文章目录
一、常用正则表达式的语法
\d 数字
\w 数字或者字母
. 可以匹配任意字符
星号* 表示任意个字符
+ 表示至少一个字符
? 表示0或者1个字符
{n} 表示n个字符
{n,m} 表示n-m个字符
\s 表示空白符
括号[] 表示范围,比如:[0-9a-zA-Z\_] 可以匹配一个数字、字母或者下划线
^ 表示行的开头, ^\d表示必须以数字开头。
$ 表示行的结束, \d$表示必须以数字结束。
A|B 可以匹配A或B,如 (P|p)ython可以匹配 'Python'或者 'python'
() 表示的就是要提取的分组(Group),如
m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
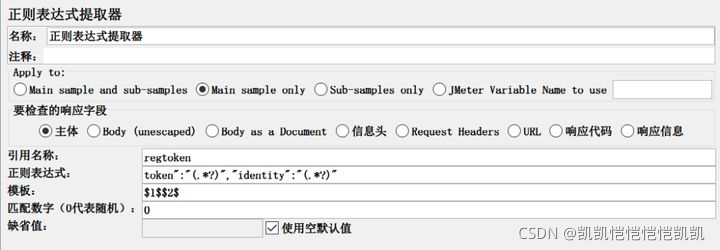
引用名称由自己命名且不能重复,()里面即我们提取的值,正则表达式根据实际需要填写
模板表示取第几个值:
$-1$表示取所有值;
$0$表示随机取值;
$1$表示取第一个值
$2$表示取第二个值。
匹配数字: 0表示随机取值, 1代表全部取值
缺省值:如果正则表达式取不到值,则使用此缺省值
方法一:
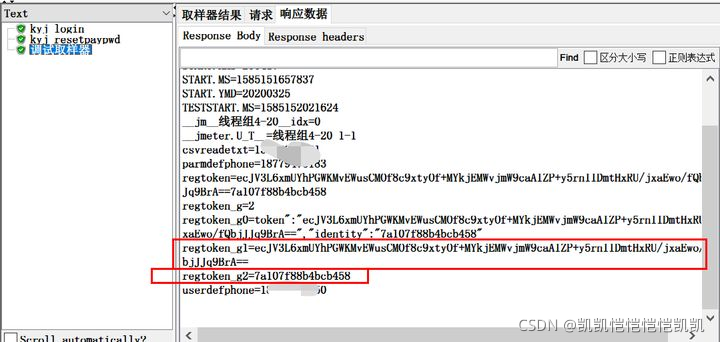
