在说flink的反压之前,先来说下strom和spark streaming的反压。
Strom 反压
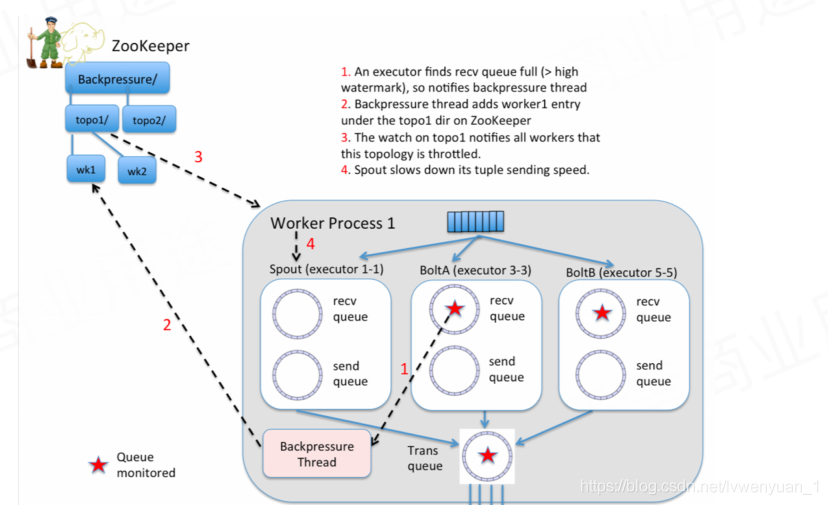
如图是strom的反压,是通过zookeeper来决定的,当strom感受到处理不过来的时候,就会像zookeeper增加一个znode,然后strom发现了这个znode,对应的上游数据就会阻塞,不会发送数据。
Spark Streaming 反压
Spark Streaming的反压是从1.5版本以后引入的。在这之前,基本就是通过控制最大接受速率来控制的。譬如,如果是基于Receiver形式,可以配置spark.streaming.receiver.maxRate。限制每个receiver每秒可以接受的数据。对于Direct方式,我们可以配置spark.streaming.kafka.maxRatePerPartition,来限制每个分区每次所能接受的最大记录数,这个在追kafka数据的时候,极为重要。
