其中compose官方介绍:
传送门
compose算法的参考博客:
传送门
for (; !lattice_reader1.Done(); lattice_reader1.Next()) {
std::string key = lattice_reader1.Key();
KALDI_VLOG(1) << "Processing lattice for key " << key;
Lattice lat1 = lattice_reader1.Value();
ArcSort(&lat1, fst::OLabelCompare<LatticeArc>());
Lattice composed_lat;
if (phi_label > 0) PhiCompose(lat1, mapped_fst2, phi_label, &composed_lat);
else Compose(lat1, mapped_fst2, &composed_lat);
if (composed_lat.Start() == fst::kNoStateId) {
KALDI_WARN << "Empty lattice for utterance " << key << " (incompatible LM?)";
n_fail++;
} else {
if (write_compact) {
CompactLattice clat;
ConvertLattice(composed_lat, &clat);
compact_lattice_writer.Write(key, clat);
} else {
lattice_writer.Write(key, composed_lat);
}
n_done++;
}
以下是两个lattice要compose的代码,注意要compose的前提是两个lattice要对应于同一句话 ,也就是他们的key是相同的,和union操作的前提条件一样。
else {
std::string lats_rspecifier2 = arg2;
// This is the case similar to lattice-interp.cc, where we
// read in another set of lattices and compose them. But in this
// case we don't do any projection; we assume that the user has already
// done this (e.g. with lattice-project).
RandomAccessLatticeReader lattice_reader2(lats_rspecifier2);
for (; !lattice_reader1.Done(); lattice_reader1.Next()) {
std::string key = lattice_reader1.Key();
KALDI_VLOG(1) << "Processing lattice for key " << key;
Lattice lat1 = lattice_reader1.Value();
lattice_reader1.FreeCurrent();
if (!lattice_reader2.HasKey(key)) {
KALDI_WARN << "Not producing output for utterance " << key
<< " because not present in second table.";
n_fail++;
continue;
}
Lattice lat2 = lattice_reader2.Value(key);
// Make sure that either lat2 is ilabel sorted
// or lat1 is olabel sorted, to ensure that
// composition will work.
if (lat2.Properties(fst::kILabelSorted, true) == 0
&& lat1.Properties(fst::kOLabelSorted, true) == 0) {
// arbitrarily choose to sort lat2 rather than lat1.
fst::ILabelCompare<LatticeArc> ilabel_comp;
fst::ArcSort(&lat2, ilabel_comp);
}
Lattice lat_out;
if (phi_label > 0) {
PropagateFinal(phi_label, &lat2);
PhiCompose(lat1, lat2, phi_label, &lat_out);
} else {
Compose(lat1, lat2, &lat_out);
}
if (lat_out.Start() == fst::kNoStateId) {
KALDI_WARN << "Empty lattice for utterance " << key << " (incompatible LM?)";
n_fail++;
} else {
if (write_compact) {
CompactLattice clat_out;
ConvertLattice(lat_out, &clat_out);
compact_lattice_writer.Write(key, clat_out);
} else {
lattice_writer.Write(key, lat_out);
}
n_done++;
}
}
Lattice interpolation
程序lattice-interp使用一个scale 因子将两组lattice插值在一起。命令行示例如下:
lattice-interp --alpha=0.4 ark:1.lats ark:2.lats ark:3.lats
lattice-interp.cc
获取两个lattice的存档(由语句索引)并将两个lattice组合在一起,形成一个pair(这两个lattice分别从两个存档中取出来的,且对应同一句话)。对齐的话,和第一个lattice的对齐一样。
相当于:
1.将第二个存档投影到单词上(lattice project)(这样的话,第一个lattice是transition-id~ 词,第二个lattice是词~词,为第二步的compose做好准备,compose的话要第一个lattice的输出和第二个lattice的输入相对应)
2…然后将graph and acoustic cost根据lattice scale缩放一定比例,可以使用–alpha控制各个比例。注意alpha是第一个lattice的缩放比例,而1-alpha是第二个lattice的缩放比例。(lattice-scale).
