一、什么是幂等性
幂等是一个数学与计算机学概念,在数学中某一元运算为幂等时,其作用在任一元素两次后会和其作用一次的结果相同。在计算机中编程中,一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数或幂等方法是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。
二、什么是接口幂等性
在HTTP/1.1中,对幂等性进行了定义。它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外),即第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。这里的副作用是不会对结果产生破坏或者产生不可预料的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
三、为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
-
前端重复提交表单: 在填写一些表格时候,用户填写完成提交,很多时候会因网络波动没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求。
-
用户恶意进行刷单: 例如在实现用户投票这种功能时,如果用户针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符。
-
接口超时重复提交: 很多时候 HTTP 客户端工具都默认开启超时重试的机制,尤其是第三方调用接口时候,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求提交多次。
-
消息进行重复消费: 当使用 MQ 消息中间件时候,如果发生消息中间件出现错误未及时提交消费信息,导致发生重复消费。
-
定时任务重复调用:定时任务使用不当导致同一时间点对同一接口同时调用,入参一致,一个请求多次发生
-
其他对接口存在重复调用的情况
(有的幂等性需要考虑分布式系统,高并发,多线程操作的影响)要引入锁机制(单jvm),分布式锁机制(多jvm)以及在不同场景下的并发多次请求的处理情况是不一样的/
使用幂等性最大的优势在于使接口保证任何幂等性操作,免去因重试等造成系统产生的未知的问题。
四、引入幂等性后对系统的影响
幂等性是为了简化客户端逻辑处理,能放置重复提交等操作,但却增加了服务端的逻辑复杂性和成本,其主要是:
-
把并行执行的功能改为串行执行,降低了执行效率。
-
增加了额外控制幂等的业务逻辑,复杂化了业务功能;
所以在使用时候需要考虑是否引入幂等性的必要性,根据实际业务场景具体分析,除了业务上的特殊要求外,一般情况下不需要引入的接口幂等性。
五、Restful API 接口的幂等性
现在流行的 Restful 推荐的几种 HTTP 接口方法中,分别存在幂等行与不能保证幂等的方法,如下:
-
√ 满足幂等
-
x 不满足幂等
-
– 可能满足也可能不满足幂等,根据实际业务逻辑有关
|
方法类型 |
是否幂等 |
描述 |
|
Get |
√ |
Get 方法用于获取资源。其一般不会也不应当对系统资源进行改变,所以是幂等的。(天然幂等) |
|
Post |
× |
Post 方法一般用于创建新的资源。其每次执行都会新增数据,所以不是幂等的。 |
|
Put |
– |
Put 方法一般用于修改资源。该操作则分情况来判断是不是满足幂等,更新操作中直接根据某个值进行更新,也能保持幂等。不过执行累加操作的更新是非幂等。 |
|
Delete |
– |
Delete 方法一般用于删除资源。该操作则分情况来判断是不是满足幂等,当根据唯一值进行删除时,删除同一个数据多次执行效果一样。不过需要注意,带查询条件的删除则就不一定满足幂等了。例如在根据条件删除一批数据后,这时候新增加了一条数据也满足条件,然后又执行了一次删除,那么将会导致新增加的这条满足条件数据也被删除。 |
六、常见幂等性实现方式
方案一:数据库唯一主键
