1. One-hot编码
要知道embedding的作用,首先要了解独热编码(one-hot)。假设现在有如下对应关系:

那么,就可以用 [0,1,4] 来表示“我是猪”这句话。
而One-hot中只存在0和1,有多少个字要编码,one-hot一行的长度就为这么多。比如一个字典中只有“我是一头猪”5个字被从0-4进行了编码,那么one-hot每一行就会有5个用0或1表示的位置,即使要表达的语句是很短的句子,例如:
[1, 0, 0, 0, 0] ———>“我” :0
[0, 1, 0, 0, 0] ———>“是” :1
[0, 0, 0, 0, 1] ———>“猪” :4
在每一句对应的编码位置都为1,其余地方都是0,也就是说,每行只会有一个1。
One-hot编码的优势是:计算方便快捷、表达能力强。
因为对于这样的稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和就可以,但问题也很明显,稀疏矩阵的资源占用太恐怖了。
在该文中,作者也举了相同的例子,可参考加深理解:
@https://zhuanlan.zhihu.com/p/164502624
One-hot的缺点:过于稀疏时,过度占用资源。
One-hot编码的缺点在长篇文字的处理中更加明显,例如:简体汉字常用3000个被从0-2999编号,也就是说在这套系统中每个单字的独热编码是3000位,如果你现在有一篇10000字的文章,那么用独热编码的方式编码之后其大小为10000×3000 = 30000000,很恐怖吧,最重要的是,其中很多东西是重复的,只是在文章的不同位置,这样会大量的浪费存储空间。
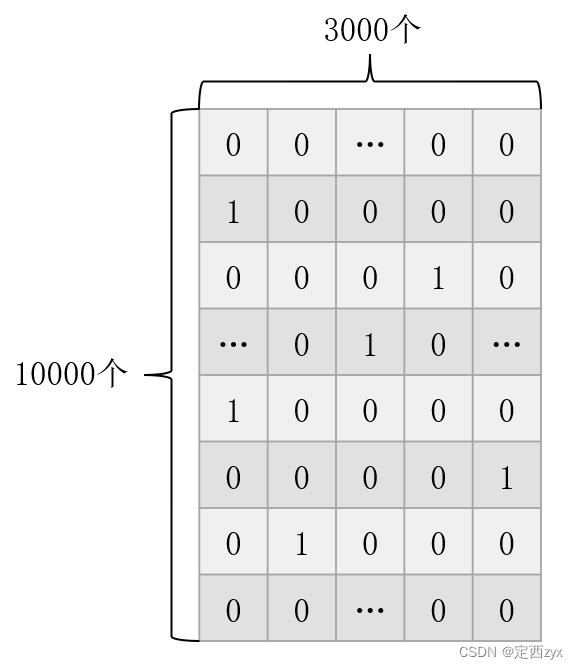
所以如何解决这个问题呢····
2. Embedding
Embedding层应运而生。
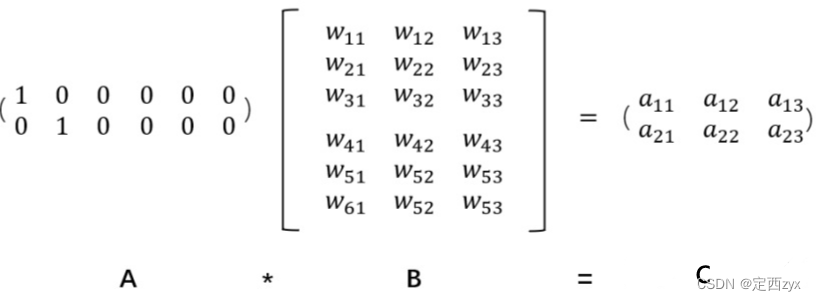
embedding的原理是使用矩阵乘法来进行降维,从而达到节约存储空间的目的。
上述图片中,我们有一个2×6的矩阵,将其乘上一个6×3的矩阵后,变成了一个2×3的矩阵。
而且,值得注意的是,虽然直观上矩阵的大小变小了,
但是其实数字蕴藏的信息并没有改变,只是按照某一种映射关系将原本矩阵的信息转换到了一个新的维度的矩阵里面;
只要按照逆向的映射关系,对矩阵进行相乘,其又会回到本身的模样!!!从这里来看,
embedding是通过某种矩阵乘法来实现矩阵数据的降维。
在实践中,如果你想把数据使用另外一个维度的张量来表示,而不想造成信息的损失,可以使用 embedding 来调整。
embedding 除了实现降维之外,还有一个很重要的
逆向功能–升维
。
当矩阵维度很低的时候,有些有效的信息是不能够被很完整地提取出来的,举个不恰当的例子:在纸上写了一个字。

经过embedding之后相当于把纸折起来或者揉搓了一下,变成了:

所以在提取信息的时候可能无法非常顺理,而通过 embedding 进行升维之后,
就相当于将整张纸展开,方便于改变成不同的感受野进行信息的提取。
但是,对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。同时,这个embedding是一直在学习在优化的,就使得整个过程慢慢形成一个良好的观察点。
3. 语义理解中Embedding意义
有了上述的理解后,我们再看个例子,它是如何运用在文本数据中的?
如下图所示,我们可以通过将两个无法比较的文字映射成向量,接下来就能实现对他们的计算。
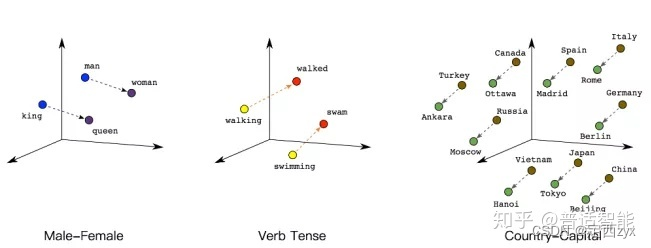
例如:
queen(皇后)= king(国王)- man(男人)+ woman(女人)
这样计算机能明白,“皇后啊,就是女性的国王呗!”
walked(过去式)= walking(进行时)- swimming(进行时)+ swam(过去式)
同理计算机也能明白,“walked,就是walking的过去式啦!”另外,向量间的距离也可能会建立联系,比方说“北京”是“中国”的首都,“巴黎”是“法国”的首都,那么向量:|中国|-|北京|=|法国|-|巴黎|
通过这种方式,
我们可以将神经网络、深度学习用于更广泛的领域,Embedding 可以表示更多的东西
,而这其中的关键在于要想清楚我们需要解决的问题和应用 Embedding 表示我们期望的内容。
4. 文本评论(代码实验)
第一步,先导入Keras相关库。
from tensorflow.keras.layers import Dense, Flatten, Input
from keras.layers.embeddings import Embedding
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import one_hot
import numpy as np
我们定义评论文本的具体内容以及指定其标签,其中1表示正面评价,0表示负面评价。
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# 1表示正面评价,0表示负面评价
labels = np.array([1, 1, 1, 1, 1, 0, 0, 0, 0, 0])
然后,我们用one-hot对其进行encode。
vocab_size = 50 # 将词汇表大小设置为50,大大减少了hash函数的冲突概率
encoded_docs = [one_hot(d, vocab_size) for d in docs] # one-hot编码到[1,n],不包括0
print('encoded_docs: ', encoded_docs)
此部分输出为:
encoded_docs: [[4, 25], [22, 36], [32, 28], [47, 36], [30], [24], [37, 28], [35, 22], [37, 36], [15, 16, 25, 19]]
注意:每次运行的结果可能不一样,但是同一个单词在同一次中一定对应相同的数字。
接下来,我们用padding对编码进行填充,保证它们的长度一致,这里将长度设置为4。
max_length = 4
# padding填充到最大的词汇长度(此处为4),用0向后填充(post)
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print('padded_docs: ', padded_docs)
这一部分的输出为:
padded_docs:
[[ 4 25 0 0]
[22 36 0 0]
[32 28 0 0]
[47 36 0 0]
[30 0 0 0]
[24 0 0 0]
[37 28 0 0]
[35 22 0 0]
[37 36 0 0]
[15 16 25 19]]
接下来,开始定义我们的模型:
input = Input(shape=(4, )) # input为一维数组,里面有4个元素
# 第一个参数表示input_dim文本数据中词汇的取值可能数
# 第二个参数表示output_dim嵌入向量空间的大小(为每个单词定义了这个层的输出向量的大小)
# 第三个参数表示input_length,输入序列的长度(一次输入带有的词汇个数)
# 嵌入层的输出是4个向量,每个向量8维
x = Embedding(vocab_size, 8, input_length=max_length)(input) # 这一步参数两为50×8(包含50个词的词汇表、一个8维的向量空间,每个词包含4个词)
# 将其展平为一个32个元素的向量,以传递给Dense输出层
x = Flatten()(x) # Embedding层的输出是一个 4×8 矩阵,它被Flatten层压缩为一个 32 元素的向量。
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input, outputs=x)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
print(model.summary())
该部分的输出为:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 4)] 0
_________________________________________________________________
embedding (Embedding) (None, 4, 8) 400 # 这里的None代表的是样本个数,即不确定的值。
_________________________________________________________________
flatten (Flatten) (None, 32) 0
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 433
Trainable params: 433
Non-trainable params: 0
_________________________________________________________________
None
对于一个句子来说,可以看出,embedding层将(1, 4)的一个输入sample(最长为4个单词的句子,其中每个单词表示为一个int数字)。嵌入为一个(1, 4, 8)的向量,即将
每个单词embed为一个8维的向量
。而整个embedding层的参数就由神经网络学习得到,数据经过embedding层之后就方便地转换为了可以由CNN或者RNN进一步处理的格式。
接下来,拟合模型并评估模型:
# 拟合模型
model.fit(padded_docs, labels, epochs=100, verbose=0)
# 评估模型
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f %%' % (accuracy*100))
输出为:
Accuracy: 89.999998 %
我们可以test一下经过embedding层之后,模型的拟合能力。
test = one_hot('good', 50)
padded_test = pad_sequences([test], maxlen=max_length, padding='post')
print(model.predict(padded_test))
输出为:
[[0.54990745]]
我们将
x = Embedding(vocab_size, 8, input_length=max_length)(input)
中的8维换成100、200、300查看效果:
当参数设置为200时,效果如下:
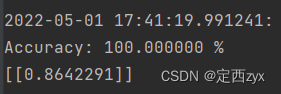
可以理解成,维度变高了,学到的语义信息更多、更准确。