Camelot is a fantastic Python library to extract the tables from a pdf file as a data frame. However, I’m looking for a solution that also returns the table description text written right above the table.
The code I’m using for extracting tables from pdf is this:
import camelot
tables = camelot.read_pdf(‘test.pdf’, pages=’all’,lattice=True, suppress_stdout = True)
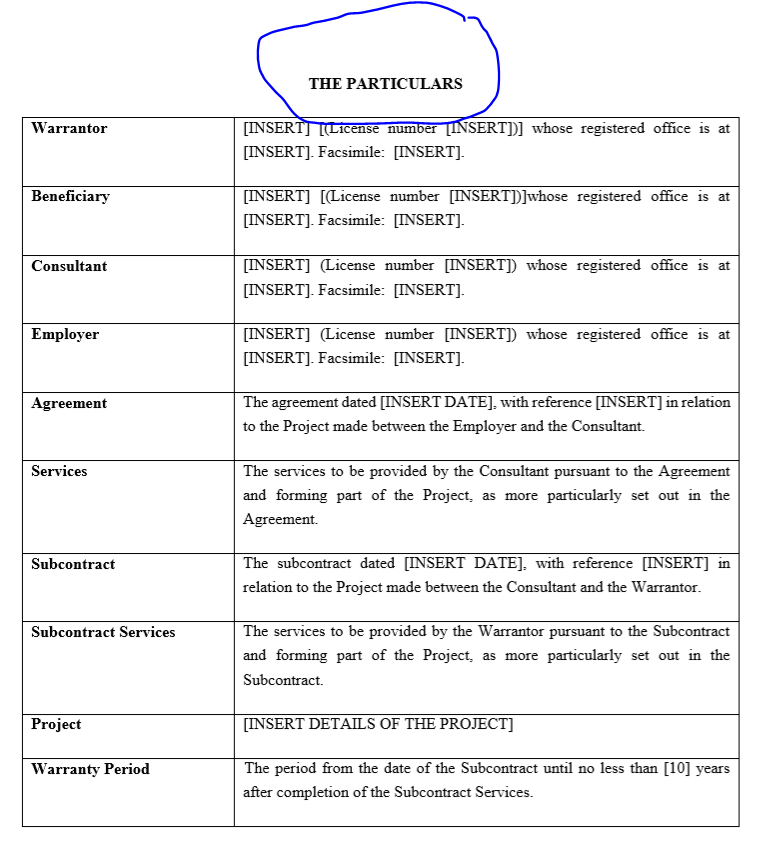
I’d like to extract the text written above the table i.e THE PARTICULARS, as shown in the image below.
What should be a best approach for me to do it? appreciate any help. thank you
解决方案
You can create the Lattice parser directly
parser = Lattice(**kwargs)
for p in pages:
t = parser.extract_tables(p, suppress_stdout=suppress_stdout,
layout_kwargs=layout_kwargs)
tables.extend(t)
Then you have access to parser.layout which contains all the components in the page. These components all have bbox (x0, y0, x1, y1) and the extracted tables also have a bbox object. You can find the closest component to the table on top of it and extract the text.