表存储格式&数据类型
Hive表的存储格式

Hive支持的表类型,或者称为存储格式有:TextFile、SequenceFile、RCFile、ORC、Parquet、AVRO。
TextFile
其中TextFile是文本格式的表,它是Hive默认的表结构;在存储时使用行式存储,并且默认不进行压缩,所以TextFile默认是以明文的文本方式进行保存的,但可以手动开启Hive的压缩功能进行数据压缩。
但开启压缩后,压缩后的文件在处理时无法进行split,所以并发度并不高;
因为一个压缩文件在计算时,会运行一个Map任务进行处理,如果这个压缩文件较大,处理效率就会降低,但压缩文件支持再切分的话,在处理时可以Split成多个文件,从而启动多个Map任务进行并发处理,提升处理性能。
而且对TextFile压缩文件的解压,即反序列化为普通文件,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比 SequenceFile 高几十倍。
TextFile表因为采用了行式存储,所以适合字段较少或者经常需要获取全字段数据的场景,在数据仓库场景的分析计算场景中一般不会使用TextFile表;通常ETL流程导入的数据通常为文本格式,使用TextFile表可以很容易的将数据导入到Hive中来,所以它常见的适用场景是作为外部数据导入存储,或者导出到外部数据库的中转表。
SequenceFile
SequenceFile同样是行式存储的表,它的存储格式为Hadoop支持的二进制文件,比如在MapReduce中数据读入和写出所使用的<Key、Value>数据,其中Key为读取数据的行偏移量,Value为SequenceFile真正存储的数据,所以它在Hadoop中处理时,会减少文件转换所需要的时间。SequenceFile支持压缩,可以选择None、Record、Block三种压缩方式,默认为Record,压缩率最高的是Block,而且支持压缩文件再拆分。所以如果在生产中,需要数据进行行式存储、原生支持压缩,且要满足一定的性能要求,那么可以使用SequenceFile这种存储方式。
RCFile、ORC、Parquet
RCFile、ORC、Parquet这三种格式,均为列式存储表——准确来说,应该是行、列存储相结合。在存储时,首先会按照行数进行切分,切分为不同的数据块进行存储,也就是行存储;在每一个数据块中,存储时使用的又是列式存储,将表的每一列数据存放在一起。这种列式存储在大数据技术中尤为常见,它在海量数据场景中是很好的一种优化手段,可以减少数据读取、移动所花费的时间;因为在结构化数据处理中,一般不会用到全部数据,而是选择某几列进行运算,使用行式存储会将所有数据加载后再进行过滤,而列式存储可以只读取这几列数据,减少数据读取、处理所需要的时间,这在海量数据场景中可以节约非常多的时间。
