有关图像处理的课程作业需要学习一篇论文,此论文中作者使用了VQ-VAE模型对舞蹈动作进行编码。因此,对相关知识略作整理以供之后查找。
AE、VAE和VQ-VAE可以统一为latent code的概率分布设计不一样,AEr通过网络学习得到任意概率分布,VAE设计为正态分布,VQVAE设计为codebook的离散分布。
总之,AutoEncoder的重构思想就是用低纬度的latent code分布来表达高纬度的数据分布,VAE和VQVAE的重构思想是通过设计latent code的分布形式,进而控制图片生成的过程。
目录
三、VAE(Variational Auto-Encoding)-变分自动编码器
4.计算后验分布 编辑 和 先验分布 编辑 的 KL散度
一、图片重构
自编码器的常规思路:通过神经网络架构重新构建图片,可以将图片编码成一个一个不同的属性,然后通过综合这些属性解码得到重构图片。
当对图像属性进行编码时,可以将其描述为离散值或概率分布的形式(从概率分布种随机采样出离散的值)。

图片与上述思路参考自链接【1】,侵删
二、AE(Auto-Encoding)-
自动编码器
AE
:将高维的原始数据映射到一个低维特征空间,然后从低维特征学习重建原始的数据。它是一种
无监督学习方式
。

一个AE模型包含两部分网络:
- Encoder:将原始的高维数据映射到低维特征空间,即对输入图片进行编码得到latent code,起到压缩或降维的目的。
- Decoder:通过Decoder重建原始数据,计算输入图片和生成图片的重构误差,训练的时候最小化重构误差。
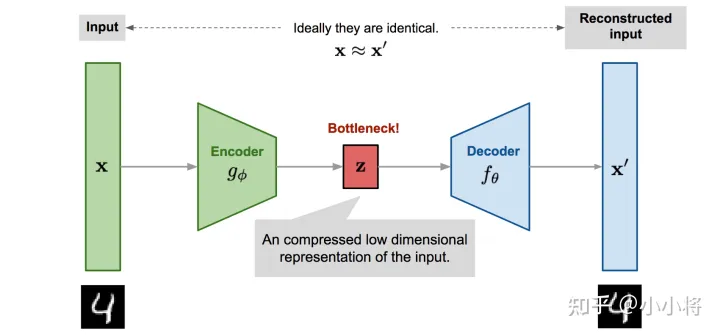
AE是通过网络学习出任意的概率分布,然后取概率分布中最高点的横坐标作为编码的离散值。因此AE的生成过程不可控。因为学习得到的概率分布是不可提前预知的,所以AE对输入的噪声敏感。
三、VAE(Variational Auto-Encoding)-变分自动编码器
VAE:基于变分推断(
Variational Inference, Variational Bayesian methods
)的概率模型,属于无监督模型。

VAE通过Encoder学习出mean和std两个编码,同时随机采样一个正态分布的编码
,然后通过
* std + mean公式重采样得到latent code,然后通过Decoder进行重建。
此外,由于正态分布的连续性,不存在不可导问题,可以通过重参数方法,对latent code进行恢复,并且通过链式求导法则进行梯度更新。

VAE的整个训练流程如上所示:输入x,encoder首先计算出后验分布的均值和标准差,然后通过重采样方法采样得到隐变量z,然后送入decoder得到重建的数据x′。
训练完成后,我们就得到生成模型
,其中
就是decoder网络,而先验
为标准正态分布,我们从
随机采样一个 z ,送入decoder网络,就能生成与训练数据 x 类似的样本。
VAE可以理解为通过网络学习出每个属性正态分布的mean和std编码,然后通过mean和std和N ( 0,1 )正态分布恢复每个属性的正态分布,最后随机采样得到每个属性的离散值。
VAE相对于AutoEncoder的好处是,当采样输入不同时,VAE对于任意采样都能重构出鲁棒的图片。VAE的生成过程是可控的,对输入噪声不敏感,我们可以预先知道每个属性都是服从正态分布的。
四、VQ-VAE 量子化(离散化)的自编码器
一个VAE模型包括三个部分:后验分布(Posterior)
,先验分布(Prior)
,以及似然(Likelihood)
。其中后验分布用encoder网络来学习,似然用decoder网络来学习,而先验分布采用
参数固定的标准正态分布
。在VAE学习过程中,后验分布往往假定是一个对角方差的多元正态分布,而隐变量 z 是一个连续的随机变量。
VQ-VAE与VAE的最主要的区别是VQ-VAE采用离散隐变量。对于encoder的输出通过向量量化(vector quantisation,VQ)的方法来离散化。论文提到了采用离散隐形变量编码的三个原因:
-
许多重要的事物都是离散的,如语言;
-
更容易对先验建模,VQ-VAE采用PixelCNN来学习先验,离散编码只需要简单地采用softmax多分类;
-
连续的表征往往被encoder/decoder内在地离散化;