方案描述
数据库唯一主键的实现主要是利用数据库中主键唯一约束的特性,一般来说唯一主键比较适用于“插入”时的幂等性,其能保证一张表中只能存在一条带该唯一主键的记录。
使用数据库唯一主键完成幂等性时需要注意的是,该主键一般来说并不是使用数据库中自增主键,而是使用分布式 ID 充当主键,这样才能能保证在分布式环境下 ID 的全局唯一性。
适用操作:
-
插入操作
-
删除操作(根据唯一id 删除)
使用限制:
-
需要生成全局唯一主键 ID;
主要流程:
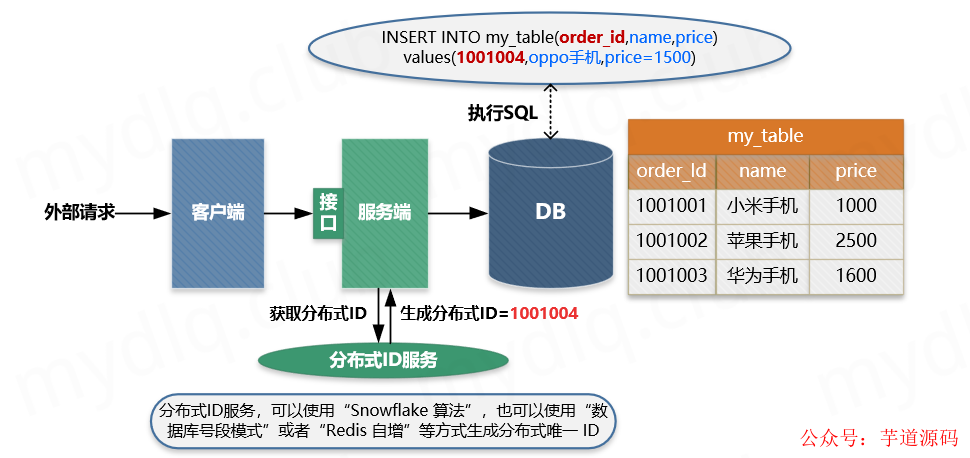
主要流程:
-
① 客户端执行创建请求,调用服务端接口。
-
② 服务端执行业务逻辑,生成一个分布式 ID,将该 ID 充当待插入数据的主键,然后执数据插入操作,运行对应的 SQL 语句。
-
③ 服务端将该条数据插入数据库中,如果插入成功则表示没有重复调用接口。如果抛出主键重复异常,则表示数据库中已经存在该条记录,返回错误信息到客户端。
拓展:当然也可以用唯一索引,
唯一索引
使用唯一索引可以避免脏数据的添加,当插入重复数据时数据库会抛异常,保证了数据的唯一性
绝大数情况下,为了防止重复数据的产生,我们都会在表中加唯一索引,这是一个非常简单,并且有效的方案。
alter table `order` add UNIQUE KEY `un_code` (`code`);
加了唯一索引之后,第一次请求数据可以插入成功。但后面的相同请求,插入数据时会报Duplicate entry ‘002’ for key ‘order.un_code异常,表示唯一索引有冲突。
虽说抛异常对数据来说没有影响,不会造成错误数据。但是为了保证接口幂等性,我们需要对该异常进行捕获,然后返回成功。
如果是java程序需要捕获:DuplicateKeyException异常,如果使用了spring框架还需要捕获:MySQLIntegrityConstraintViolationException异常。
具体流程图如下:
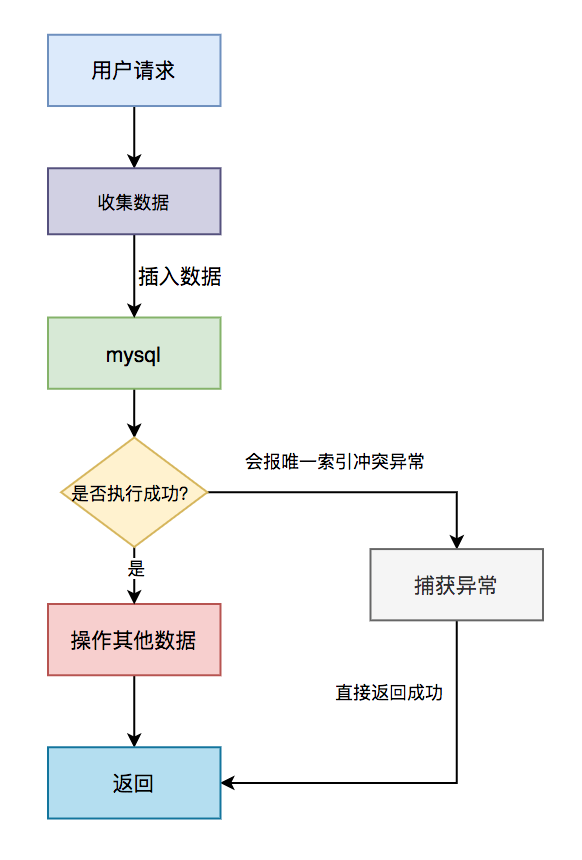
具体步骤:
用户通过浏览器发起请求,服务端收集数据。
将该数据插入mysql
判断是否执行成功,如果成功,则操作其他数据(可能还有其他的业务逻辑)。
如果执行失败,捕获唯一索引冲突异常,直接返回成功。
方案二:数据库乐观锁
方案描述:
数据库乐观锁方案一般只能适用于执行“更新操作”的过程,我们可以提前在对应的数据表中多添加一个字段,充当当前数据的版本标识。这样每次对该数据库该表的这条数据执行更新时,都会将该版本标识作为一个条件,值为上次待更新数据中的版本标识的值。
适用操作:
-
更新操作
-
对新增 和 和删除无效
使用限制:
-
需要数据库对应业务表中添加额外字段;
描述示例:

例如,存在如下的数据表中:
|
id |
name |
price |
|
1 |
小米手机 |
1000 |
|
2 |
苹果手机 |
2500 |
|
3 |
华为手机 |
1600 |
为了每次执行更新时防止重复更新,确定更新的一定是要更新的内容,我们通常都会添加一个 version 字段记录当前的记录版本,这样在更新时候将该值带上,那么只要执行更新操作就能确定一定更新的是某个对应版本下的信息。
|
id |
name |
price |
version |
|
1 |
小米手机 |
1000 |
10 |
|
2 |
苹果手机 |
2500 |
21 |
|
3 |
华为手机 |
1600 |
5 |
这样每次执行更新时候,都要指定要更新的版本号,如下操作就能准确更新 version=5 的信息:
上面 WHERE 后面跟着条件 id=1 AND version=5 被执行后,id=1 的 version 被更新为 6,所以如果重复执行该条 SQL 语句将不生效,因为 id=1 AND version=5 的数据已经不存在,这样就能保住更新的幂等,多次更新对结果不会产生影响。
方案三:防重 Token 令牌
方案描述:
针对客户端对接口连续点击或者调用方的超时重试等情况,例如提交订单,此种操作就可以用 Token 的机制实现防止重复提交。简单的说就是调用方在调用接口的时候先向后端请求一个全局 ID(Token),请求的时候携带这个全局 ID 一起请求(Token 最好将其放到 Headers 中),后端需要对这个 Token 作为 Key,用户信息作为 Value 到 Redis 中进行键值内容校验,如果 Key 存在且 Value 匹配就执行删除命令,然后正常执行后面的业务逻辑。如果不存在对应的 Key 或 Value 不匹配就返回重复执行的错误信息,这样来保证幂等操作。
适用操作:
-
插入操作
-
更新操作
-
删除操作
使用限制:
-
需要生成全局唯一 Token 串;
-
需要使用第三方组件 Redis 进行数据效验;
主要流程:
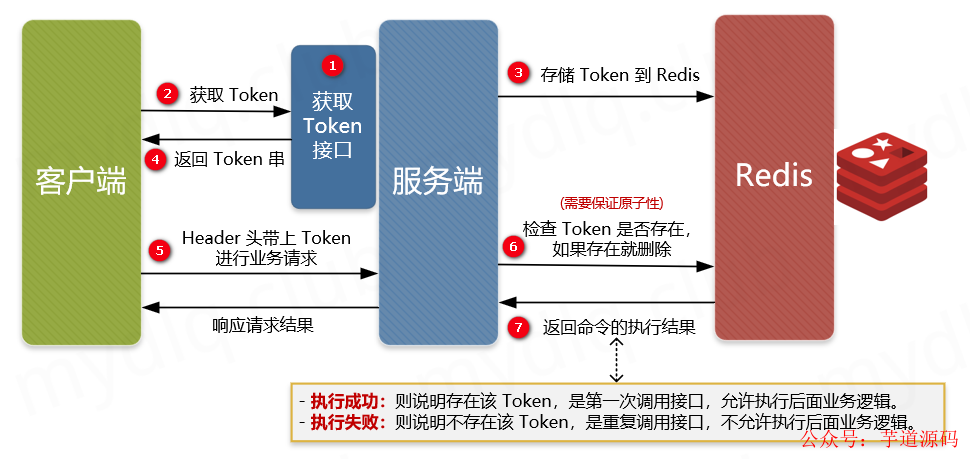
-
① 服务端提供获取 Token 的接口,该 Token 可以是一个序列号,也可以是一个分布式 ID 或者 UUID 串。
-
② 客户端调用接口获取 Token,这时候服务端会生成一个 Token 串。
-
③ 然后将该串存入 Redis 数据库中,以该 Token 作为 Redis 的键(注意设置过期时间)。
-
④ 将 Token 返回到客户端,客户端拿到后应存到表单隐藏域中。
-
⑤ 客户端在执行提交表单时,把 Token 存入到 Headers 中,执行业务请求带上该 Headers。
-
⑥ 服务端接收到请求后从 Headers 中拿到 Token,然后根据 Token 到 Redis 中查找该 key 是否存在。
-
⑦ 服务端根据 Redis 中是否存该 key 进行判断,如果存在就将该 key 删除,然后正常执行业务逻辑。如果不存在就抛异常,返回重复提交的错误信息。
注意,在并发情况下,执行 Redis 查找数据与删除需要保证原子性,否则很可能在并发下无法保证幂等性。其实现方法可以使用分布式锁或者使用 Lua 表达式来注销查询与删除操作。
方案四、下游传递唯一序列号(一般对外接口这么做)
方案描述:
所谓请求序列号,其实就是每次向服务端请求时候附带一个短时间内唯一不重复的序列号,该序列号可以是一个有序 ID,也可以是一个订单号,一般由下游生成,在调用上游服务端接口时附加该序列号和用于认证的 ID。
当上游服务器收到请求信息后拿取该 序列号 和下游 认证ID 进行组合,形成用于操作 Redis 的 Key,然后到 Redis 中查询是否存在对应的 Key 的键值对,根据其结果:
-
如果存在,就说明已经对该下游的该序列号的请求进行了业务处理,这时可以直接响应重复请求的错误信息。
-
如果不存在,就以该 Key 作为 Redis 的键,以下游关键信息作为存储的值(例如下游商传递的一些业务逻辑信息),将该键值对存储到 Redis 中 ,然后再正常执行对应的业务逻辑即可。
适用操作:
-
插入操作
-
更新操作
-
删除操作
使用限制:
-
要求第三方传递唯一序列号;
-
需要使用第三方组件 Redis 进行数据效验;
主要流程:
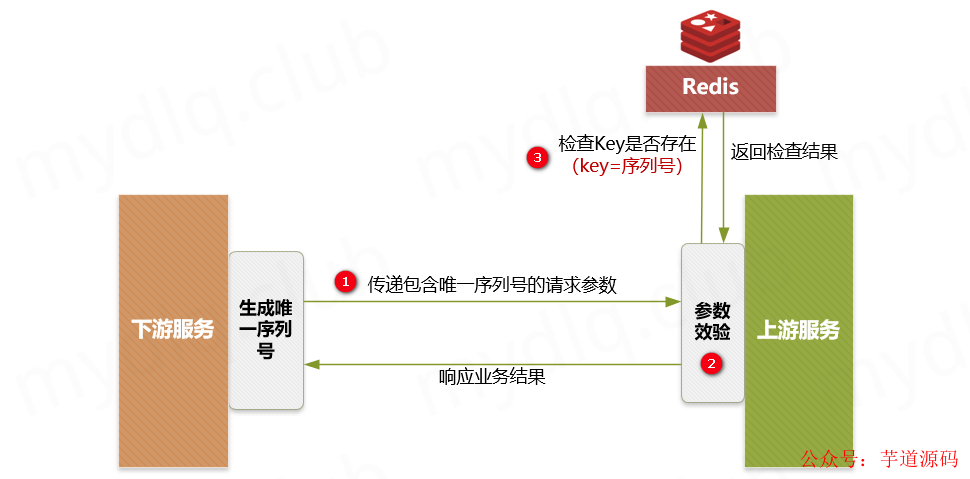
主要步骤:
-
① 下游服务生成分布式 ID 作为序列号,然后执行请求调用上游接口,并附带“唯一序列号”与请求的“认证凭据ID”。
-
② 上游服务进行安全效验,检测下游传递的参数中是否存在“序列号”和“凭据ID”。
-
③ 上游服务到 Redis 中检测是否存在对应的“序列号”与“认证ID”组成的 Key,如果存在就抛出重复执行的异常信息,然后响应下游对应的错误信息。如果不存在就以该“序列号”和“认证ID”组合作为 Key,以下游关键信息作为 Value,进而存储到 Redis 中,然后正常执行接来来的业务逻辑。
上面步骤中插入数据到 Redis 一定要设置过期时间。这样能保证在这个时间范围内,如果重复调用接口,则能够进行判断识别。如果不设置过期时间,很可能导致数据无限量的存入 Redis,致使 Redis 不能正常工作。