列式存储表中,RCFile现在基本很少使用了,它是ORC表的前身,支持的功能和计算性能都低于ORC表。
ORC表是Hive计算的主要表形式,是在RCFile的基础上进行了优化和改进,支持NONE、Zlib、Snappy压缩,在分析计算中的性能较好,是生产中常见的表类型。而且ORC表可以开启事务功能,以便支持数据更新、删除等操作,但事务的开启会影响表的处理性能,所以非必要情况下不需要启用事务功能。但ORC表的问题在于,它是Hive特有的存储类型,所以在其它大数据产品中兼容性并不好,有些只有在较高的版本中才会支持。
Parquet表也是Hive计算的主要表形式,它的计算性能稍弱于ORC表,但因为Parquet文件是Hadoop通用的存储格式,所以对于其它大数据组件而言,具有非常好的数据兼容度;而且Parquet表可以支持数据的多重嵌套(如JSON的属性值可以是一个对象,且支持嵌套),但ORC表在多重嵌套上的性能并不好。Parquet支持uncompressed\snappy\gzip\lzo压缩,其中lzo压缩方式压缩的文件支持切片,意味着在单个文件较大的场景中,处理的并发度会更高;而ORC表的压缩方式不支持切分,如果单个压缩文件较大的话,性能会有影响。
所以,对于ORC表和Parquet表的选择要区分使用场景,如果只在Hive中处理时使用,追求更高效的处理性能,且单个文件不是很大,或者需要有事务的支持,则选用ORC表。但如果要考虑到与其它大数据产品的兼容度,且单个文件较为庞大,数据存在多重嵌套,则选用Parquet表。
AVRO
最后AVRO表,它主要为 Hadoop 提供数据序列化和数据交换服务,支持二进制序列化方式,它与Thrift功能类似。一般而言,在数据传输中,不会直接将文本发送出去,而是先要经过序列化,然后再进行网络传输,AVRO就是Hadoop中通用的序列化和数据交换标准。所以,如果数据通过其他Hadoop组件使用AVRO方式传输而来,或者Hive中的数据需要便捷的传输到其他组件中,使用AVRO表是一种不错的选择。
常见表类型选择
Hive在生产中,一般使用较多的是TextFile、Orc、Parquet。TextFile一般作为数据导入、导出时的中转表。ORC和Parquet表一般作为分析运算的主要表类型,如果需要支持事务,则使用ORC,如果希望与其它组件兼容性更好,则使用Parquet。
在性能上ORC要略好于Parquet。但Parquet支持压缩切分,有时候也是考虑因素。
当然除了这几种内置表,Hive还支持自定义存储格式。可通过实现 InputFormat 和 OutputFormat 来完成。
压缩方式
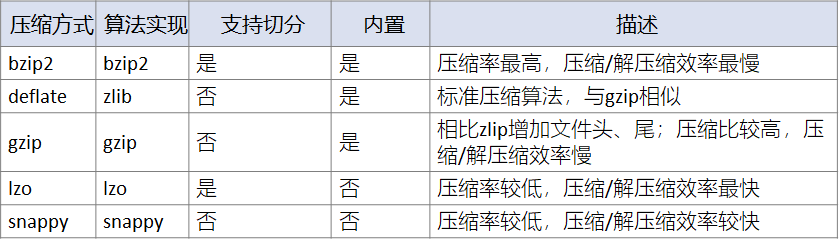