这种限制就比较明显了,需要用户自己去预估,如果后端的处理能力远大于我们限制的数据量,那么就会造成资源的浪费。在Spark1.5以后,引入了pid的概念。
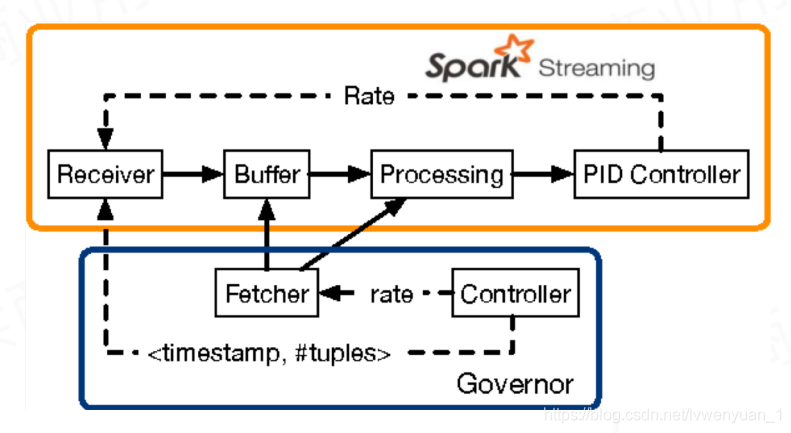
它会从buffer以及各个process中拉去数据,通过processingDelay 、schedulingDelay 、当前 Batch 处理的记录条数以及处理完成事件来估算出一个速率,就是流每秒能处理的最大条数。然后反馈给source端。
Flink反压
flink的反压又分为两个阶段,一个是1.5版本之前,一个是1.5版本以后
在1.5版本以前
Flink的反压是通过TCP的反压机制来控制的
我们来看下flink的网络传输

可以看到Flink在Prodece产生数据后,经过netty使用socket传输,使用的是TCP协议。而TCP自带了反压机制。