拓展:如银联提供的付款接口:需要接入商户提交付款请求时附带:source来源,seq序列号
source+seq在数据库里面做唯一索引,防止多次付款,(并发时,只能处理一个请求)
通常设计到幂等性的问题都需要考虑多线程并发的锁的思路
重点 对外提供接口为了支持幂等调用,接口有两个字段必须传,一个是来源source,一个是来源方序列号seq,这个两个字段在提供方系统里面做联合唯一索引
这样当第三方调用时,先在本方系统里面查询一下,是否已经处理过,返回相应处理结果;没有处理过,进行相应处理,返回结果。
注意,为了幂等友好,一定要先查询一下,是否处理过该笔业务,不查询直接插入业务系统,会报错,但实际已经处理了。
方案五:悲观锁
获取数据的时候加锁获取
select * from table_xxx where id=’xxx’ for update;
注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的
悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用
在支付场景中,用户A的账号余额有150元,想转出100元,正常情况下用户A的余额只剩50元。一般情况下,sql是这样的:
update user amount = amount-100 where id=123;
如果出现多次相同的请求,可能会导致用户A的余额变成负数。这种情况,用户A来可能要哭了。于此同时,系统开发人员可能也要哭了,因为这是很严重的系统bug。
为了解决这个问题,可以加悲观锁,将用户A的那行数据锁住,在同一时刻只允许一个请求获得锁,更新数据,其他的请求则等待。
通常情况下通过如下sql锁住单行数据:
select * from user id=123 for update;
具体流程如下:
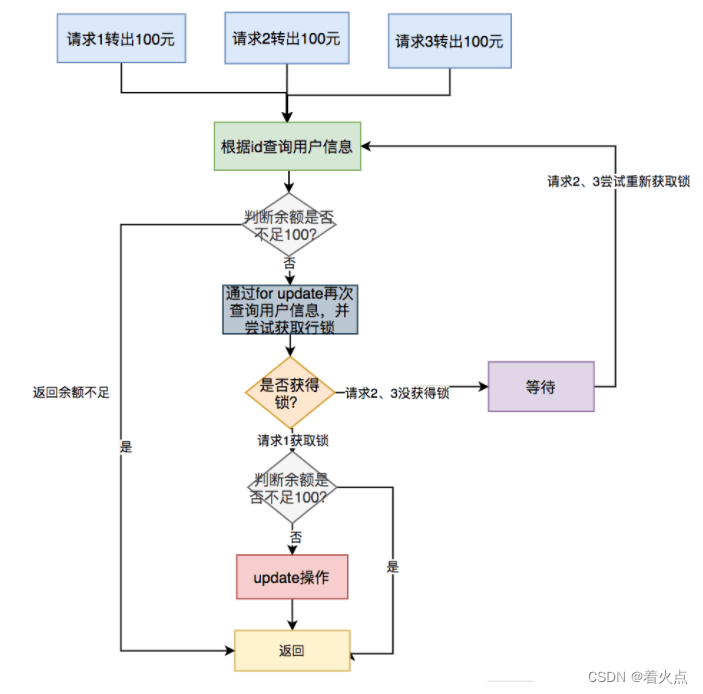
具体步骤:
多个请求同时根据id查询用户信息。
判断余额是否不足100,如果余额不足,则直接返回余额不足。
如果余额充足,则通过for update再次查询用户信息,并且尝试获取锁。
只有第一个请求能获取到行锁,其余没有获取锁的请求,则等待下一次获取锁的机会。
第一个请求获取到锁之后,判断余额是否不足100,如果余额足够,则进行update操作。
如果余额不足,说明是重复请求,则直接返回成功。
需要特别注意的是:如果使用的是mysql数据库,存储引擎必须用innodb,因为它才支持事务。此外,这里id字段一定要是主键或者唯一索引,不然会锁住整张表。
悲观锁需要在同一个事务操作过程中锁住一行数据,如果事务耗时比较长,会造成大量的请求等待,影响接口性能。
此外,每次请求接口很难保证都有相同的返回值,所以不适合幂等性设计场景,但是在防重场景中是可以的使用的。
在这里顺便说一下,防重设计 和 幂等设计,其实是有区别的。防重设计主要为了避免产生重复数据,对接口返回没有太多要求。而幂等设计除了避免产生重复数据之外,还要求每次请求都返回一样的结果。
方案六:状态机幂等
在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机(状态变更图),就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机
如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。
注意:订单等单据类业务,存在很长的状态流转,一定要深刻理解状态机,对业务系统设计能力提高有很大帮助
很多时候业务表是有状态的,比如订单表中有:1-下单、2-已支付、3-完成、4-撤销等状态。如果这些状态的值是有规律的,按照业务节点正好是从小到大,我们就能通过它来保证接口的幂等性。
假如id=123的订单状态是已支付,现在要变成完成状态。
update `order` set status=3 where id=123 and status=2;