3.最后对两个已经缩放不同比例lattice,进行组合(lattice compose)
用法:lattice interp[选项]lattice-rsspecifier-a lattice-rsspecifier-b lattice wsspecifier
e.g.: lattice-compose ark:1.lats ark:2.lats ark:composed.lats
以下的代码可以看到,首先读取第一个lats文件,然后循环里面的每一个lattice,然后对lattice根据alpha进行scalelattice。之后根据lattice对应的key(话语id)查找在第二个lats文件中是否有相应的lattice,如果有的话,同样的方法,根据1-alpha的缩放比例,对lattice进行缩放。这边的话,我的理解是,两个lattice共同生成一个lattice,里面的权重不能有太大的变化,要根据两个lattice的贡献度,加权求和(加权组合)。可以看到两个lattice的缩放比例加起来为1.如果更加侧重第一个lattice的话,可以相对的提高第一个lattice的比例,反之亦然。最后就是通过compose函数将两个lattice组合在一起即可。
for (; !lattice_reader1.Done(); lattice_reader1.Next()) {
std::string key = lattice_reader1.Key();0
Lattice lat1 = lattice_reader1.Value();
lattice_reader1.FreeCurrent();
ScaleLattice(fst::LatticeScale(alpha, alpha), &lat1);
ArcSort(&lat1, fst::OLabelCompare<LatticeArc>());
if (lattice_reader2.HasKey(key)) {
n_processed++;
CompactLattice clat2 = lattice_reader2.Value(key);
RemoveAlignmentsFromCompactLattice(&clat2);
Lattice lat2;
ConvertLattice(clat2, &lat2);
fst::Project(&lat2, fst::PROJECT_OUTPUT); // project on words.
ScaleLattice(fst::LatticeScale(1.0-alpha, 1.0-alpha), &lat2);
ArcSort(&lat2, fst::ILabelCompare<LatticeArc>());
Lattice lat3;
Compose(lat1, lat2, &lat3);
if (lat3.Start() == fst::kNoStateId) { // empty composition.
KALDI_WARN << "For utterance " << key << ", composed result is empty.";
n_empty++;
} else {
n_success++;
CompactLattice clat3;
ConvertLattice(lat3, &clat3);
compact_lattice_writer.Write(key, clat3);
}
} else {
KALDI_WARN << "No lattice found for utterance " << key << " in "
<< lats_rspecifier2 << ". Not producing output";
n_no_2ndlat++;
}
}
Language model rescoring
由于lattice weight的“graph part”(第一部分)包含了语言模型分数与转换模型分数以及任何发音或沉默概率的混合,我们不能用新的语言模型分数代替它,否则我们将失去转换概率和发音概率。
相反,我们必须先减去“旧的”LM概率,然后再加上新的LM概率。这两个阶段的中心操作是compose(也有一些权重的缩放)。执行此操作的命令行是:首先,要删除旧的LM概率:
lattice-lmrescore --lm-scale=-1.0 ark:in.lats G_old.fst ark:nolm.lats
然后增加新的LM模型的概率
lattice-lmrescore --lm-scale=1.0 ark:nolm.lats G_new.fst ark:out.lats
注意:上面的例子稍微简化了一点;实际上,您必须在输出中“project”G.fst,以便使用带有“projectúoutput=true”的“fstproject”删除消歧符号,请参见steps/lmrescore.sh以获取示例。
还有其他方法可以做到这一点;请参阅下面的lattice-compose文档。lattice lmrescore程序所做的实际上,我们将首先描述一个简单的版本,它并不完全是发生了什么。
假设给我们一个LM-scale S和LM G.fst。
1.我们首先将G.fst中的所有cost乘以S(lattice-scale)
2.然后对每个lattice,我们用合适的G.fst compose it(lattice-compose)
3.lattice-determinization(对于每个单词序列,只保留通过G的最佳路径)
4.write lattice
对于正数S来说,这是很好的,但是对于负数S,这相当于对每个单词序列采取最坏的路径通过G。
为了解决这个问题,我们改为如下操作:
1.对于每个输入的lattice,我们首先将lattice graph weight(或LM)的代价按s的倒数进行缩放;
2…然后对每个lattice,我们用合适的G.fst compose it(lattice-compose)
3.在生成的lattice上运行lattice-determinization(见上文),对于每个字序列,该lattice仅保留通过格的最佳路径;
4.然后,我们将lattice的graph/LM分数按s缩放。
这对负s来说是正确的。只有当输入lattice对每个单词序列只有一条路径时(例如,如果它是lattice-determinization),整个方法才有意义。我们假设程序之间传递的所有lattice都有这个属性(这就是为什么写”raw” state-level lattices不是一个好主意,除非你知道你在做什么)。