TCP的反压,是通过callback实现的,当socket发送数据去receive buffer后,receiver会反馈给send端,目前receiver端的buffer还有多少剩余空间,然后send会根据剩余空间,控制发送速率。
具体的,我可以来看下Flink的ExecutionGraph:
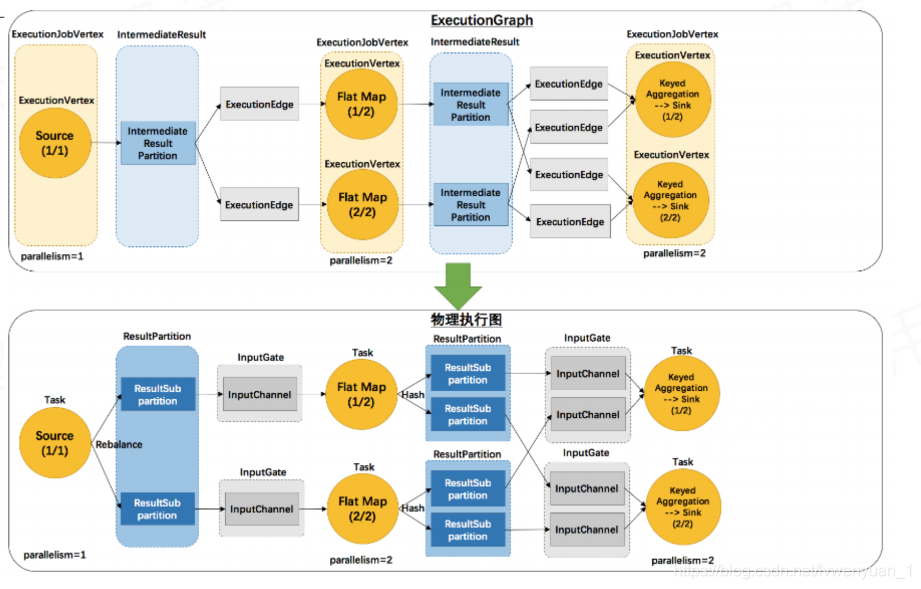
我们可以看到,上游task向下游task传输数据的时候,有ResultPartition和InputGate两个组件。
其中RP用来发送数据,IG用来接收数据。
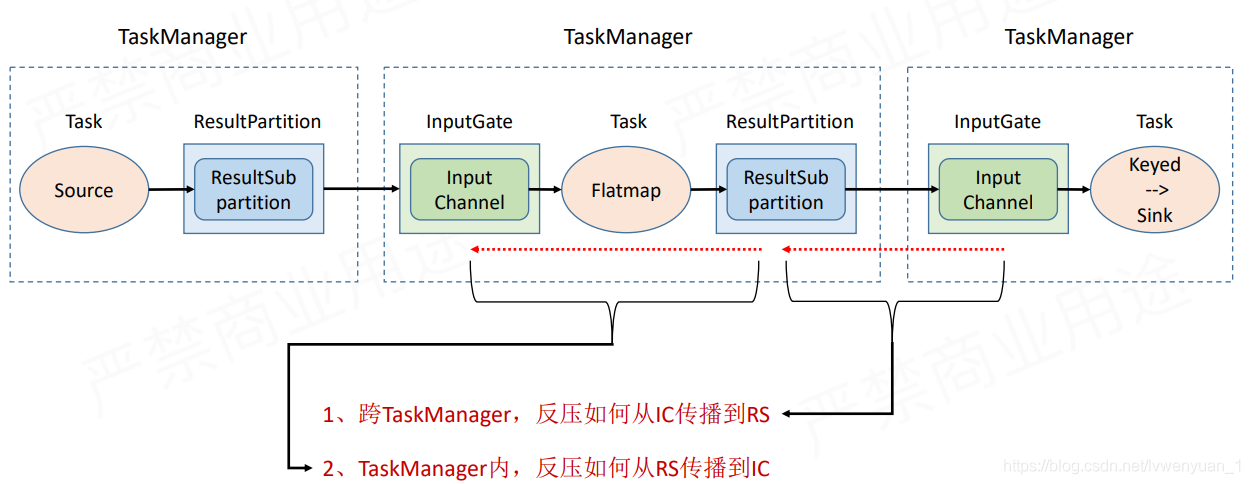
这个问题可以被看成两个问题,一个是夸TaskManager,一个是TaskManager内部。譬如说下游的sink性能出了点问题,那么inputChannel就会告知上个TM的ResultPartition。然后第二个TM中的,RP也会通知该TM中的IG。