VQ-VAE通过Encoder学习出中间编码,然后通过最邻近搜索将中间编码映射为codebook中K个向量之一,然后通过Decoder对latent code进行重建。
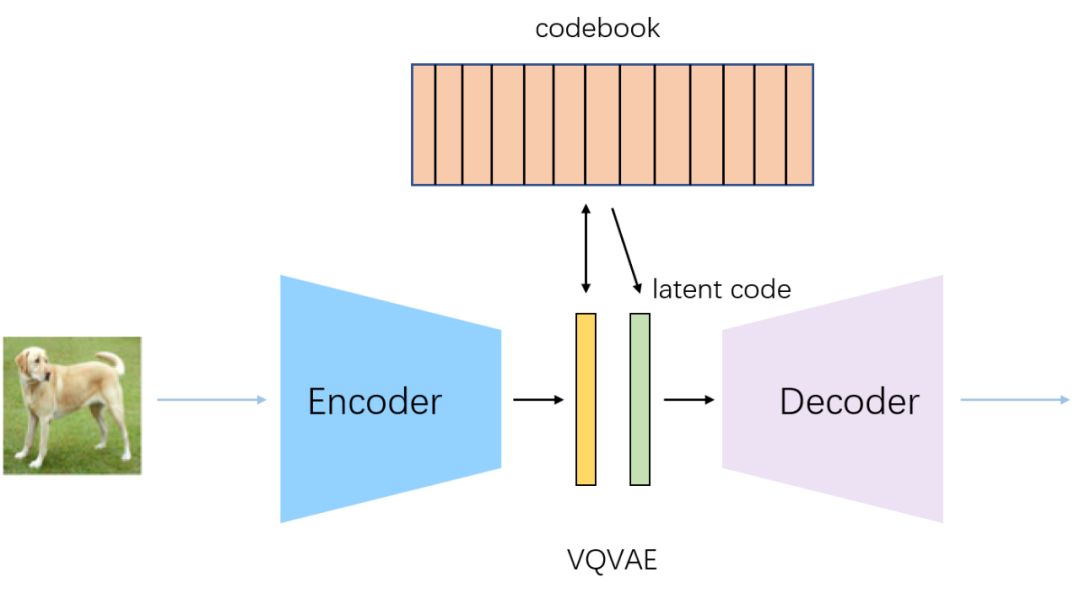
另外由于最邻近搜索使用argmax来找codebook中的索引位置,导致不可导问题,VQVAE通过stop gradient操作来避免最邻近搜索的不可导问题,也就是通过stop gradient操作,将decoder输入的梯度复制到encoder的输出上。
VQVAE相比于VAE最大的不同是,直接找每个属性的离散值,通过类似于查表的方式,计算codebook和中间编码的最近邻作为latent code。由于维护了一个codebook,编码范围更加可控,VQVAE相对于VAE,可以生成更大更高清的图片(这也为后续DALLE和VQGAN的出现做了铺垫)。
4.1 向量化VQ
1.PixelCNN
VQ-VAE做生成模型的思路,源于
PixelRNN
、
PixelCNN
之类的自回归模型。
自回归的方法很稳妥,也能有效地做概率估计,但它有一个最致命的缺点:
慢
。
原始的自回归还有一个问题,就是
割裂了类别之间的联系
。虽然说因为每个像素是离散的,所以看成256分类问题也无妨,但事实上连续像素之间的差别是很小的,纯粹的分类问题捕捉到这种联系。更数学化地说,就是我们的目标函数
交叉熵
是
,假如目标像素是100,如果我预测成99,因为类别不同了,那么
就接近于0,
就很大,从而带来一个很大的损失。但从视觉上来看,像素值是100还是99差别不大,不应该有这么大的损失。
除了训练好 VQ-VAE ,还需要训练一个
先验模型
来完成数据生成,对于图像来说,可以采用
PixelCNN 模型
,这里我们不再是学习生成原始的 pixels,而是学习生成离散编码。首先,我们需要用已经训练好的 VQ-VAE 模型对训练图像推理,得到每张图像对应的离散编码;然后用一个PixelCNN来对离散编码进行建模,最后的预测层采用基于softmax的多分类,类别数为embedding空间的大小 K。那么,生成图像的过程就比较简单了,
首先用训练好的 PixelCNN 模型来采样一个离散编码样本,然后送入 VQ-VAE 的 decoder中,得到生成的图像。
整个过程如下图所示:

2.离散隐变量空间
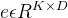
-embedding空间
K 为 embedding 空间大小(向量个数),D 为每个 embedding 向量
的维度。因此,
embedding空间
总共有 K 个
embedding向量
,
。采用
最近邻的查找方法
来将encoder的输出
量化为其中的一个embedding向量。

3.量化encoder的输出
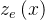
-标准化输出
最近邻的查找方法
的实质为 计算 输出
和每个embedding向量
的欧氏距离,选择距离最小的向量
作为
量化值
。
将作为 decoder 的输入。因此,VQ-VAE 的整个过程可以表示为:

4.计算后验分布
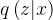
和 先验分布
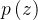
的 KL散度
VAE 的后验分布
为多元高斯分布,但 VQ-VAE 经过 VQ 之后,后验分布
可以看作一个
多类分布(
categorical distribution
),
其概率分布为 one-hot 型:

此时,VQ-VAE 的后验分布变成了 一个 确定的分布。k 的确定不涉及随机因素。若将先验分布
定义为 均匀的多类分布(每个类别的概率为 1/k),则可以直接计算后验分布 和 先验分布 的
KL 散度/相对熵(
Kullback-Leibler divergence
:计算两个分布差异最常用的)
:
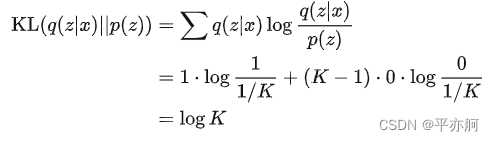
计算得到,KL 散度为一个常数,那么 VQ-VAE 的训练损失就只剩下了一项重建误差
。可以观察到,VQ-VAE 的训练过程没有用到先验分布,所以后面需要单独训练一个先验模型来生成数据。
VQ-VAE分成两个阶段来得到生成模型
,可以避免 VAE 训练过程中容易出现的“posterior collapse”。
5.
straight-through estimator
VQ-VAE还存在一个问题,那就是
由于argmin操作不可导,所以重建误差的梯度就无法传导到encoder
。论文采用
straight-through estimator
来解决这个问题。
梯度反向传播进行更新:
-
encoder的梯度更新:
Straight-Through的思想很简单,就是前向传播的时候可以用想要的变量(哪怕不可导),而反向传播的时候,用你自己为它所设计的梯度。根据这个思想,我们设计的目标函数是:
其中 sg 是 stop gradien t的意思,就是不要它的梯度。这样一来,前向传播计算(求loss)的时候,就直接等价于
,然后反向传播(求梯度)的时候,由于
不提供梯度,所以它也等价于
,这个就允许我们对 encoder 进行优化了。
VQ-VAE 的 decoder 的输入是
,直接用重建误差相对于
的梯度来作为encoder的输出
的梯度,由于
和
的维度一样,所以这样做不需要任何特殊处理。
虽然通过
straight-through estimator
方法,重建误差的梯度可以传导到encoder,但是embedding向量
就接收不到重建误差带的梯度了,这也意味着embedding空间无法参与学习。
-
embedding空间的更新
:
根据VQ-VAE的最邻近搜索的设计,我们应该期望
和
是很接近的。所以,为了让
和
更接近,我们可以直接地将
加入到loss中:
![\left \| x-decoder\left ( z+sg\left [z _{q}-z \right ] \right ) \right \|_{2}^{2}+\beta \left \| z-z_{q} \right \|_{2}^{2}](https://latex.csdn.net/eq?%5Cleft%20%5C%7C%20x-decoder%5Cleft%20%28%20z+sg%5Cleft%20%5Bz%20_%7Bq%7D-z%20%5Cright%20%5D%20%5Cright%20%29%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D+%5Cbeta%20%5Cleft%20%5C%7C%20z-z_%7Bq%7D%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D)
由于编码表
相对是比较自由的,而
要尽力保证重构效果,所以我们应当尽量“
让
去靠近
”,而因为
的梯度等于对
的梯度加上对
的梯度,所以我们将它等价地分解为:
![\left \| sg\left [ z \right ] -z_{q}\right \|_{2}^{2}+\left \| z-sg\left [ z_{q} \right ] \right \|_{2}^{2}](https://latex.csdn.net/eq?%5Cleft%20%5C%7C%20sg%5Cleft%20%5B%20z%20%5Cright%20%5D%20-z_%7Bq%7D%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D+%5Cleft%20%5C%7C%20z-sg%5Cleft%20%5B%20z_%7Bq%7D%20%5Cright%20%5D%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D)
根据我们刚才的讨论,我们希望“让
去靠近
”多于“让
去靠近
”,所以可以调一下最终的loss比例:
![\left \| x-decoder\left ( z+sg\left [z _{q}-z \right ] \right ) \right \|_{2}^{2}+\beta \left \| sg\left [ z \right ]-z_{q} \right \|_{2}^{2}+\gamma \left \| z-sg\left [ z_{q} \right ] \right \|_{2}^{2}](https://latex.csdn.net/eq?%5Cleft%20%5C%7C%20x-decoder%5Cleft%20%28%20z+sg%5Cleft%20%5Bz%20_%7Bq%7D-z%20%5Cright%20%5D%20%5Cright%20%29%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D+%5Cbeta%20%5Cleft%20%5C%7C%20sg%5Cleft%20%5B%20z%20%5Cright%20%5D-z_%7Bq%7D%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D+%5Cgamma%20%5Cleft%20%5C%7C%20z-sg%5Cleft%20%5B%20z_%7Bq%7D%20%5Cright%20%5D%20%5Cright%20%5C%7C_%7B2%7D%5E%7B2%7D)
其中
,在
原论文
中使用的是
。
为了让embedding空间参与训练,论文采用了一种简单的字典学习方法,即计算encoder的输出
和对应的量化得到的embedding向量
的
L2误差(
VQ loss
)
:

此处的
sg 指的是stop gradient操作(即不计算输入的梯度)
,这意味着这个 L2 损失只会更新embedding空间,而不会传导到encoder。
这里,我们也可以采用另外一种方式:
指数移动平均(exponential moving averages,EMA)
来更新embedding空间。假定
为一系列和embedding向量
对应的encoder的输出,此时L2损失为:

此时embedding向量
的最优值有解析解,即对所有的元素求平均值:
。 然而,训练过程中无法直接这样更新,因为训练是基于mini-batch的,并不是训练数据的全部。类比BatchNorm,我们可以采用EMA来更新embedding:
这里共需要维护两套EMA参数,一是每个embedding向量
的对应的
元素数量
,二是
的求和值
。每次forward时,我们根据当前mini-batch得到
,然后执行EMA,而用
除以
即可得到当前的embedding向量。
采用EMA这种更新方式往往比直接采用L2损失收敛速度更快
,论文采用的decay值
为0.99。
6.encoder误差
除此之外,论文还额外增加一个
训练loss
:
commitment loss
,这个主要是约束encoder的输出和embedding空间保持一致,以避免encoder的输出变动较大(从一个embedding向量转向另外一个)。
commitment loss
也比较简单,直接计算encoder的输出
和对应的量化得到的embedding向量
的L2误差:

注意这里的sg是作用在embedding向量
上,这意味着这个约束只会影响encoder。
综上,VQ-VAE共包含三个部分的训练loss:
reconstruction loss,VQ loss,commitment loss。

其中
reconstruction loss
作用在encoder和decoder上,
VQ loss
用来更新embedding空间(也可用EMA方式),而
commitment loss
用来约束encoder,这里的
为权重系数,论文默认设置为0.25。
另外,在实际实验中,一张图像会采用 N 个离散隐变量,这个和encoder得到的特征图大小有关。对于ImageNet数据集,采用 32×32 大小的中间特征图,所以 N=32×32;对于CIFAR10数据集,采用8×8大小的中间特征图,所以 N=8×8。对于一张图像,
VQ loss
和
commitment loss
取 N个离散编码的loss平均值。从自动编码器的角度来看,VQ-VAE实现了对图像的压缩,即将一张图像压缩成 N 个离散编码。这里要说明的一点是,VQ-VAE适用于多种模态的数据,除了图像之外,还可以用于语音和视频的生成,这里只讨论图像。
【1】漫谈VAE和VQVAE,从连续分布到离散分布 – 知乎 (zhihu.com)