请注意,为了使compose程序能够工作,这个程序需要将G.fst从tropical 半环映射到lattice weight 半环。
它通过将G.fst的权重放入权重的第一部分(“graph”部分),并保留权重的第二部分为0(在半环中,这是1)。
在C++级别,这个映射是使用OpenFST的MapFst 机制来完成的,其中我们定义一个映射器类来将StdArc 映射到LatticeArc,然后创建一个MapFst 类型的对象,该对象根据需求进行评估,并将G.FST转换为LatticeWeight 权重类型。
Conversion of lattices to phones
程序lattice-to-phone-lattice 从lattice的输出端移除单词标签,然后将音素标签放入到输出端。这些是从输入端的transition-ids中计算出来的。请注意,phone lables并没有完全与音素边界对齐(通常,fst没有输入和输出符号对齐的真正概念)。典型用法是:
lattice-to-phones final.mdl ark:1.lats ark:phones.lats
lattice-to-phone-lattice.cc
compactlattice类型会保存一个transition-id序列
这个函数能够将输出端的单词或保存的transition-id序列转换成phone序列,phone由transition-id计算出来。如果–replace words=true(默认为true),则用phones替换单词,否则替换transition-id序列。
这边的的理解是,transition-id能够推出单词,transition-id能够推出phone,然后我们这个文件的功能就是将transition-id(保存的序列,不是输入端!!)或者单词(输出端)替换成phone。
如果–replace words=false,它将保留转换id/phones到words的对齐方式,因此,如果您执行lattice-align-words | lattice-to-phone-lattice –replace words=false,则可以得到对应于lattice中每个单词的phones。
Usage: lattice-to-phone-lattice [options] model lattice-rspecifier lattice-wspecifier
e.g.: lattice-to-phone-lattice 1.mdl ark:1.lats ark:phones.lats\
See also: lattice-align-words, lattice-align-phones\n"
replace=true,也就是替换输出端的单词为phone,以下是lattice-to-phone-lattice.cc中的代码:
for (; !clat_reader.Done(); clat_reader.Next()) {
if (replace_words) {
Lattice lat;
ConvertLattice(clat_reader.Value(), &lat);
ConvertLatticeToPhones(trans_model, &lat); // this function replaces words -> phones
CompactLattice clat;
ConvertLattice(lat, &clat);
clat_writer.Write(clat_reader.Key(), clat);
} else { // replace transition-ids with phones.
CompactLattice clat(clat_reader.Value());
ConvertCompactLatticeToPhones(trans_model, &clat);
// this function replaces transition-ids with phones. We do it in the
// CompactLattice form, in order to preserve the alignment of
// transition-id sequences/phones-sequences to words [e.g. if you just
// did lattice-align-words].
clat_writer.Write(clat_reader.Key(), clat);
}
n_done++;
}
KALDI_LOG << "Done converting " << n_done << " lattices.";
return (n_done != 0 ? 0 : 1);
}
这个代码中比较核心的是哪个转换音素的函数,可以看到我们枚举lattice的每个state中的每一条弧,然后通过trans.TransitionIdToPhone()将相应的输出端的标签转化为音素。
{
typedef LatticeArc Arc;
int32 num_states = lat->NumStates();
for (int32 state = 0; state < num_states; state++) {
for (fst::MutableArcIterator<Lattice> aiter(lat, state); !aiter.Done();
aiter.Next()) {
Arc arc(aiter.Value());
arc.olabel = 0; // remove any word.
if ((arc.ilabel != 0) // has a transition-id on input..
&& (trans.TransitionIdToHmmState(arc.ilabel) == 0)
&& (!trans.IsSelfLoop(arc.ilabel))) {
// && trans.IsFinal(arc.ilabel)) // there is one of these per phone...
arc.olabel = trans.TransitionIdToPhone(arc.ilabel);
}
aiter.SetValue(arc);
} // end looping over arcs
} // end looping over states
}
replace=false,也就是替换transition-id序列为phone序列,以下是lattice-to-phone-lattice.cc中的代码:
else { // replace transition-ids with phones.