先来看第一个问题,跨TM的反压。
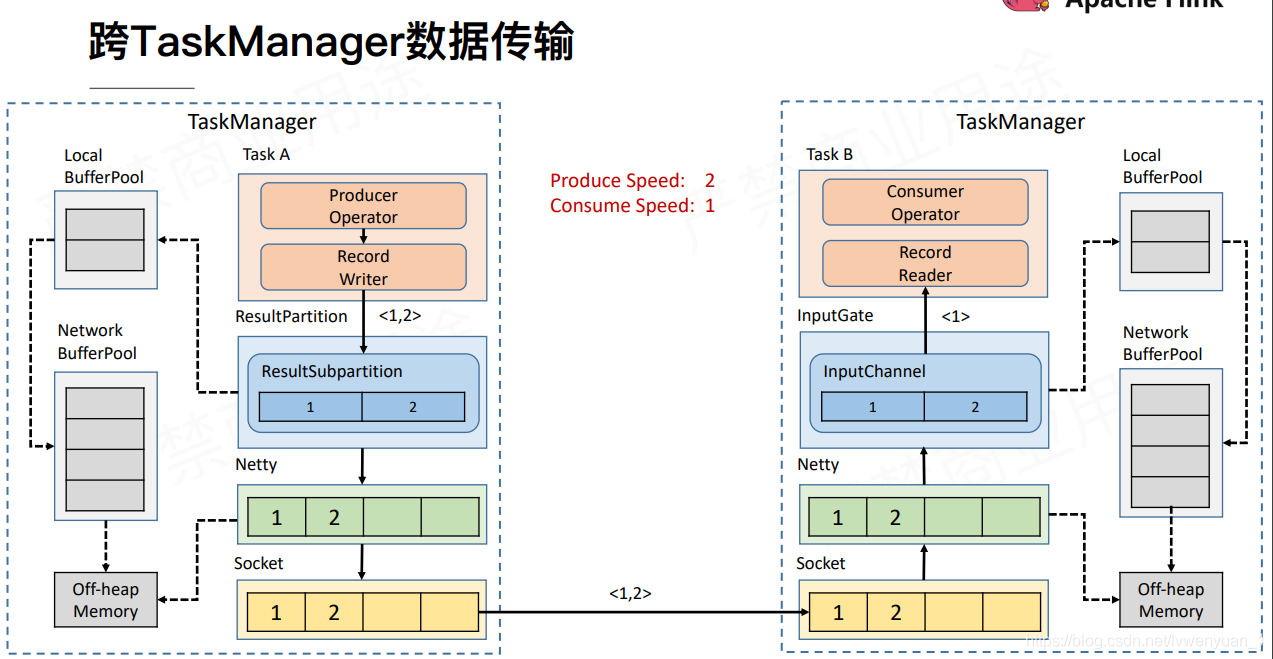
这个是跨TM的网络传输的流程。理解过Flink内存管理的同学都会知道,Flink会向off-heap内存申请一段固定的内存来使用,作为NetWork BufferPool。然后RP和IG都会向LocalBufferPool申请内存资源,LocalBufferPool会向NetWorkBufferPool申请资源。至于Netty直接走的JVM。
当sink端数据处理不过来的时候,IG会不断向LocalBufferPool申请内存,导致LocalBufferPool会不断向NetWorkBufferPool申请内存。最终导致NetworkBufferPool的可用内存被申请完。
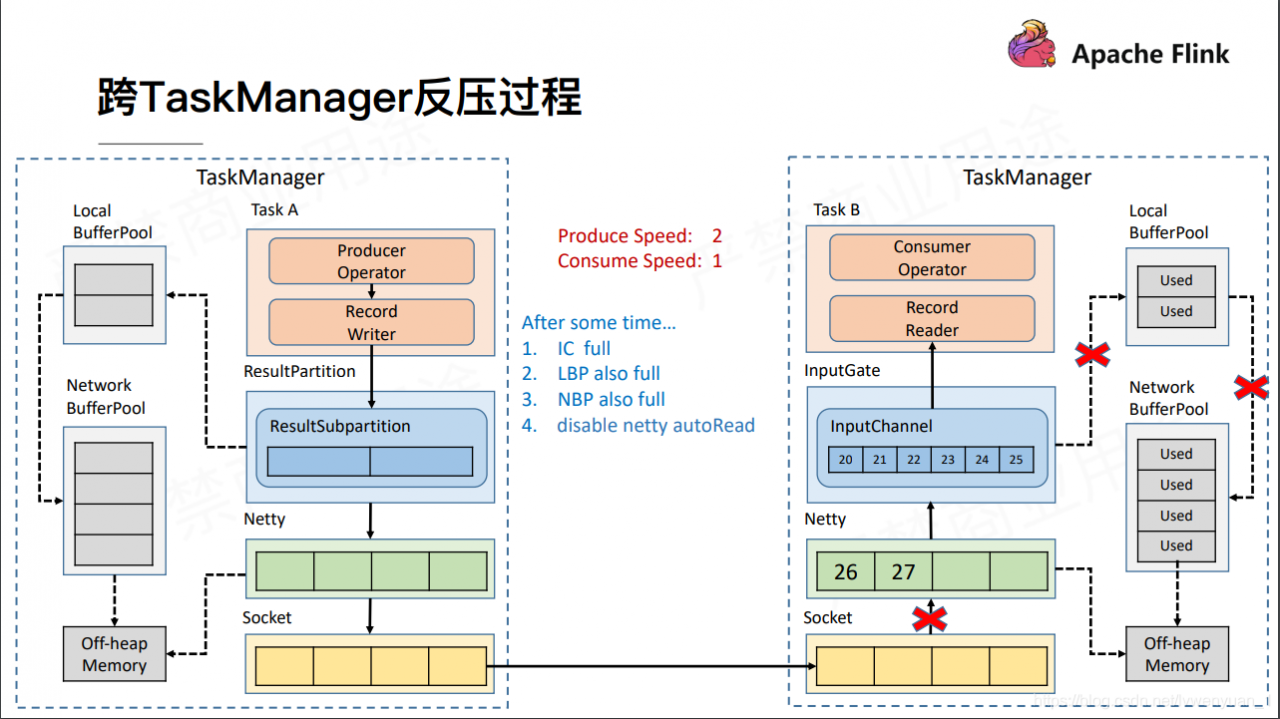