可以在一个正则提取器中,同时提取多个值,多个值时,模板之间不用分隔符号,用一个变量接收,然后在关联使用时,使用变量名称_g1、变量名称_g2… 依次类推,就可以了

方法二:
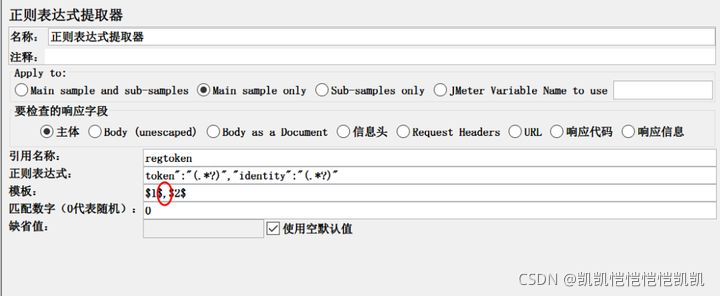
既然用一个变量接收,他会接收全部的提取值,那我就把值拆开。用一个定义的标点符号,拆开成多个值。
写多个正则表达式,用1个变量接收,模板之间用 逗号 分隔
用一个 split函数,进行拆分,放入新的变量中
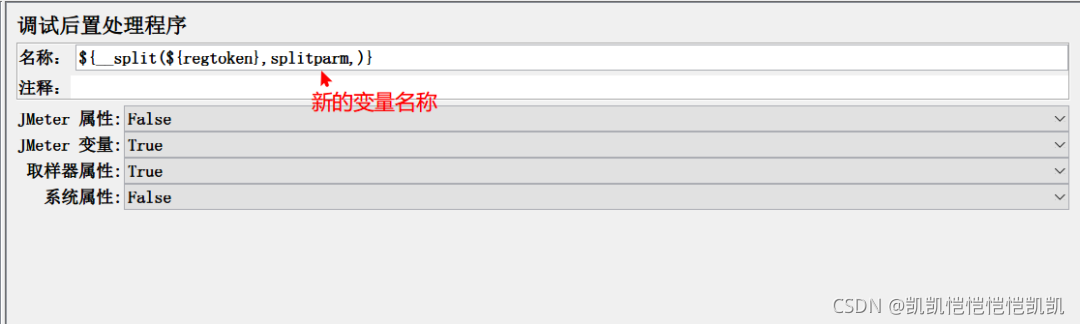
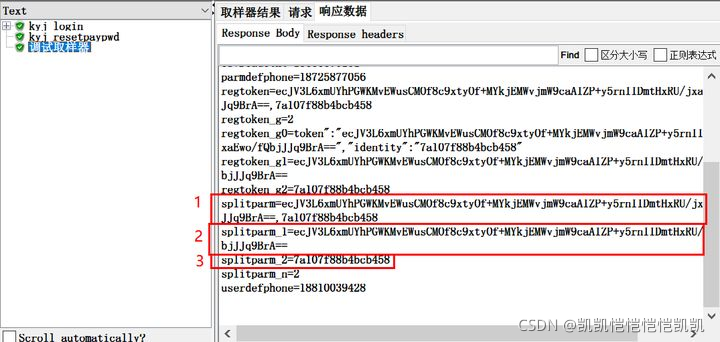
从调试取样器中,可以看到拆分之后的结果
使用新的变量名称,注意,使用第一个变量,则用 新变量名称_1
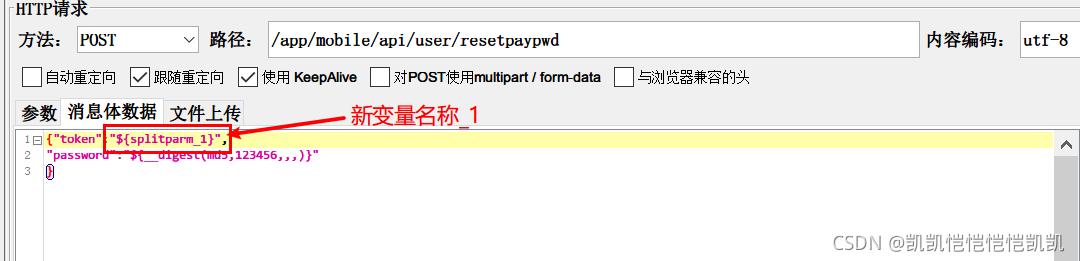
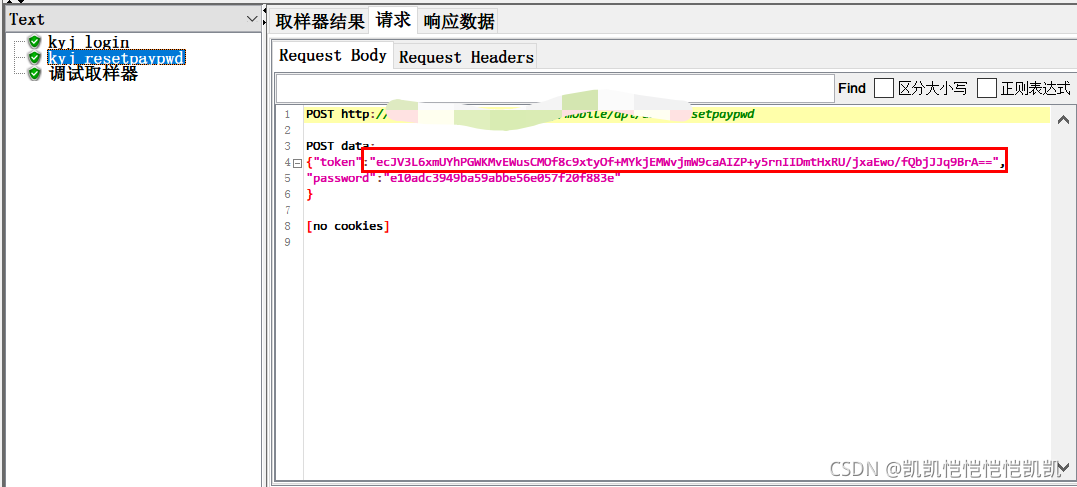
最后,请求,在查看结果树中,看到请求的结果,已经使用拆分后的值了。

版权声明:本文为weixin_42832313原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。