CompactLattice clat(clat_reader.Value());
ConvertCompactLatticeToPhones(trans_model, &clat);
// this function replaces transition-ids with phones. We do it in the
// CompactLattice form, in order to preserve the alignment of
// transition-id sequences/phones-sequences to words [e.g. if you just
// did lattice-align-words].
clat_writer.Write(clat_reader.Key(), clat);
}
这个代码中首先要将其转化为compactlattice,因为只有compactlattice才有transition-ids序列。然后通过 ConvertCompactLatticeToPhones(trans_model, &clat);将其转为音素序列。看一下这个函数的代码:
{
typedef CompactLatticeArc Arc;
typedef Arc::Weight Weight;
int32 num_states = clat->NumStates();
for (int32 state = 0; state < num_states; state++) {
for (fst::MutableArcIterator<CompactLattice> aiter(clat, state);
!aiter.Done();
aiter.Next()) {
Arc arc(aiter.Value());
std::vector<int32> phone_seq;
const std::vector<int32> &tid_seq = arc.weight.String();
for (std::vector<int32>::const_iterator iter = tid_seq.begin();
iter != tid_seq.end(); ++iter) {
if (trans.IsFinal(*iter))// note: there is one of these per phone...
phone_seq.push_back(trans.TransitionIdToPhone(*iter));
}
arc.weight.SetString(phone_seq);
aiter.SetValue(arc);
} // end looping over arcs
Weight f = clat->Final(state);
if (f != Weight::Zero()) {
std::vector<int32> phone_seq;
const std::vector<int32> &tid_seq = f.String();
for (std::vector<int32>::const_iterator iter = tid_seq.begin();
iter != tid_seq.end(); ++iter) {
if (trans.IsFinal(*iter))// note: there is one of these per phone...
phone_seq.push_back(trans.TransitionIdToPhone(*iter));
}
f.SetString(phone_seq);
clat->SetFinal(state, f);
}
} // end looping over states
}
Lattice equivalence testing
lattice-equivalent是用来debugg的。他的作用是用来测试一组lattice是否相等。
当两个archives中所有对应的lattice都相同的时候,他会返回0.。它使用一个随机等价测试算法来完成这项工作。一个典型的用法是:
lattice-equivalent ark:1.lats ark:2.lats || echo "Not equivalent!"
lattice-equivalent.cc
Usage: lattice-equivalent [options] lattice-rspecifier1 lattice-rspecifier2
e.g.: lattice-equivalent ark:1.lats ark:2.lats\n";
参数:
po.Register("delta", &delta,
"Delta parameter for equivalence test");
po.Register("num-paths", &num_paths,
"Number of paths per lattice for testing randomized equivalence");
po.Register("max-error-proportion", &max_error_proportion,
"Maximum proportion of missing 2nd lattices, or inequivalent "
"lattices, we allow before returning nonzero status");
首先看一下代码,我们要记录两种错误,一种错误是对于一句话,第一个lats中有相应的lattice,而第二个lats中没有相应的lattice。另一种错误就是,比较一句话对应的两个lattice,如果不同则错误,n_inequivalent。
max-error-proportion这个参数可以理解为错误的容错率,可以接受的错误的数量max_bad=所有lattice的数量*max-error-proportion。如果第一种错误的数量n_no2nd大于max_bad的时候,他会返回-1。如果第二种错误的数量大于max_bad的话,会返回-1.如果这两种错误的数量都小于max_bad的话,则返回0,也就是这两个latice可以看做是一样的。
delta这个参数,我看fst中RandEquivalent的代码,我个人理解是权重的偏差,比较两个lattice弧上的权重的时候,如果小于这个偏差的话,可以看做是这个弧的权重是一样的。
num-paths 可以理解为lattice中有很多路径,这边只是随机几条路径去检测,减少计算量。
for (; !lattice_reader1.Done(); lattice_reader1.Next()) {
std::string key = lattice_reader1.Key();
const Lattice &lat1 = lattice_reader1.Value();
if (!lattice_reader2.HasKey(key)) {
KALDI_WARN << "No 2nd lattice present for utterance " << key;
n_no2nd++;
continue;
}
const Lattice &lat2 = lattice_reader2.Value(key);
if (fst::RandEquivalent(lat1, lat2, num_paths, delta, Rand())) {
n_equivalent++;
KALDI_LOG << "Lattices were equivalent for utterance " << key;
} else {
n_inequivalent++;
KALDI_LOG << "Lattices were inequivalent for utterance " << key;
}
}
KALDI_LOG << "Done " << (n_equivalent + n_inequivalent) << " lattices, "
<< n_equivalent << " were equivalent, " << n_inequivalent
<< " were not; for " << n_no2nd << ", could not find 2nd lattice.";
int32 num_inputs = n_equivalent + n_inequivalent + n_no2nd;
int32 max_bad = max_error_proportion * num_inputs;
if (n_no2nd > max_bad) return -1; // treat this as error.