当IG无法写入的时候,就不会去读netty里的数据。当netty的规定缓存被写满了以后,socket就无法往netty里写数据。这个时候,socket的缓存就很快会被用满,使用TCP的ACK机制,通知上游Socket。然后上游的Socket由于无法往外写,所以上游的Socket也很快会被上游的netty写满。
所以此时,数据就会被不断缓存在上游的netty,当上游的netty的buffer写到限制大小后,就会不能被写入。这个时候netty 的 channel.isWritable() 就会返回false。
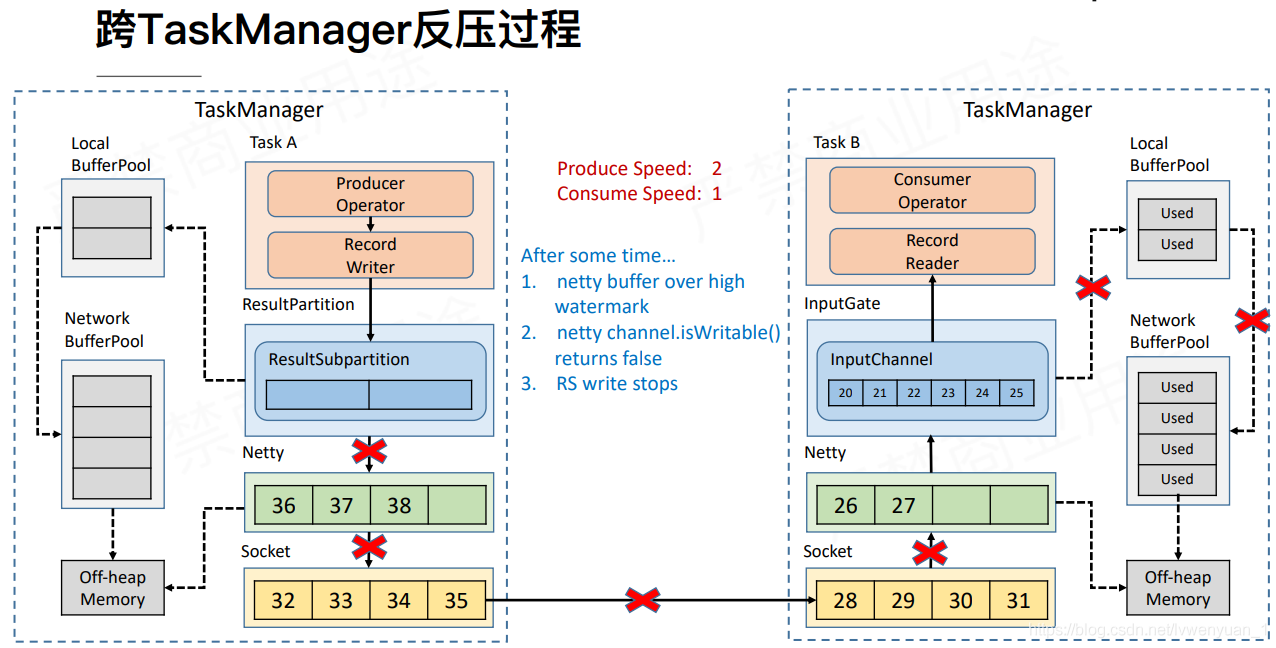
上游的RS每次往netty写入数据的时候,都会通过 netty的channel.isWritable()。来判断netty是否能被写入。当channel.isWritable()返回false的时候,就会发生阻塞。