第一次请求时,该订单的状态是已支付,值是2,所以该update语句可以正常更新数据,sql执行结果的影响行数是1,订单状态变成了3。
后面有相同的请求过来,再执行相同的sql时,由于订单状态变成了3,再用status=2作为条件,无法查询出需要更新的数据,所以最终sql执行结果的影响行数是0,即不会真正的更新数据。但为了保证接口幂等性,影响行数是0时,接口也可以直接返回成功。
具体流程图如下:
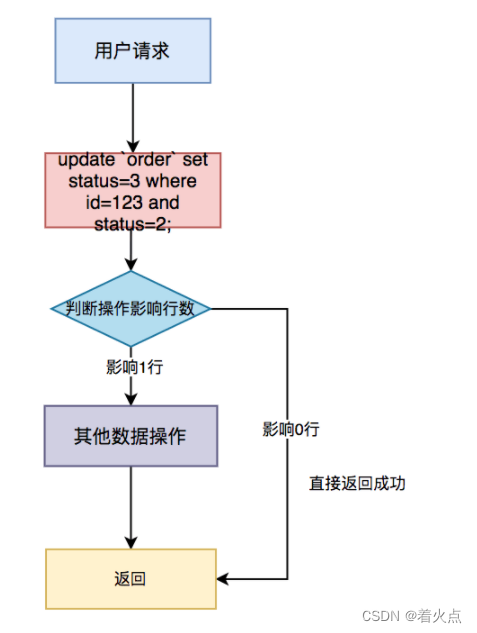
具体步骤:
用户通过浏览器发起请求,服务端收集数据。
根据id和当前状态作为条件,更新成下一个状态
判断操作影响行数,如果影响了1行,说明当前操作成功,可以进行其他数据操作。
如果影响了0行,说明是重复请求,直接返回成功。
主要特别注意的是,该方案仅限于要更新的表有状态字段,并且刚好要更新状态字段的这种特殊情况,并非所有场景都适用
方案七:select + insert
并发不高的后台系统,或者一些任务JOB,为了支持幂等,支持重复执行,简单的处理方法是,先查询下一些关键数据,判断是否已经执行过,在进行业务处理,就可以了
注意:核心高并发流程不要用这种方法
通常情况下,在保存数据的接口中,我们为了防止产生重复数据,一般会在insert前,先根据name或code字段select一下数据。如果该数据已存在,则执行update操作,如果不存在,才执行 insert操作。
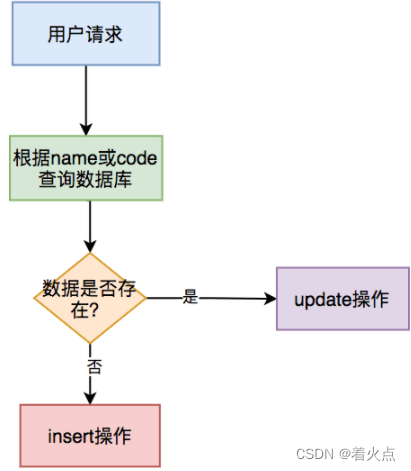
该方案可能是我们平时在防止产生重复数据时,使用最多的方案。但是该方案不适用于并发场景,在并发场景中,要配合其他方案一起使用,否则同样会产生重复数据。我在这里提一下,是为了避免大家踩坑。
方案八:分布式锁
还是拿插入数据的例子,如果是分布是系统,构建全局唯一索引比较困难,例如唯一性的字段没法确定
这时候可以引入分布式锁,通过第三方的系统(redis或zookeeper),在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁
这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路。
要点:某个长流程处理过程要求不能并发执行,可以在流程执行之前根据某个标志(用户ID+后缀等)获取分布式锁,其他流程执行时获取锁就会失败,也就是同一时间该流程只能有一个能执行成功,执行完成后,释放分布式锁(分布式锁要第三方系统提供
幂等的本质是分布式锁的问题,分布式锁正常可以通过redis或zookeeper实现;在分布式环境下,锁定全局唯一资源,使请求串行化,实际表现为互斥锁,防止重复,解决幂等。
其实前面介绍过的加唯一索引或者加防重表,本质是使用了数据库的分布式锁,也属于分布式锁的一种。但由于数据库分布式锁的性能不太好,我们可以改用:redis或zookeeper。
鉴于现在很多公司分布式配置中心改用apollo或nacos,已经很少用zookeeper了,我们以redis为例介绍分布式锁
目前主要有三种方式实现redis的分布式锁:(使用redis分布式锁例子说明)
-
setNx 命令
-
set 命令
-
Redission 框架
具体流程图如下:
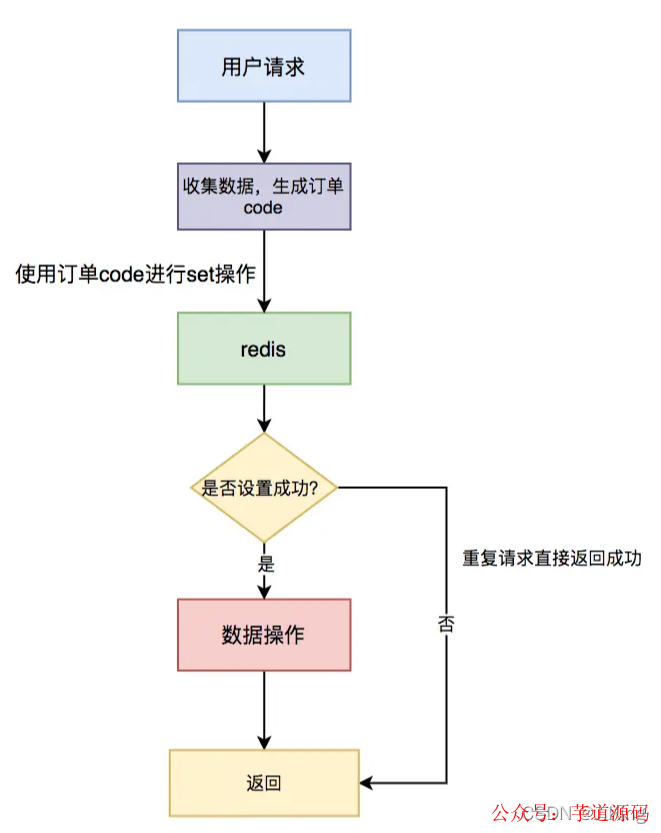
具体步骤:
-
用户通过浏览器发起请求,服务端会收集数据,并且生成订单号 code 作为唯一业务字段。
-
使用 redis 的 set 命令,将该订单 code 设置到 redis 中,同时设置超时时间。
-
判断是否设置成功,如果设置成功,说明是第一次请求,则进行数据操作。
-
如果设置失败,说明是重复请求,则直接返回成功。
需要特别注意的是:分布式锁一定要设置一个合理的过期时间,如果设置过短,无法有效的防止重复请求。如果设置过长,可能会浪费redis的存储空间,需要根据实际业务情况而定。
方案九 建防重表
有时候表中并非所有的场景都不允许产生重复的数据,只有某些特定场景才不允许。这时候,直接在表中加唯一索引,显然是不太合适的。