else return (n_inequivalent > max_bad ? 1 : 0);
}
Removing alignments from lattices
程序lattice-rmali从lattice的输入端移除对齐信息(即transition-id)。如果您不需要这些信息(例如,您只需要用于语言模型重新排序的lattice),并且希望节省磁盘空间,那么这一点非常有用。例如
lattice-rmali ark:in.lats ark:word.lats
lattice-rmali.cc
"Remove state-sequences from lattice weights\n"
"Usage: lattice-rmali [options] lattice-rspecifier lattice-wspecifier\n"
" e.g.: lattice-rmali ark:1.lats ark:proj.lats\n";
for (; !lattice_reader.Done(); lattice_reader.Next()) {
std::string key = lattice_reader.Key();
CompactLattice clat = lattice_reader.Value();
lattice_reader.FreeCurrent();
RemoveAlignmentsFromCompactLattice(&clat);
compact_lattice_writer.Write(key, clat);
n_done++;
}
然后看一下这里面调用的关键的函数RemoveAlignmentsFromCompactLattice(),上面的代码只要是枚举lattice,然后对每一个lattice调用RemoveAlignmentsFromCompactLattice()这个函数将对齐序列(也就是transition-ids序列)清楚。
我们看一下以下的内容就是RemoveAlignmentsFromCompactLattice()函数,他的清楚的方式就是将对每条弧的权重进行重新的赋值初始化,可以看到weight的值然后是之前的值没有变化,但是对齐序列(也就是transition-ids序列)他赋值了一个空的std::vector()数组。
{
typedef CompactLatticeWeightTpl<Weight, Int> W;
typedef ArcTpl<W> Arc;
typedef MutableFst<Arc> Fst;
typedef typename Arc::StateId StateId;
StateId num_states = fst->NumStates();
for (StateId s = 0; s < num_states; s++) {
for (MutableArcIterator<Fst> aiter(fst, s);
!aiter.Done();
aiter.Next()) {
Arc arc = aiter.Value();
arc.weight = W(arc.weight.Weight(), std::vector<Int>());
aiter.SetValue(arc);
}
W final_weight = fst->Final(s);
if (final_weight != W::Zero())
fst->SetFinal(s, W(final_weight.Weight(), std::vector<Int>()));
}
}
Error boosting in lattices
程序lattice-boost-ali用于增强MMI训练。它读入一个lattice 和一个对齐alignment (both as tables, e.g. archives),并输出带有语言模型分数LM score(即graph part of the scores)增长的lattice,该分数的增长由参数b乘以该路径上的frame-level phone errors的数量而来。典型用法是:
lattice-boost-ali --silence-phones=1:2:3 --b=0.1 final.mdl ark:1.lats \
ark:1.ali ark:boosted.lats
SIL phone 被特殊处理:无论它们出现在lattice中的哪个位置,它们都被指定为
零错误
,即它们不被计算为错误(此行为可通过–max-silence选项控制)。请注意,这种SIL的特殊处理方法是从MPE训练中采用的,似乎有帮助;我们还没有调查它对增强MMI的确切影响。
lattice-boost-ali.cc
根据lattice中的每个弧上b*(帧音素错误),将graph的likelihood增加(降低graph cost)。有助于鉴别训练 discriminative training,,例如提高MMI。修改输入的lattice。此版本采用对齐形式的引用。需要模型(只是transition)来将pdf-id转换为音素。使用–silence-phones选项,lattice中出现的这些音素始终被指定为零错误,或者使用–max-silence-error选项,最多每帧的错误计数(–max silence error=1相当于没有去指定–silence-phones)。
"Usage: lattice-boost-ali [options] model lats-rspecifier ali-rspecifier lats-wspecifier\n"
" e.g.: lattice-boost-ali --silence-phones=1:2:3 --b=0.05 1.mdl ark:1.lats ark:1.ali ark:boosted.lats\n";
以下是三个参数的介绍:
po.Register("b", &b,
"Boosting factor (more -> more boosting of errors / larger margin)");
po.Register("max-silence", &max_silence_error,
"Maximum error assigned to silence phones [c.f. --silence-phones option]."
