复合类型构建操作
1、Map类型构建: map
语法: map (key1, value1, key2, value2, …)
说明:根据输入的key和value对构建map类型
hive> Create table iteblog as select map(‘100’,‘tom’,‘200’,‘mary’) as t from iteblog;
hive> describe iteblog;
t map<string ,string>
hive> select t from iteblog;
{“100”:“tom”,“200”:“mary”}
2、Struct类型构建: struct
语法: struct(val1, val2, val3, …)
说明:根据输入的参数构建结构体struct类型
hive> create table iteblog as select struct(‘tom’,‘mary’,‘tim’) as t from iteblog;
hive> describe iteblog;
t struct<col1:string ,col2:string,col3:string>
hive> select t from iteblog;
{“col1”:“tom”,“col2”:“mary”,“col3”:“tim”}
3、array类型构建: array
语法: array(val1, val2, …)
说明:根据输入的参数构建数组array类型
hive> create table iteblog as select array(“tom”,“mary”,“tim”) as t from iteblog;
hive> describe iteblog;
t array
hive> select t from iteblog;
[“tom”,“mary”,“tim”]
复杂类型访问操作
1、array类型访问: A[n]
语法: A[n]
操作类型: A为array类型,n为int类型
说明:返回数组A中的第n个变量值。数组的起始下标为0。比如,A是个值为[‘foo’, ‘bar’]的数组类型,那么A[0]将返回’foo’,而A[1]将返回’bar’
hive> create table iteblog as select array(“tom”,“mary”,“tim”) as t from iteblog;
hive> select t[0],t[1],t[2] from iteblog;
tom mary tim
2、map类型访问: M[key]
语法: M[key]
操作类型: M为map类型,key为map中的key值
说明:返回map类型M中,key值为指定值的value值。比如,M是值为{‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’}的map类型,那么M[‘all’]将会返回’foobar’
hive> Create table iteblog as select map(‘100’,‘tom’,‘200’,‘mary’) as t from iteblog;
hive> select t[‘200’],t[‘100’] from iteblog;
mary tom
3、struct类型访问: S.x
语法: S.x
操作类型: S为struct类型
说明:返回结构体S中的x字段。比如,对于结构体struct foobar {int foo, int bar},foobar.foo返回结构体中的foo字段
hive> create table iteblog as select struct(‘tom’,‘mary’,‘tim’) as t from iteblog;
hive> describe iteblog;
t struct<col1:string ,col2:string,col3:string>
hive> select t.col1,t.col3 from iteblog;
tom tim
