目录
Deep Fakes
简介
深度伪造
——
使用深度学习在视频中将一个人的脸换成另一个人的脸
——
是当今使用人工智能的最有趣
和
最可怕的方式之一。
虽然深度伪造可用于合法目的,但它们也可用于虚假信息。能够轻松地将某人的脸换成任何视频,我们真的可以相信我们的眼睛告诉我们的吗?政治家或演员做或说令人震惊的事情的真实视频可能根本不是真实的。
在本系列文章中,我们将展示深度伪造的工作原理,并展示如何从头开始实现它们。然后我们将看看
DeepFaceLab
,它是一种多合一的
Tensorflow
驱动的工具,通常用于创建令人信服的深度伪造。
了解如何创建
DIY
深度伪造模型、如何在云中的容器上训练它们,以及如何使用
DeepFaceLab
作为您自己模型的替代方案。
深度伪造是现代人工智能最令人惊叹的应用之一。在视频中完成
——
并且可信地
——
用另一个人的脸替换一个人的脸的能力是人工智能可以做的事情的发自内心的证明。
到目前为止,大多数关于深度伪造的讨论都是负面的。想象一个政治家或演员做或说一些根本不真实的事情的真实视频
——
这是病毒式和潜在危险的假新闻的理想场景。这就是深度假货获得主流意识的原因。
幸运的是,并非所有深度伪造应用程序都是糟糕的。
Deep fakes
可用作电影制作的
CGI
的替代品,以减少闪回场景中演员的年龄,或将现已去世的演员添加到新电影中。想想莫夫
·
塔金如何在《侠盗一号》中扮演重要角色,即使在原版星球大战电影中扮演他的演员于
1994
年去世,或者卢克
·
天行者如何在曼达洛人中看起来更年轻,尽管演员的真实年龄不是这样。当电影被翻译成不同的语言时,深度伪造技术甚至可以纠正演员的嘴巴动作。
这些任务历来非常昂贵。通常需要一个
CGI
团队和几个月的时间来实现它。现在,借助人工智能和一些
Cloud AIOps
专业知识,您可以以更低的成本取得出色的成果。
本系列迷你文章将向您展示构建深度伪造模型并实现它们的基础,这样您就可以获得好看的视频,而无需在
CGI
专家团队上花费几百万美元。
要充分利用本系列,您需要具备
Python
、深度学习和计算机视觉的基本知识。如果你不是专家也没关系。在整个系列中,我将尝试解释我们所涵盖的概念并提供链接,您可以在其中找到更多信息。随着我们的前进,我将堆叠概念层,以便您熟悉我们讨论的术语。
了解深度伪造背后的概念
尽管创建深度伪造听起来像交换面孔很容易,但并非如此简单。有几个关键且复杂的步骤并不那么明显。此外,深度伪造还有很多种:让一个人去衰老,让某人说些新话,以及将某人的脸插在别人的头上等等。
我们将分解所有这些想法并了解它们的共同点,但让我们首先正确定义什么是深度伪造。你可能已经猜到了,
“deep fake”
是
“
deep learning
”
和
“fake”
这两个词的组合,它使用人工智能来制作伪造的视频,而且不仅限于换脸。例如,它可用于将视频中的马转换为斑马。
本系列文章将为您提供几个代码示例。我的
GitHub
存储库
中的这些文章系列中使用的笔记本和文件以及所有完全交互式的
Kaggle
和
Colab
笔记本:
你可以在这里找到训练好的模型:
Deep Fakes
一般概述
通常,您至少需要两个视频来创建深度伪造:其中一个是
源视频
,另一个是
目标视频
(在某些情况下,您可能希望只使用一个包含多个用户的视频并交换他们的面孔,但这超出了本文的范围)。以换脸为例,第一个视频将包含您想要从中获取一些面部手势的个人,第二个视频将包含您想要使用的实际面部外观。
我们需要提取构成每个视频帧的所有图像,这一过程称为
帧提取。
这个过程的目的是从这些图像中提取人脸(人
脸提取
)来训练深度假模型(是的,两个模型。我稍后会解释原因)。一旦我们已经提取了所有人脸,我们将使用该人脸集(人脸数据集)进行
模型训练。
然后我们将它们与我们的框架和面部集一起使用来执行
面部交换
,即将生成的面部插入原始框架中。最后,我们需要
合并帧
以制作视频并获得深度伪造。
下一个图表描述了使用自动
编码器
作为深度伪造生成器的这个过程(我将在本文后面更深入地讨论),这就是我们将遵循的方法。如果您还不知道所有元素是什么,请不要担心。我将解释您需要了解它们的功能以及如何对其进行编码所需的详细信息,并指出我们处于哪个步骤:
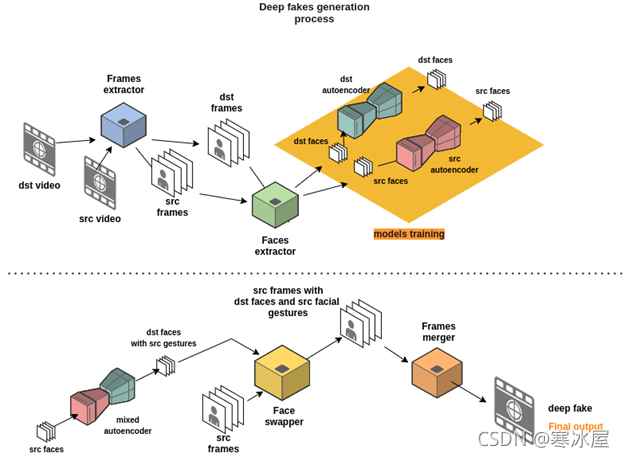
在第一个图表(顶部的图表)中,您会注意到帧提取器提供了原始视频。这些包含我们要交换的面孔。接下来,它将这些视频的帧传送到人脸提取器,后者会将每一帧作为常规图像进行处理,并提取其中遇到的人脸。这是我们获得实际人脸集的地方,我们将把这些人脸集输入到我们的模型中进行训练。为简单起见,我们将在目标
faceset
上训练这些模型之一,在源
faceset
上训练另一个。
训练结束后,我们将
“
源
”
模型的输入块与
“
目标
”
模型的输出块混合,并为它们提供
“
源
”
人脸,最终获得具有
“
源
”
面部手势的
“
目标
”
人脸。
在上图中的第二个图表中,人脸交换器使用混合模型的输出将那些新生成的人脸插入到相应视频帧中的原始人脸上。最后,帧合并重新组合这些帧以获得我们的深度假视频。请记住,根据您想要实现的目标,您可以稍微不同地进行设置。例如,您可以只交换面部的一部分、整个面部或整个头部。
在
接下来的文章
中,我将解释我们可以选择不同的选项来创建深伪造。
https://www.codeproject.com/Articles/5297467/Video-Face-Transfer-with-Deep-Fakes