"0.0 -> original BMMI paper, 1.0 -> no special silence treatment.");
po.Register("silence-phones", &silence_phones_str,
"Colon-separated list of integer id's of silence phones, e.g. 46:47");
po.Read(argc, argv);
以下是lattice-boost-ali.cc的关键部分的代码。其中主要介绍一下LatticeBoost()函数
for (; !lattice_reader.Done(); lattice_reader.Next()) {
std::string key = lattice_reader.Key();
kaldi::Lattice lat = lattice_reader.Value();
lattice_reader.FreeCurrent();
if (lat.Start() == fst::kNoStateId) {
KALDI_WARN << "Empty lattice for utterance " << key;
n_err++;
continue;
}
if (b != 0.0) {
if (!alignment_reader.HasKey(key)) {
KALDI_WARN << "No alignment for utterance " << key;
n_no_ali++;
continue;
}
const std::vector<int32> &alignment = alignment_reader.Value(key);
if (!LatticeBoost(trans, alignment, silence_phones, b,
max_silence_error, &lat)) {
n_err++; // will already have printed warning.
continue;
}
}
kaldi::CompactLattice clat;
ConvertLattice(lat, &clat);
compact_lattice_writer.Write(key, clat);
n_done++;
}
KALDI_LOG << "Done " << n_done << " lattices, missing alignments for "
<< n_no_ali << ", other errors on " << n_err;
return (n_done != 0 ? 0 : 1);
}
LatticeBoost()
bool LatticeBoost ( const TransitionModel & trans,
const std::vector< int32 > & alignment,
const std::vector< int32 > & silence_phones,
BaseFloat b,
BaseFloat max_silence_error,
Lattice * lat
)
将LM概率提高b*[帧错误数];等效地,将-b*[帧错误数]添加到每个弧/路径的graph cost中。
如果特定帧上的特定transition-id对应的音素和该帧转录的对齐不匹配的话,则存在帧错误。
也就是某个帧对应一个transition-id,transition-id对于一个音素,如果这个音素和aliment中该帧对应的音素不同的话,就存在帧错误。
这是用于“边缘启发”的discriminative training,尤其是在 Boosted MMI。
TransitionModel用于将lattice输入端的transition-id映射到音素上;
在“silence_phones”中出现的phones被特殊处理,我们用minimum of f 或max_silence_error来替换一个帧的帧错误f(0或1)。
对于正常情况,max_silence_error将为零。成功时返回true,如果存在某种不匹配,则返回false。输入时,silence_phones必须分类和唯一。
这里就简单介绍一下,详细可以看我另一篇博客,关于MMI,区分性训练的:
传送门
Computing posteriors from lattices
程序lattice-to-post 从一个lattice开始计算lattice中transition-id的每帧后验概率。这是通过标准的前向-后向算法实现的。
因为,按照惯例,我们存储的lattice没有任何acoustic scale,所以通常需要提供一个acoustic scale用于前向-后向算法。它还接受一个LM-scale,但默认值(1.0)通常是最合适的。使用此程序的示例如下:
lattice-to-post --acoustic-scale=0.1 ark:1.lats ark:- | \
gmm-acc-stats 10.mdl "$feats" ark:- 1.acc
Copying lattices
程序lattice-copy只是复制一个lattices表(例如archive)。如果您想以文本形式查看二进制fst,这非常有用。
lattice-copy ark:1.lats ark,t:- | head -50
详细参考本人之前的博客:
传送门