python中的多线程是伪多线程。多线程是在一个进程里面的,多线程不能并行进行,只能并发进行。多线程是数据共享的。
并行:一般针对进程,多个CPU同时处理多个进程。并行中没有GIL锁
并发:一般针对线程,一个CPU在多个线程之间来回切换。并发中有GIL锁
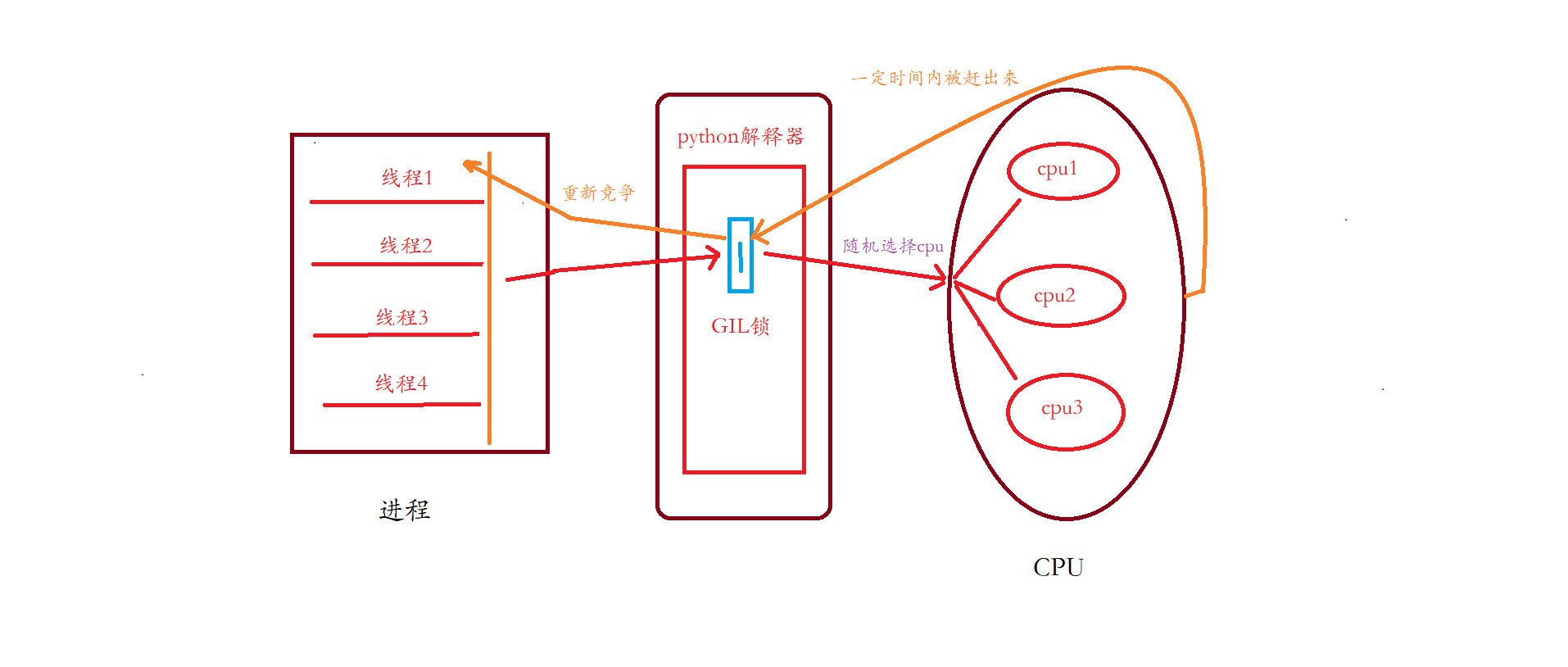
多线程处理数据流程:一个进程里面的有多个线程,python解释器里面有一把GIL锁, 到达python解释器的多线程们会和GIL锁见面,但是GIL锁每次只允许一个线程进入CPU,该线程通过GIL锁进入CPU的时候,GIL会锁上门,禁止其他线程进入,所有其他线程必须在锁外边等待进入CPU的那个线程出来以后才能进去,进去的线程会随机选择一个cpu, 固定时间后被赶出去,如果任务还没全部完成,保留资源点,回到锁外跟外面的多线程继续竞争,每次竞争都只有一个线程能进去cpu处理数据,直到所有的线程都完成任务。
from threading import Thread
num = 0
def run1():
global num
for i in range(10000):
num += 1
def run2():
global num
for i in range(10000):
num += 1
if __name__ == ‘__main__’:
t1 = Thread(target=run1)
t2 = Thread(target=run2)
t1.start()
t2.start()
t1.join()
t2.join()
print(num)
>> 20000
join()阻塞:表示必须等子线程执行完之后再取执行后面的代码
多线程的执行方式:每次只能拿一个CPU处理线程,一个CPU会在多 个线程之间进行切换,CPU的执行方式有可能是按片段执行,相当于没执行完就退出,去执行另一个线程,所以全局变量在多线程之间就会发生数据混乱。
解决方案:
加锁lock.acquire(), 解锁lock.release(), 加锁来解决数据错乱问题。加锁可以让数据全部执行完。
from threading import Thread, Lock
lock = Lock()
num = 0
def run1():
global num
for i in range(100000):
# 加锁
lock.acquire()
num += 1
# 解锁
lock.release()
def run2():
global num
for i in range(100000):
lock.acquire()# 加锁
num += 1
lock.release()# 解锁
if __name__ == ‘__main__’:
t1 = Thread(target=run1)
t2 = Thread(target=run2)
t1.start()
t2.start()
t1.join()
t2.join()
print(num)
>> 200000
多线程中局部变量不共享
线程隔离:把每一个线程id当做字典的key值,value值是请求方法,每次去取值去取线程id.
进程和线程的数据不是越多越好,创建进程和线程数量的标准,最多是电脑配置核数的两倍。