复杂类型长度统计函数
1.Map类型长度函数: size(Map<k .V>)
语法: size(Map<k .V>)
返回值: int
说明: 返回map类型的长度
hive> select size(map(‘100’,‘tom’,‘101’,‘mary’)) from iteblog;
2
2.array类型长度函数: size(Array)
语法: size(Array)
返回值: int
说明: 返回array类型的长度
hive> select size(array(‘100’,‘101’,‘102’,‘103’)) from iteblog;
4
3.类型转换函数
类型转换函数: cast
语法: cast(expr as )
返回值: Expected “=” to follow “type”
说明: 返回转换后的数据类型
hive> select cast(1 as bigint) from iteblog;
1
窗口函数
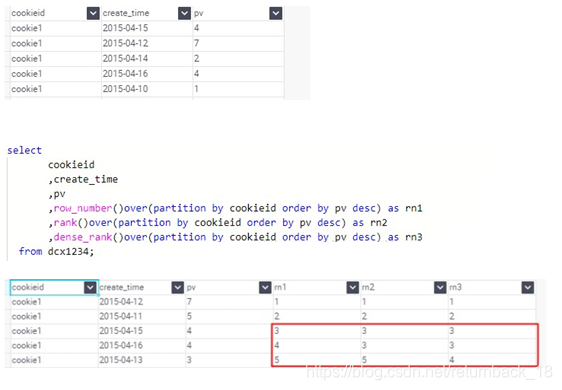
1. Row_Number,Rank,Dense_Rank
这三个窗口函数的使用场景非常多
row_number():从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列;通常用于获取分组内排序第一的记录;获取一个session中的第一条refer等。
rank():生成数据项在分组中的排名,排名相等会在名次中留下空位。
dense_rank():生成数据项在分组中的排名,排名相等会在名次中不会留下空位。
示例:数据准备
select * from dcx1234;
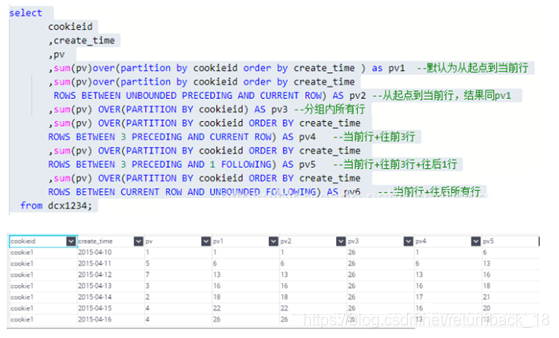
2.SUM、AVG、MIN、MAX
首先理解下什么是WINDOW子句
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
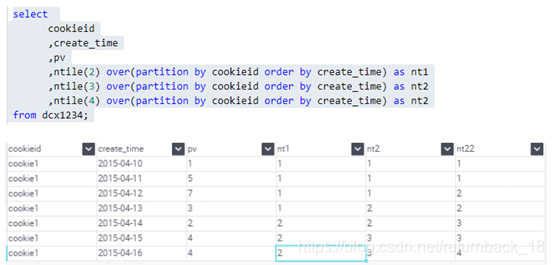
3.NTILE
NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。NTILE不支持ROWS BETWEEN
使用场景:
1.如一年中,统计出工资前1/5之的人员的名单,使用NTILE分析函数,把所有工资分为5份,为1的哪一份就是我们想要的结果.
2.sale前20%或者50%的用户ID
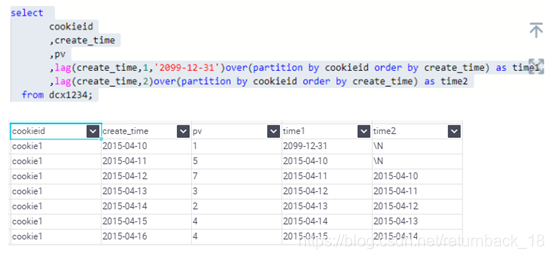
4.LEAD,LAG,FIRST_VALUE,LAST_VALUE
lag与lead函数可以返回上下行的数据
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)

使用场景:通常用于统计某用户在某个网页上的停留时间
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
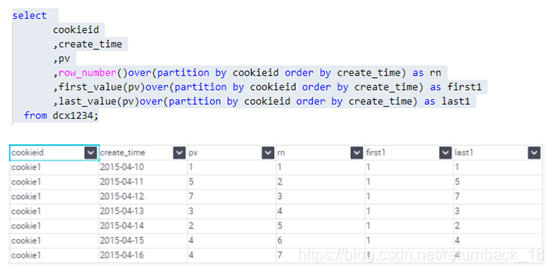
如果不指定ORDER BY,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果
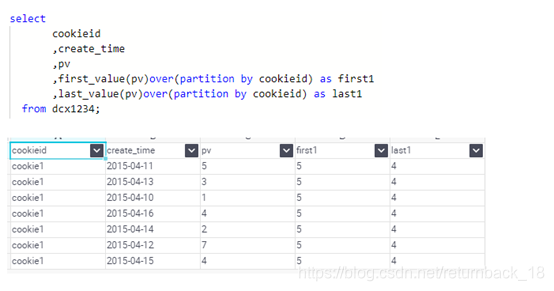
如果想要取分组内排序后最后一个值,则需要变通一下:
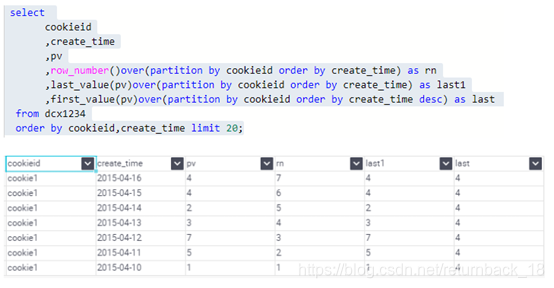
提示:在使用分析函数的过程中,要特别注意ORDER BY子句,用的不恰当,统计出的结果就不是你所期望的
5.CUME_DIST,PERCENT_RANK
这两个序列分析函数不是很常用,这里也介绍下,他不支持window子句
–CUME_DIST 小于等于当前值的行数/分组内总行数
–比如,统计小于等于当前薪水的人数,所占总人数的比例

PERCENT_RANK 分组内当前行的RANK值-1/分组内总行数-1