Hive内置的压缩方式有bzip2、deflate、gzip,支持的第三方压缩方式有lzo、snappy。标准压缩方式为deflate,其算法实现是zlib。
其中bzip2、lzo支持压缩后文件再拆分。
对于这几种压缩算法,按照压缩比的排名顺序为:bzip2 > gzip > deflate > snappy > lzo。所以如果想保证高压缩率,那可以选用bzip2、gzip,但相应的压缩/解压缩的时间也会很长。相反的,按照压缩/解压缩耗时排名,顺序正好相反:lzo < snappy < deflate < gzip < bzip2,所以如果追求处理效率,则可以使用lzo、snappy进行压缩。
这里对压缩方式,仅做简单的了解即可。
数据类型
基本数据类型
数值型
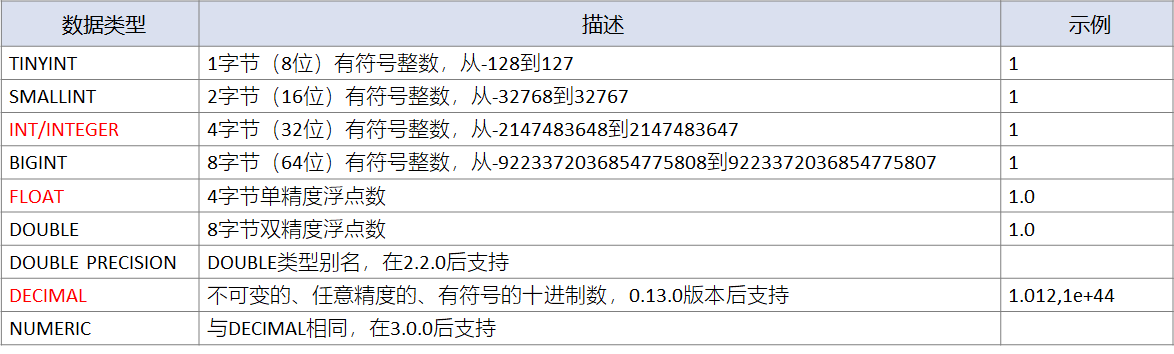
Hive数值型包含整数、浮点数两种。
整数类型有:tinyint、smallint、int/integer、bigint,默认为int/integer,或者使用后缀进行整数类型的标识:100Y、100S、100L(对应为 tinyint、smallint、bigint)。
浮点类型有:float、double/double precision、decimal/numeric,金融级别数据会使用decimal保证数据精度。
decimal数据类型
使用构造函数decimal (precision, scale)进行创建,precision是数字部分(整数+小数)的整体长度, scale是小数部分的长度。如果不进行指定,数字部分默认长度为 10,小数部分如果没有指定,则默认为 0。
一般数据类型在建表时,在表字段后指定;但为了方便演示,使用了CAST函数进行了数据类型转换,将其它类型数据转换为DECIMAL类型。执行SQL前,先保证HiveServer2和MetaStore已经启动,并使用beeline客户端连接到hive。
--将float类型的123.5转换为decimal类型
select CAST(123.56 AS DECIMAL(4,1));
> 123.5
小数部分超出指定长度后,会被四舍五入截取,相当于精度截取。
select CAST(123456.5 AS DECIMAL);
> 123457
整数部分超出指定长度后,直接转换为NULL值,相当于数据溢出。
select CAST(12345678910.5 AS DECIMAL);
> NULL
可以将其它数据类型转换为decimal,数据超出部分按照规则进行截取。
select CAST('123456789.1234567' AS DECIMAL(20,5));
123456789.12346
字符型
Hive字符型包含可变长度字符串、固定长度字符串两种。可变长度字符串有:string、varchar;固定长度字符串有:char。

