一、storm理解
下面以水厂加工的例子进行讲解。

人们要想喝到自来水。
1、是不是需要水泵在水源地进行抽水
2、将抽到的水放到蓄水池里作进一步的处理。第一个蓄水池的实现的功能就是做沉淀。第二个蓄水池的功能就是过滤。第三个蓄水池的功能就是消毒。之后产生蓄水。
3、要想上面的过程完美的进行,是不是需要一个中控室,来告诉这些水泵和蓄水池应该干什么,来进行调度。
实际上storm的框架与生产自来水及其相似。下面我们做一个对应的关系。
storm框架主要分为主从节点,主节点为nimbus,从节点为supervisor。
那么中控室就相当于nimbus,水泵与蓄水池就相当于supervisor。
那么问题又来了,nimbus如何通知并给这些supervisor发布任务的呢?
从这个图可以得知,nimbus是通过一个中间人进行通知这些supervisor,中间人我们使用的zookeeper,我们暂时可以把zookeeper理解为一个“数据库”,在这个“数据库”上面可以进行发布任务。而supervisor又如何能获得这些任务?是通过心跳的方式进行检测是否连接,以及拿到任务。
再回到上图中。
我们把水源地可以看做数据源,那么水泵是不是可以认为是采集数据,沉淀、过滤、消毒是不是可以认为数据处理。这些是不是都可以看做一个一个的任务。
而在storm又是如何实现这些过程?
storm分为两大任务类型:1、spout:数据采集2、bolt:数据处理,可以进行组联
那么我们是不是建立蓄水池(supervisor),让蓄水池实现一些功能(spout或bolt)。
二、流式计算架构

根据上图网站进行举例:
1、我们采集网站的实时数据或日志,我们使用的框架为Flume
2、数据采集过来之后,我们会进一步做一个缓存,我们一般使用kafka(是一个消息的系统,它支持广播)。
3、我们需要对数据进行实时分析和计算处理,我们实时计算的引擎有:
storm
spark streaming
jstorm(阿里)
flink
4、计算的结果要保存到一个地方,一般我们保存到Redis中
三、storm系统的搭建
在安装storm之前Python版本必须大于2.6,因此必须先安装Python:https://blog.csdn.net/qq_45335413/article/details/106959102
(1)伪分布
1、解压 sudo tar -zxvf Storm包名
解压之后,一定要设置文件的权限,例如:
sudo chmod 777 apache-storm-2.1.0
2、设置环境变量
STORM_HOME=/usr/local/apache-storm/apache-storm-1.0.3
export STORM_HOME
PATH=$STORM_HOME/bin:$PATH
export PATH
使上面环境变量生效:
source ~/.bash_profile
验证环境变量是否配置成功:
storm