所以当RS被写满的时候,就会去向LocalBufferPool请求内存,导致LocalBufferPool会向NetworkBufferPool请求内存,如果下游处理数据的速度一直跟不上产生数据的速度,那么会最终导致,上游的NetworkBufferPool的可用内存被申请完,产生堵塞。
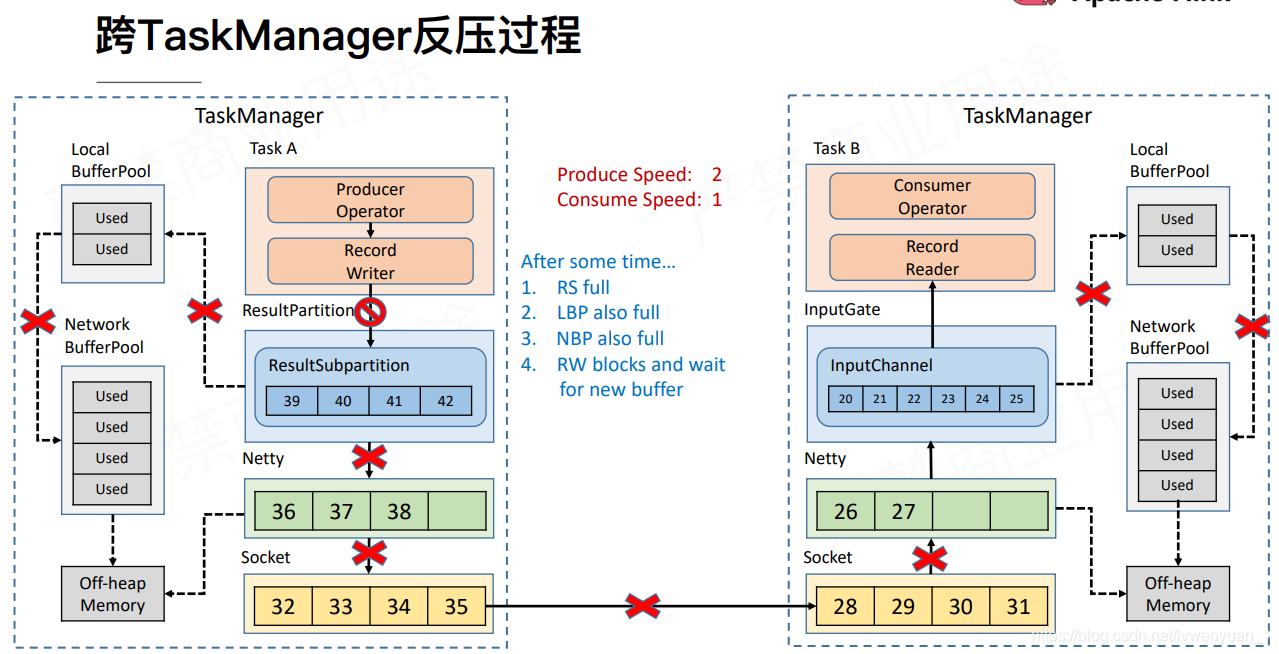
以上是跨TaskManager的反压过程,下面是TaskManager内部的反压过程,也就是RS到IG。其实和上面的类似。
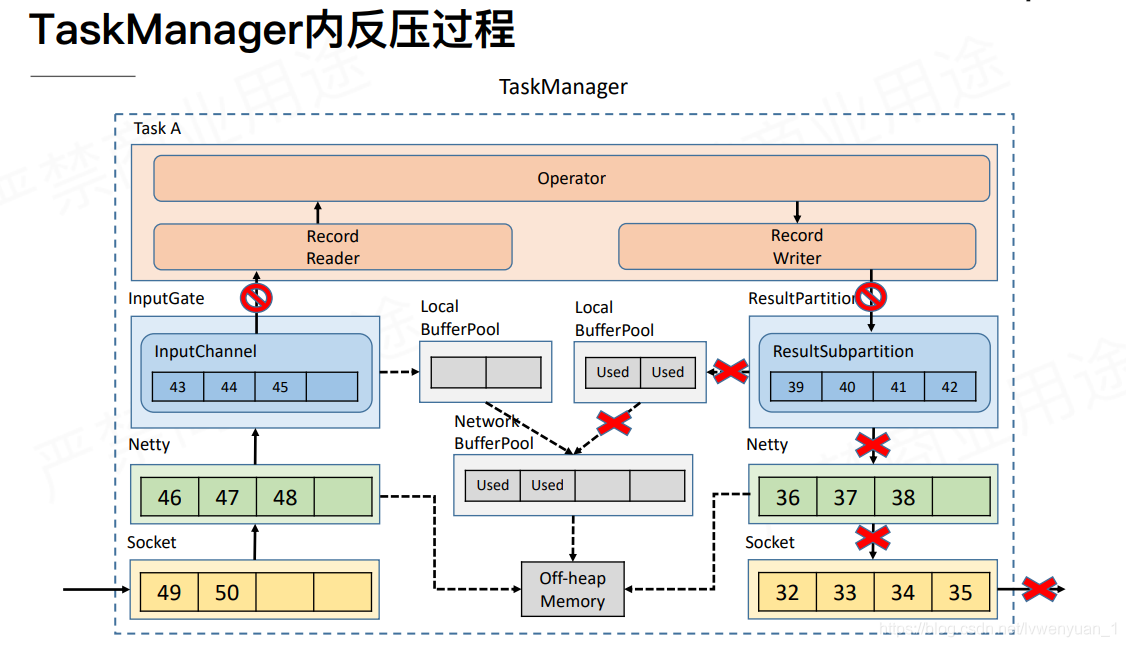
当RS写入被堵塞的时候,由于RecordWriter和RecordReader是在同一个线程内,这个是RecordReader也被堵塞了。这个是就会重复上面的堵塞过程,导致IG也无法使用了。
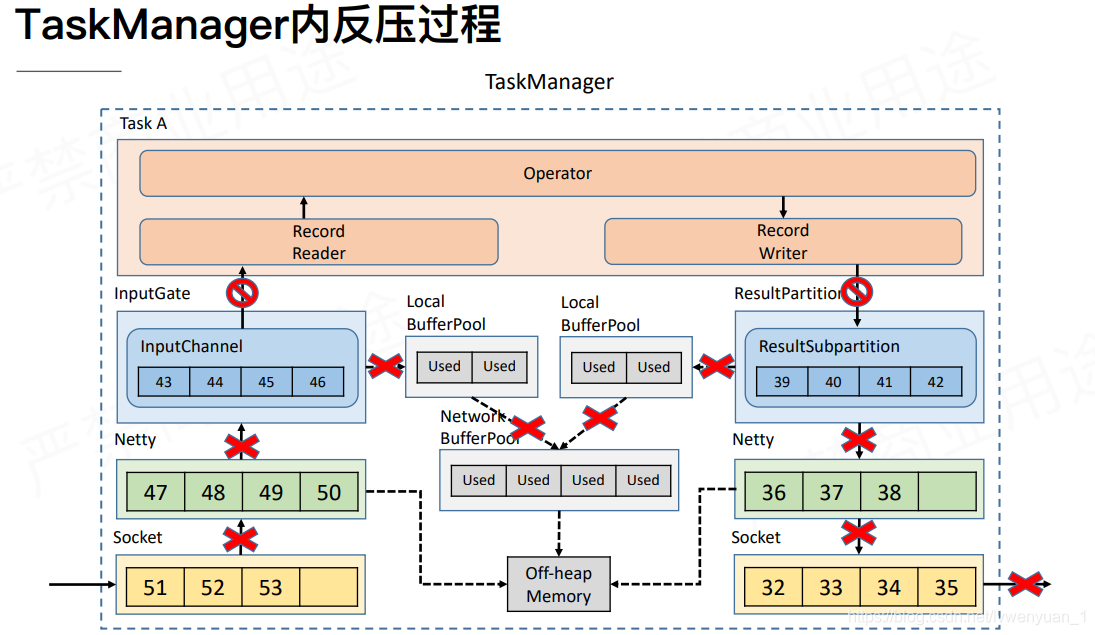
这就是 1.5版本以前的反压机制。
在1.5版本以后