其中varchar需要指定最大字符数(1-65535),超过则会被自动截断,而string会自动进行扩展;但varchar和string,末尾如果存在空格,则会影响字符串的比较结果。
select CAST("ABCDEFGHIGK" AS VARCHAR(10));
> ABCDEFGHIG
select CAST("ABCDEFGHIGK" AS STRING);
> ABCDEFGHIGK
char需要指定最大字符串(1-255),小于指定长度的值会被空格填充,末尾存在空格,并不影响字符串的比较结果。
select CAST("ABCDEFGHIGK" AS CHAR(10));
> ABCDEFGHIG
日期型
Hive支持的日期类型有:TIMESTAMP、DATE、INTERVAL。

TIMESTAMP
可以存储整型、浮点型、字符串类型的时间数据。
整型、浮点型支持以毫秒为单位的UNIX时间戳。
select CAST(1610493629000 AS TIMESTAMP);
> 2021-01-13 07:20:29.0
字符串,支持YYYY-MM-DD HH:MM:SS.fffffffff 格式,可达到小数点后9位精度(纳秒级别)。
select CAST('2021-01-13 07:20:29' AS TIMESTAMP);
> 2021-01-13 07:20:29.0
对于TIMESTAMP,提供用于时区转换的UDF函数:to_utc_timestamp,from_utc_timestamp。
select to_utc_timestamp(1610493629000, 'GMT');
> 2021-01-13 07:20:29.0
所有日期时间的UDF都能够使用TIMESTAMP数据类型。
Date
类型在0.12.0后支持,格式为YYYY-MM-DD,可以表示从0000-01-01到9999-12-31的日期。Date只能从Date、Timestamp、String类型中转换而来。
select cast(CAST('2021-01-13 07:20:29' AS TIMESTAMP) as date);
select cast('2021-01-13' as date);
select cast(cast('2021-01-13' as date) as date);
Intervals
是指一段以年、月、日、分钟、秒为单位的时间片段。

在2.2.0版本之前,仅支持字符串表示时间片段,但2.2.0后可以使用数字常量直接表示,或者直接省略INTERVAL关键字,使用别名进行表示。如INTERVAL ‘1’ DAY等同于INTERVAL 1 DAY,也可以使用1 DAYS进行表示。
Intervals一般用于时间的计算。