3、配置核心文件 :conf/storm.yaml
#zookeeper服务器地址
storm.zookeeper.servers:
- "192.168.92.130"
# - "server2"
# nimbus是从以下几个服务器中选出,注意,是个数组
nimbus.seeds: ["192.168.92.130"]
#每个从节点的slot的个数,配置每个supervisor上有4个(cup的核数一样)
supervisor.slots.ports:
- 6700
- 6701
- 6702
#配置任务上传后的目录,上传任务的jar包就放在nimbus的这个目录下面
storm.local.dir: "/usr/local/apache-storm/apache-storm-1.0.3/tmp"
#建议再配置一个参数
#一个topology(任务job)分配一个Event Logger(日志收集器),能够
#查看任务中的处理的数据
"topology.eventlogger.executors": 1
4、启动storm
- 在nimbus.host所属的及其上启动nimbus服务和logviewer
storm nimbus &
storm logviewer &
- 在nimbus.host所属的机器上启动ui服务
storm ui &
- 在其它个点击上启动supervisor服务和logviewer服务
storm supervisor &
storm logviewer &
- Storm 的常用命令
1、提交任务
storm jar apache-storm.jar demo.WordCountToplogy MyWordCount
2、停止storm
storm kill topology-name
- 查看storm集群:访问nimbus的Ip地址:8080,即可看到storm的ui界面
问题:
遇到问题首先学会看日志,问题记录的很详细!
Could not find leader nimbus from seed hosts [ubuntu].
Did you specify a valid list of nimbus hosts for config nimbus.seeds?
Exit 254 storm nimbus
所有的都启动之后,报这个错,是因为Unable to create directory /usr/local/apache-storm/apache-storm-2.1.0/temp/nimbus
因此,我们可以修改权限
sudo chmod 777 temp
#####################################################
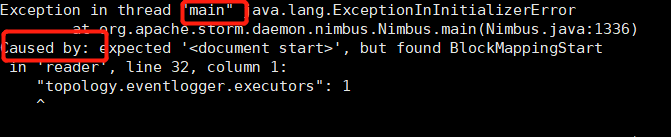
storm.yaml文件配置格式出现错误
(2)全分布
主节点nimbus:bigdata112、ui、LogViewer
从节点supervisor:bigdata113、bigdata114
解压、设置环境变量
storm.zookeeper.servers:
- "bigdata112"
- "bigdata113"
- "bigdata114"
nimbus.seeds: ["bigdata112"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
storm.local.dir: "/usr/local/apache-storm/apache-storm-2.1.0/tmp"
"topology.eventlogger.executors": 1
复制到其他节点
scp -r apache-storm-1.0.3/ root@bigdata113:/usr/local
scp -r apache-storm-1.0.3/ root@bigdata114:/usr/local
(3)HA
只需要修改每个节点上的
nimbus.seeds: ["bigdata112", "bigdata113"]
四、storm总体架构

当客户端通过<storm jar jar包 启动类 任务名称 >这条命令,就会把我们自己写好的任务上传到Nimbus上面,也会生成序列化的文件,并且上传到ZK集群上面,这时nimbus首先将会做两件事情:
- 从zk集群上面获取空闲的worker。
- 进行任务的分配。
进行任务分配时,nimbus会根据自身的算法,生成一张表,记录每个机器上面所要启动的worker,以及所要执行的任务。之后,nimbus会把这个表上传到zk集群。
这时,supervisor会通过心跳的方式定时取查看有没有与自己相关的任务,如果有,将会把与自己相关的任务拿到自己本地上面,并删除本地已经停止的任务数据。之后,supervisor会启动对应任务中worker,并执行相应的任务。在启动worker之前,supervisor会把对应执行的任务的代码,从zk集群上面下载过来,并执行。
五、单词计数的编程模型

两个组件:
spout:采集数据
bolt:处理采集得到的数据
从上图可以看到,WordCountSpout组件负责从外部采集数据,得到的数据传送给WordCountSplitBolt组件。首先我们要明白一个问题,组件之间是通过什么进行数据传递的?从图中可以看到,组件之间的数据传递是通过Tuple,那么Tuple是什么呢?我们可以理解为就是一个列数据,当然我们要声明一个列明。
上图的节点架构如下:

数据分发一共有三种方式:
- 随机:数据随机分发到下一层
- 按字段:相同字段分到同一个Bolt上
- 广播:数据分发到每个Bolt上
其中按按字段进行分发数据,是通过hashcode%num 进行实现。
通过分析:
splitWord只是进行单词的分割,那么第一次组件之间数据是不是可以选择随机分组就行。
而WordCount是进行每个单词计数,统计相同的单词的个数,是不是选择按字段进行分组更加的合理。
Java代码实现
- prepare 方法在worker初始化task的时候调用.
- execute 方法在每次有tuple进来的时候被调用
- declearOutputFields 方法仅在有新的topology提交到服务器, 用来决定输出内容流的格式(相当于定义spout/bolt之间传输stream的name:value格式), 在topology执行的过程中并不会被调用.
1、把$STORM_HOME/lib下面的jar包添加到我们的工程下面
2、创建WordCountToplogy,
一定设置work的数量
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* @author
* @date 2020/10/13-${TIEM}
*/
//主函数
public class WordCountToplogy {
public static void main(String[] args) throws Exception {
// 创建任务
TopologyBuilder builder = new TopologyBuilder();
//指定第一级组件:Spout任务
builder.setSpout("myspout", new WordCountSpout());
//指定第二级组件:拆分单词bolt
builder.setBolt("mysplit", new WordCountSplitBolt()).shuffleGrouping("myspout");
//指定第三级组件:单词计数bolt
builder.setBolt("mytotal", new WordCountTotalBolt()).fieldsGrouping("mysplit", new Fields("word"));
//创建任务,并运行
StormTopology job = builder.createTopology();
//有两种运行模式
// 1、本地模式
//LocalCluster cluster = new LocalCluster();
//cluster.submitTopology("MyDemo", new Config(), job);
// 2、集群模式
Config config = new Config();
config.setNumWorkers(16);
StormSubmitter.submitTopology(args[0], new Config(), job);
}
}
3、创建WordCountSpout
import java.util.Map;
import java.util.Random;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
/**
* @author
* @date 2020/10/13-${TIEM}
*/
//第一级组件:Spout用于采集数据
//做数据源使用,模拟产生一些数据
public class WordCountSpout extends BaseRichSpout {
//保存该组件的输出流
private SpoutOutputCollector collector;
//定义数据源
private String[] datas = {"I love Beijing","I love China","Beijing is the capital of China"};
@Override
public void nextTuple() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Random random = new Random();
int i = random.nextInt(3);
String data = datas[i];
System.out.println("采集到数据:"+ data);
//采集数据,并发送给下一个组件
collector.emit(new Values(data));
}
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//申明:该组件输出的Tuple的格式(tuple的表结构)
declarer.declare(new Fields("sentence"));
}
}
4、创建WordCountSplitBolt
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* @author
* @date 2020/10/13-${TIEM}
*/
public class WordCountSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
//execute 方法在每次有tuple进来的时候被调用
//获取前面组件传输的数据
String data = tuple.getStringByField("sentence");
//进行分词
String[] word = data.split(" ");
for (int i = 0; i < word.length; i++) {
collector.emit(new Values(word[i] , 1));
}
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//声明传输的tuple字段
declarer.declare(new Fields("word","count"));
}
}
5、创建WordCountTotalBolt
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* @author
* @date 2020/10/13-${TIEM}
*/
public class WordCountTotalBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Integer> map = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
int count = tuple.getIntegerByField("count");
if (map.containsKey(word)){
int total = map.get(word)+1;
map.put(word , total);
}else {
map.put(word , count);
}
//打印map
System.out.println("处理结果:"+map);
collector.emit(new Values(word , map.get(word)));
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word" , "count"));
}
}
Acked实现
改造spout组件,只需要重写ack 和 fail 方法即可。
public class WordCountSpout extends BaseRichSpout {
//保存该组件的输出流
private SpoutOutputCollector collector;
//定义数据源
private String[] datas = {"I love Beijing love Beijing","I love China love Beijing","Beijing is capital of China"};
@Override
public void ack(Object msgId) {
System.out.println("消息处理成功了, msgId: "+msgId);// msgId表示成功的索引
super.ack(msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("fail....messageId...."+msgId);
collector.emit(new Values(datas[(int)msgId]),msgId); // msgId表示失败的索引
}
@Override
public void nextTuple() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0 ; i < 340 ; i++){
Random random = new Random();
int j = random.nextInt(3);
String data = datas[j];
//System.out.println("采集到数据:"+ data);
//采集数据,并发送给下一个组件
collector.emit(new Values(data),j);
}
}
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//申明:该组件输出的Tuple的格式(tuple的表结构)
declarer.declare(new Fields("sentence"));
}
}
改造bolt组件,假如产生新的tuple,必须将新的tuple与旧的tuple关联。然后发射ack。表示这个tuple已经处理。所有的组件blot都要加collector.ack(tuple)。
public class WordCountSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
//execute 方法在每次有tuple进来的时候被调用
//获取前面组件传输的数据
String data = tuple.getStringByField("sentence");
//进行分词
String[] word = data.split(" ");
for (int i = 0; i < word.length; i++) {
// 关联新的tuple与旧的tuple
collector.emit(tuple,new Values(word[i] , 1));
}
collector.ack(tuple);
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//声明传输的tuple字段
declarer.declare(new Fields("word","count"));
}
}
六、单词计数各个流程的解释