引进了credit这种反压机制。先来说下TCP这种方式的弊端:
1.因为TM中会有多个Task运行,所以单个Task的反压会阻断整个TM的socket,而其他的task却无法向下游发送数据,连checkpoint的barrier也无法发出。
2.反压传播路径长,导致生效延迟比较大。
credit的反压是类似于TCP的反压,但它是在Flink层面上的。可以看下图:
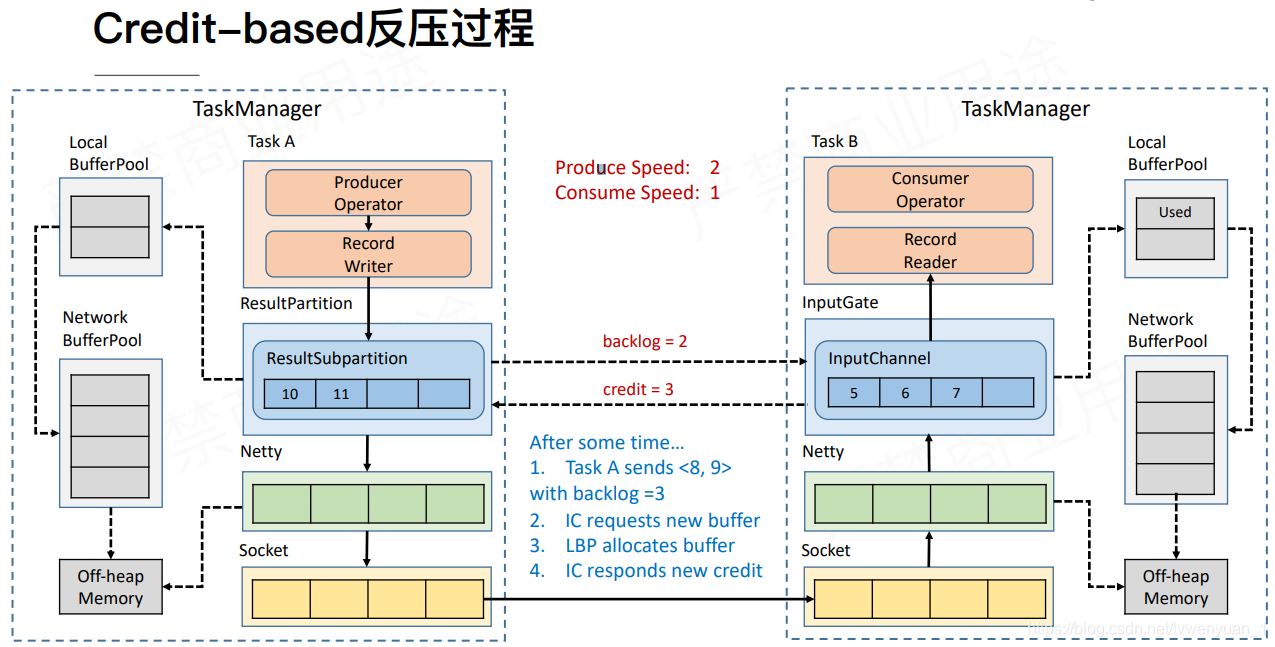
RS会向IG发送这个要发送的量,IG返回当前空余量,包含LocalBufferPool的。如果这个时候发现backlog > credit,那么LocalBufferPool就会向NetWorkPool申请内存。
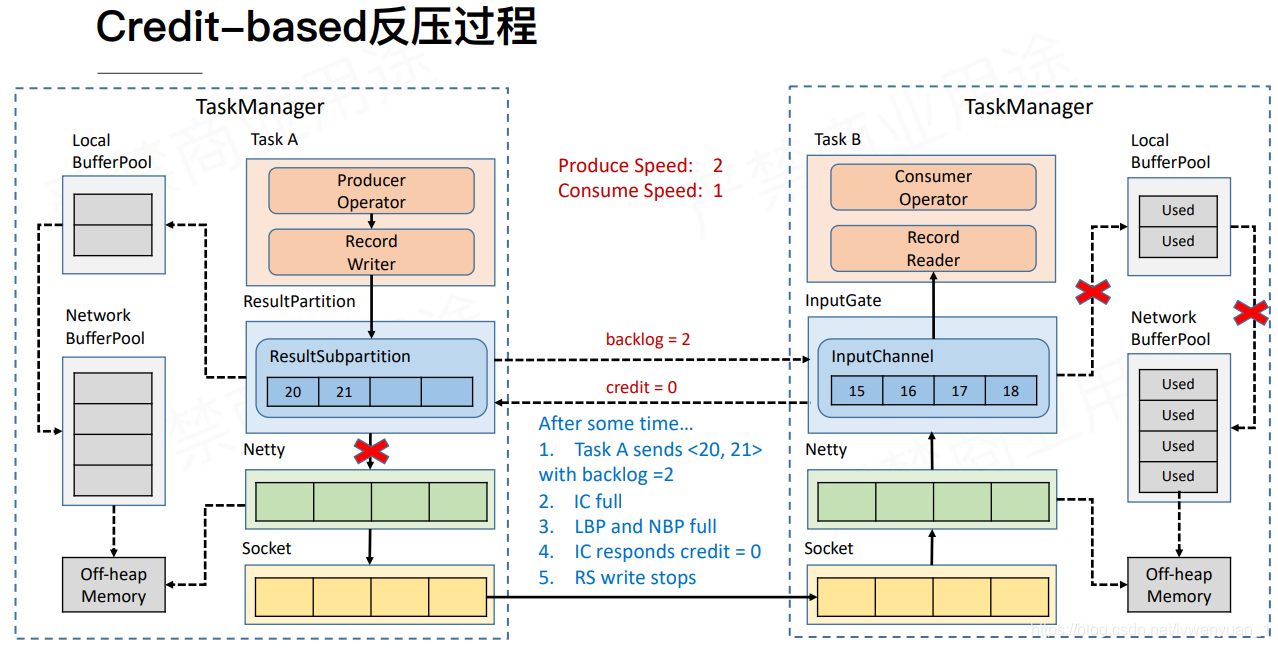
长此以往,当credit返回0的时候,表示没有内存缓存了,那么RS接收到credit的时候,就不会继续往netty写数据了。这样socket就不会堵塞了,同时生效延迟也降低了。同时RP也会不断去探测IG是否有空余的空间。