针对这种情况,我们可以通过建防重表来解决问题。
该表可以只包含两个字段:id 和 唯一索引,唯一索引可以是多个字段比如:name、code等组合起来的唯一标识,例如:susan_0001。
具体流程图如下:
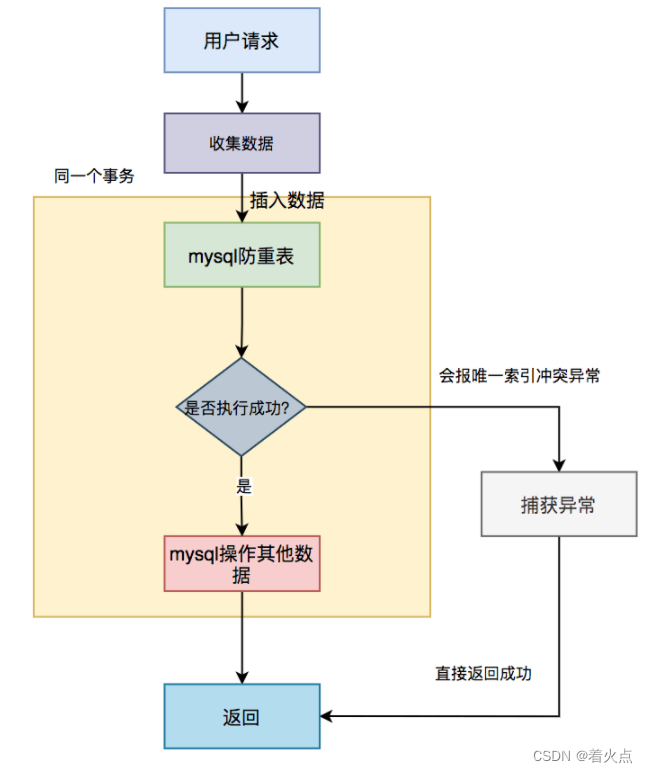
具体步骤:
用户通过浏览器发起请求,服务端收集数据。
将该数据插入mysql防重表
判断是否执行成功,如果成功,则做mysql其他的数据操作(可能还有其他的业务逻辑)。
如果执行失败,捕获唯一索引冲突异常,直接返回成功。
需要特别注意的是:防重表和业务表必须在同一个数据库中,并且操作要在同一个事务中。
七、总结
幂等性是开发当中很常见也很重要的一个需求,尤其是支付、订单等与金钱挂钩的服务,保证接口幂等性尤其重要。在实际开发中,我们需要针对不同的业务场景我们需要灵活的选择幂等性的实现方式:
-
对于下单等存在唯一主键的,可以使用“唯一主键方案”的方式实现。
-
对于更新订单状态等相关的更新场景操作,使用“乐观锁方案”实现更为简单。
-
对于上下游这种,下游请求上游,上游服务可以使用“下游传递唯一序列号方案”更为合理。
-
类似于前端重复提交、重复下单、没有唯一ID号的场景,可以通过 Token 与 Redis 配合的“防重 Token 方案”实现更为快捷。
上面只是给与一些建议,再次强调一下,实现幂等性需要先理解自身业务需求,根据业务逻辑来实现这样才合理,处理好其中的每一个结点细节,完善整体的业务流程设计,才能更好的保证系统的正常运行。最后做一个简单总结,然后本博文到此结束,如下:
|
方案名称 |
适用方法 |
实现复杂度 |
方案缺点 |
|
数据库唯一主键 |
插入操作 删除操作 |
简单 |
– 只能用于插入操作;- 只能用于存在唯一主键场景; |
|
数据库乐观锁 |
更新操作 |
简单 |
– 只能用于更新操作;- 表中需要额外添加字段; |
|
请求序列号 |
插入操作 更新操作 删除操作 |
简单 |
– 需要保证下游生成唯一序列号;- 需要 Redis 第三方存储已经请求的序列号; |
|
防重 Token 令牌 |
插入操作 更新操作 删除操作 |
适中 |
– 需要 Redis 第三方存储生成的 Token 串; |
八(实战) 自主研发的幂等组件
(一)为什么要把幂等抽象成组件
1、幂等处理逻辑与业务处理逻辑分离,职责划分清晰
2、幂等逻辑抽象成组件,复用方便
3、可以更灵活地与现有设施搭配使用
(一)处理流程
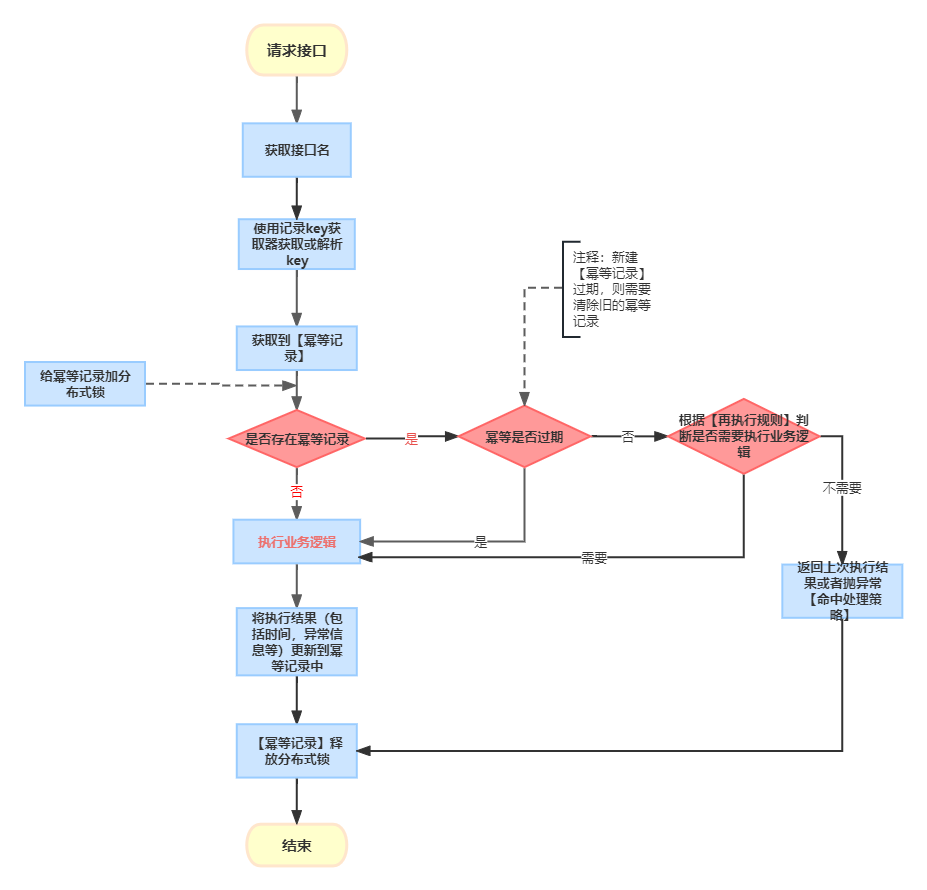
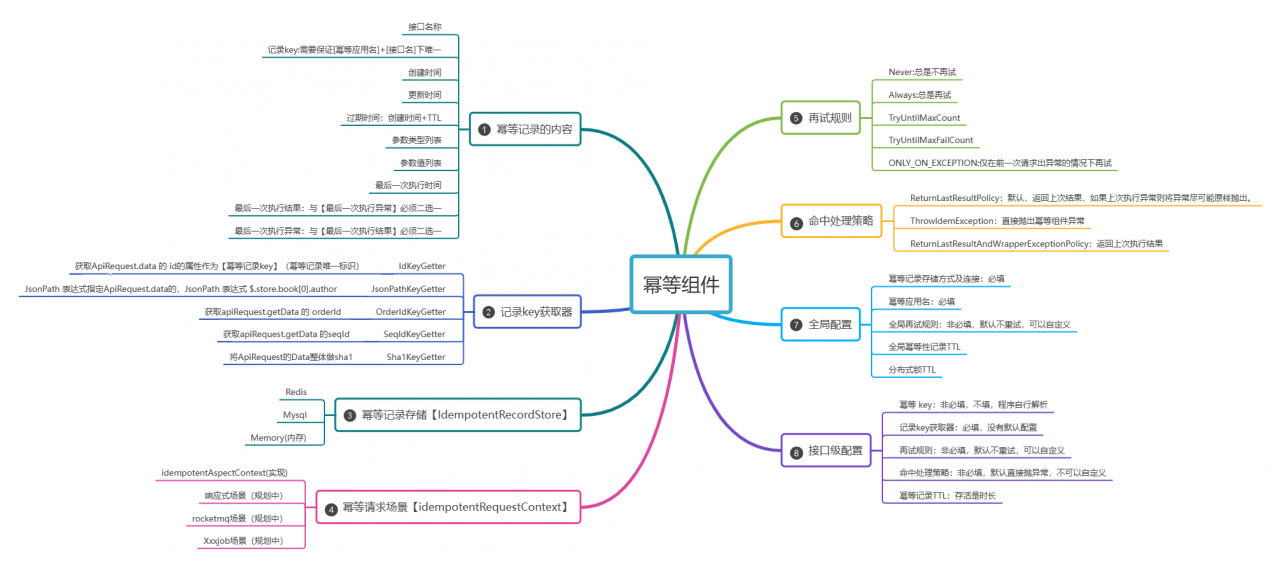
(二)幂等组件关键涉及的关键要素的说明
(三)幂等配置层级
1、接口级配置
2、全局配置
3、默认配置
|
配置项 |
支持接口级 |
支持全局级 |
是否必配置 |
默认 |
是否可以自定义 |
其它注意项 |
|
幂等记录存储方式及连接 |
不支持 |
支持 |
是 |
无 |
N/A |
|
|
幂等应用名 |
不支持 |
支持 |
是 |
无 |
N/A |
|
|
幂等模块名 |
支持 |
不支持 |
否 |
默认,以接口路径作为模块名 |
N/A |
|
|
再试规则 |
支持 |
支持 |
否 |
默认:仅异常下再试, |
可以自定义,组件已预提供如下两个规则:1、不再试,NEVER 2、仅异常下再试,ONLY_ON_ERROR 3、总是再试,ALWAYS |
|
|
幂等记录TTL(秒) |
支持 |
支持 |
否 |
1天 |
N/A |
|
|
分布式锁TTL(秒) |
不支持 |
支持 |
否 |
1分钟 |
N/A |
|
|
获取幂等记录分布式锁超时毫秒数 |
不支持 |
支持 |
否 |
3秒 |
N/A |
|
|
幂等key |
支持 |
不支持 |
是 |
方法签名: 包名+类名+参数类型列表 |
N/A |
|
|
记录key获取器 |
支持 |
不支持 |
否 |
无 |
必需自定义。 组件可以预提供一些: SeqIdKeyGetter,OrderIdKeyGetter |