注意:上图是通过Map键值对进行单词计数的存储。同一台的机器是不是拉取同一个序列化对象,那每个worker对这个序列化对象进行反序列化的时候,生成的对象是不是指向本台机器的同一个内存地址,再联想上面的WordCount按字段分组,是不是每个机器上的map存储不同的Word计数,进而整合整个Word的单词计数。
通俗说,Word种类很多,我把这些单词分别存储在不同的机器上。分而治之的思想。
这一块慢慢理解。
七、组件之间的数据传递

八、集成Storm:与外部系统
(1)、集成Redis
1、首先把Redis常用的jar包添加到工程中

当然Storm的jar已经添加过了。
storm连接Redis有已经写好的接口,只需要我们自己调用就行。
2、修改main函数,WordCountTopology.java类
//第四级组件,集成Redis
builder.setBolt("wordCountRedisBolt",createRedisBolt()).shuffleGrouping("mytotal");
private static IRichBolt createRedisBolt() {
JedisPoolConfig.Builder build = new JedisPoolConfig.Builder() ;
build.setHost("192.168.92.111");
build.setPort(6379);
JedisPoolConfig config = build.build();
//redisstorebolt用于指定存入Redis中的数据格式
return new RedisStoreBolt(config, new RedisStoreMapper() {
@Override
public RedisDataTypeDescription getDataTypeDescription() {
// 指定redis中的数据类型
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,
"myresualt");
}
//tuple是指上一个字段哪一个值发送到Redis中。
@Override
public String getKeyFromTuple(ITuple tuple) {
// 将计数的总数作为value
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
// 将单词作为key
return String.valueOf(tuple.getIntegerByField("count"));
}
});
}
(2)、集成HDFS
$STORM_HOME\external\storm-hdfs\storm-hdfs-1.0.3.jar
HDFS相关的jar包
注意:由于Hadoop的版本太高,我们使用Hadoop 2.x的jar包;否则会出现错误。
//指定第四级组件:HDFSBolt
builder.setBolt("myredis", createHDFSBolt()).shuffleGrouping("mytotal");
private static IRichBolt createHDFSBolt() {
// 指定HDFS的相关信息
HdfsBolt bolt = new HdfsBolt();
//指定HDFS的NameNode
bolt.withFsUrl("hdfs://192.168.157.111:9000");
//指定HDFS的路径
bolt.withFileNameFormat(new DefaultFileNameFormat().withPath("/stormdata"));
//定义如何生成HDFS的文件
//每隔128M生成一个HDFS的文件
bolt.withRotationPolicy(new FileSizeRotationPolicy(128.0f, Units.MB));
//定义数据间的分隔符: love|2
bolt.withRecordFormat(new DelimitedRecordFormat().withFieldDelimiter("|"));
//跟HDFS进行同步
bolt.withSyncPolicy(new CountSyncPolicy(10));
return bolt;
}
(3)、集成JDBC:Oracle、MySQL
把下面jar添加到工程中
$STORM_HOME\external\sql\storm-sql-core\*.jar
$STORM_HOME\external\storm-jdbc\storm-jdbc-1.0.3.jar
mysql的驱动
commons-lang3-3.1.jar
//指定第四级组件:JDBCBolt ---> MySQL
//builder.setBolt("myhdfs", createJDBCBolt()).shuffleGrouping("mytotal");
private static IRichBolt createJDBCBolt() {
// 将处理的结果保存到MySQL中
MyConnectionProvider provider = new MyConnectionProvider();
JdbcMapper mapper = new SimpleJdbcMapper("myresult", provider);
return new JdbcInsertBolt(provider, mapper).withTableName("myresult");
}
创建MyConnectionProvider 类,注册驱动
class MyConnectionProvider implements ConnectionProvider{
private static String driver = "com.mysql.jdbc.Driver";
private static String url = "jdbc:mysql://192.168.157.111:3306/hive";
private static String user = "hiveowner";
private static String password = "Welcome_1";
//注册驱动
static {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public Connection getConnection() {
// 返回一个MySQL的连接
try {
return DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
@Override
public void prepare() {
// TODO Auto-generated method stub
}
}
(4)、集成kafka
九、Storm总体架构图