# 在当前时间的基础上,增加1年、2个月、1天
# 2.2.0之前
select current_timestamp() + INTERVAL '1' year + INTERVAL '2' MONTH + INTERVAL '1' DAY;
# 2.2.0之后
select current_timestamp() + INTERVAL 1 year + INTERVAL 2 MONTH + INTERVAL 1 DAY;
select current_timestamp() + 1 years + 2 months + 1 days;
Intervals支持格式化字符串,用于表示组合的时间片段,但支持有限。
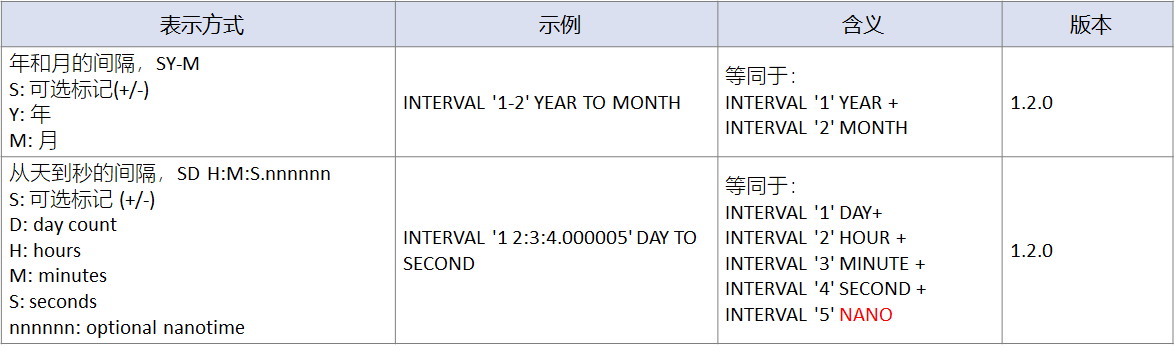
--表示1年2个月
select INTERVAL '1-2' YEAR TO MONTH;
--表示1天2小时3分钟4秒5纳秒
select INTERVAL '1 2:3:4.000005' DAY TO SECOND;
Intervals仅支持年、月进行组合,天、小时、分钟、秒、纳秒进行组合,不支持类似月、天这样的组合,但因为组合的时间片段使用场景非常有限,一般在时间计算中会直接对多个INTERVAL片段进行运算,所以不影响实际使用。
Intervals在2.2.0版本中,支持动态时间间隔、关键字省略,方便了在特定场景中的使用。

select INTERVAL (1+2) MONTH;
select 1 DAY;
其它类型(Misc Type)
在基本数据类型中,还有BOOLEAN、BINARY。

当然,对于缺失的数据值,会被标记为NULL。
复杂数据类型
Hive支持复杂数据类型array、map、struct、union。

数据类型比较
对于这些数据类型,仅需要在使用时进行参考即可。但Hive作为数据仓库,数据更多的时候是从其它数据库或数据仓库中导入的,所以就需要进行数据类型的转换。
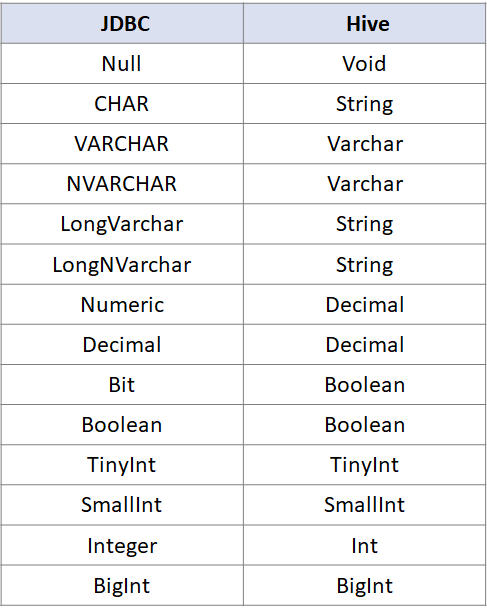
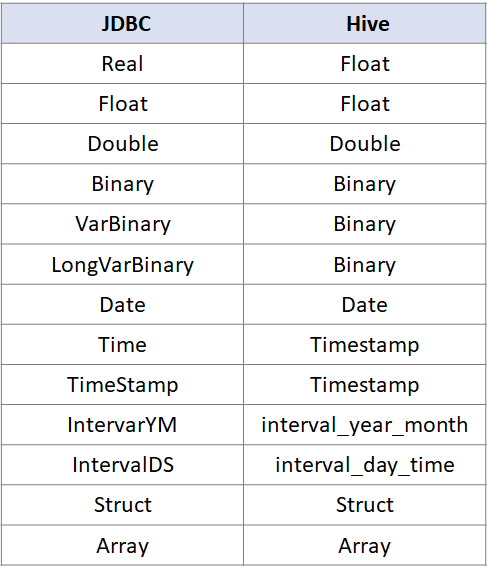
其中
JDBC与Hive数据类型的对照关系
如下图所示:
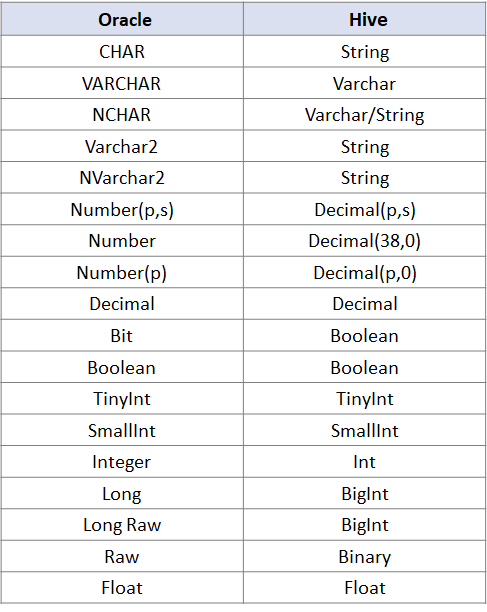
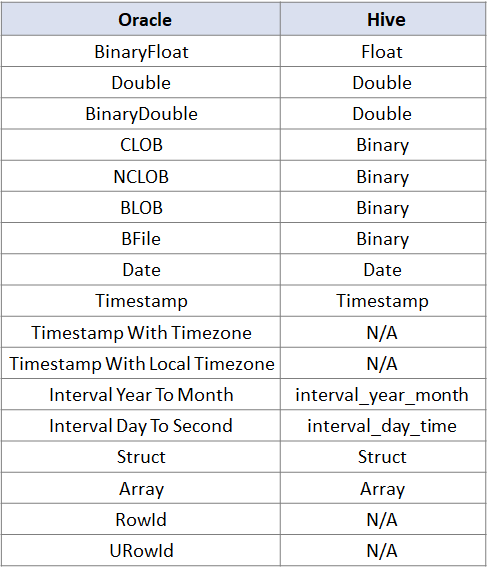
接下来是
Orcale与Hive的数据类型对照
:
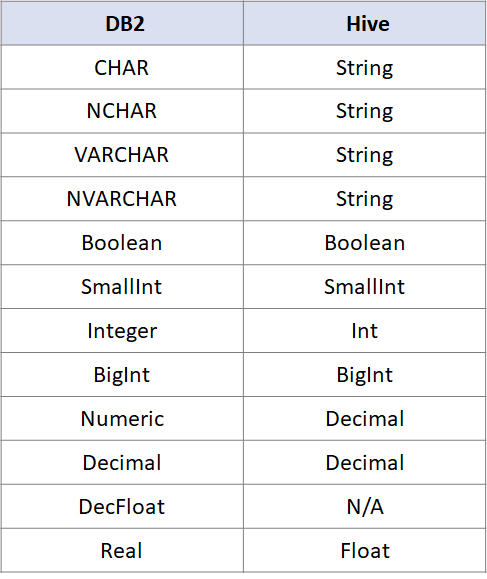
除此之外,DB2也是常见的数据库,
DB2与Hive的数据类型对照
如下:
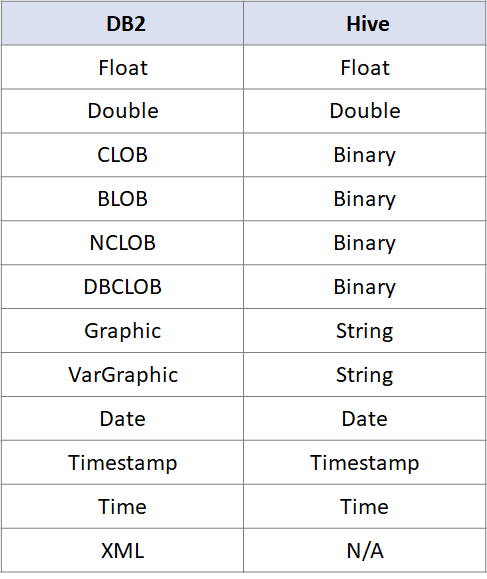
对于这些数据类型,在需要使用的时候,直接进行参考对照即可。