在同一个【幂等应用名】下唯一 |
|
命中处理策略 |
支持 |
支持 |
否 |
默认:(右列1) |
不可以自定义,目前只有下面两种选项: 1、返回上次结果,如果上次执行异常则将异常尽可能原样抛出。 2、返回上次结果,如果上次执行异常,则先包装一层再抛出 3、直接抛出幂等组件异常 |
|
配置生效优先级,服务启动的时候校验:
1、如果存在接口级配置,则接口级配置生效
2、否则,如果存在全局级配置,则全局级配置生效
3、否则,如果存在默认配置,则默认配置生效
4、否则,如果不是必配项,则结束
5、否则,抛异常
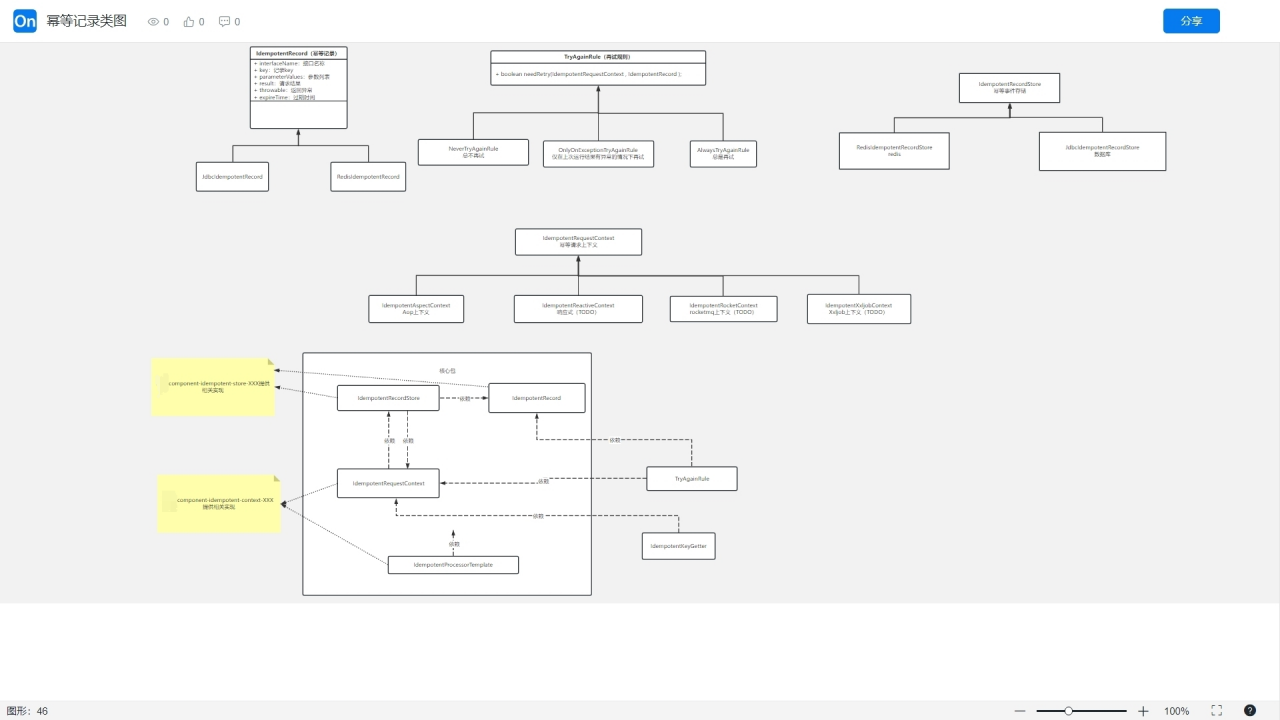
(四)工程类之间的关系图
(五)幂等代码工程结构
xgs-component-idempotent-core 提供核心抽象组件
IdempotentRecord -- 幂等记录
IdempotentRecordStore -- 幂等记录存取
IdempotentRequestContext -- 请求上下文
TryAgainRule -- 再试规则
IdempotentKeyGetter -- 幂等key获取策略
IdempotentRequestProcessorTemplate --- 幂等请求模板方法类
xgs-component-idempotent-context-aop
提供IdempotentRequestContext的具体实现 IdempotentAspectContext
提供IdempotentRequestProcessorTemplate的具体实现 IdempotentAopRequestProcessor
提供@Idempotent 注解
xgs-component-idempotent-context-rocketmq(规划中)
xgs-component-idempotent-context-xxljob(规划中)
xgs-component-idempotent-context-pulsar(规划中)
xgs-component-idempotent-store-jdbc
提供IdempotentRecordStore的实现JdbcIdempotentRecordStore
提供IdempotentRecord子类JdbcIdempotentRecord
xgs-component-idempotent-store-redis
提供IdempotentRecordStore的实现RedisIdempotentRecordStore
提供IdempotentRecord子类RedisIdempotentRecord
(六)使用示例
6.1、参照bop-demo的xgs-idempotent-demo模块
6.2、引入maven依赖
<dependency>
<groupId>com.xgs</groupId>
<artifactId>xgs-component-idempotent-context-aop</artifactId>
</dependency>
<dependency>
<groupId>com.xgs</groupId>
<artifactId>xgs-component-idempotent-store-redis</artifactId>
</dependency>6.3、添加配置
idempotent:
common:
app-name: ${spring.application.name}
error-tip-msg: '幂等处理异常'
distributed-lock-ttl-secs: 3000
redis:
redisson:
single-server-config:
address: 'redis://192.168.4.100:6379'6.4、bean方法使用@Idempotent注解
@RequestMapping("/test1")
@Idempotent(keyGetterClass= DemoKeyGetter.class)