问题:
有了动态反压,那么静态反压是不是就没有用了?
答案当然不是,这个很大程度上取决于sink端数据存储在哪里。譬如说,数据最终落地在es中,那么由于前面数据量过大,es端直接报错,整个任务就停止了,这个时候动态反压就没有了,那么静态的限制consumer的量就很关键了,但是这个设置是在1.8版本里才有。
Flink页面上监控反压的数据来源
在源码包中,有个md文件,对获取back pressure的ratio值做了解释。
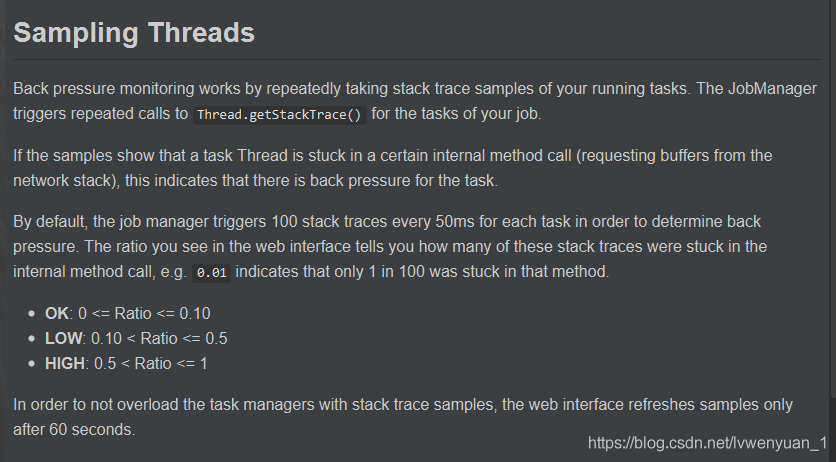
默认情况下,每50ms发送 100此探测,通过调用Thrad.getStackTrace()方法来探测,从网络堆栈请求缓存区。如果有的任务比较紧张,那么有的请求就会卡主,以此来监控任务是否存在反压。中期,0.01表示100次中有1次探测卡主了。