public String test1(@RequestParam("idemkey") String idemkey, @RequestParam("idemkey222") String idemkey222){
return idemkey;
}6.5、提供IdempotentKeyGetter实现(也可以直接使用预提供的,请见附1)
/**
* 总是取第一个参数作为幂等key
*/
public class DemoKeyGetter implements IdempotentKeyGetter {
@Override
public String parseRecordKey(IdempotentRequestContext requestContext) {
Object[] params = requestContext.getParams();
if(params == null){
return null;
}
for (Object param : params) {
if(param!=null){
return param.toString();
}
}
return null;
}
}(七)附录
附1、预提供的IdempotentKeyGetter
IdKeyGetter
获取ApiRequest.data 的 id的属性作为【幂等记录key】(幂等记录唯一标识)
JsonPathKeyGetter
JsonPath 表达式指定ApiRequest.data的,JsonPath 表达式 $.store.book[0].author
OrderIdKeyGetter
获取apiRequest.getData 的 orderId
SeqIdKeyGetter
获取apiRequest.getData 的seqId
Sha1KeyGetter
将ApiRequest的Data整体做sha1
附2、@Idempotent的属性说明
moduleName
幂等模块名,在同一个【幂等应用名】下唯一,可以不填,不填则从接口名作为模块名
keyGetterClass
幂等记录key获取策略,所配置的class必需有无参构造方法。否则考虑用keyGetterBeanName
keyGetterBeanName
幂等记录key获取策略实例bean名称
retryRuleClass
再试规则,所配置的class必需有无参构造方法。否则考虑用retryRuleBeanName
retryRuleBeanName
再试规则bean命称
hitPolicy
命中处理策略
默认 IdempotentHitPolicyEnum.ReturnLastResultAndWrapperExceptionPolicy
recordTtlSecs
幂等记录ttl
附3、命中处理策略
IdempotentHitPolicyEnum.ReturnLastResultPolicy
返回上次结果,如果上次执行异常则将异常尽可能原样抛出。
IdempotentHitPolicyEnum.ReturnLastResultAndWrapperExceptionPolicy
返回上次结果,如果上次执行异常,则先包装一层幂等的异常后再抛出。
IdempotentHitPolicyEnum.ThrowIdemException
直接抛出幂等组件异常
附4、预提供的再试规则
AlwaysTryAgainRuleImpl
总是再试
NeverTryAgainRuleImpl
总是不再试
OnlyOnErrorTryAgainRuleImpl
仅在前一次请求出异常的情况下再试
TryUntilMaxCount
达到最大次后不再重试
TryUntilMaxFailCount
达到最大失败次后不再重试
遇到的问题
1、序列化与反序化:redisson的jackson反序列化不支持没有无参构造方法的类的问题
2、序列化与反序化:redis本身不支持long类型题
(八) github地址
https://github.com/1062141499/xgs-component