P for trend是回归模型中线性
趋势性检验
的结果,P for trend主要是用来检验自变量X的变化与因变量Y的变化之间是否存在一定的线性变化趋势。
一、趋势性分析的意义
对于原始变量本身即为连续型变量时,为什么不将原始变量直接带入到模型中进行分析呢?为什么还要大费周折将其转化为等级变量,然后再做一遍趋势性检验呢?直接带入原始变量时所得的P值不是能更好的说明该变量与因变量之间的变化趋势么?
1、当自变量以连续型变量的形式引入模型时,其意义解释为该自变量每增加1个单位,所引起的因变量Y的变化(β),或结局发生风险的变化(OR/HR),
但实际上这种变化效应有时是很微弱的,并没有太大的临床意义,因此需要对连续型变量进行适当的转化
。如年龄增加1岁,血压升高0.1mmHg,这种就属于有统计学意义,但没有临床意义。
2. 如果直接将原始的连续型变量带入到回归模型中,其前提是已经假定该连续型自变量与因变量之间存在着一定的线性关系。但是,当自变量与因变量之间的相互变化关系不明确时,
以连续型变量带入模型会遗漏一些很重要的信息。有时候变量之间不是线性关系
,比如分4组,1:4应该先有统计学意义;然后才可能1;3,再而1:2;如果出现顺序错乱,很可能说明数据并不呈现线性趋势而是U型或其他形式。
二、连续型变量转换。
1、
二分类分组
将连续型变量按照某个切点转化为二分类变量。二分类变量有2个分类属性,我们选择其中一个分类作为参照(通常设置变量=0),则另一个分类自动作为比较组(通常设置变量=1)。
那么如何确定二分类分组的切点呢?通常情况下,为了保证以切点划分的两组研究对象,在样本量上能够尽量保持一致,我们可以以该自变量的
中位数
为切点进行分组,即按照中位水平分为高、低两组来进行比较;或者也可以按照
临床实践
中具有某种特殊意义的诊断切点作为分组标准,将研究人群分为有无此类疾病特点的两组来进行比较。
2、等分位分组
将连续型变量进行二分类分组,这种方法固然简单易行,也便于理解,但是在有些情况下,比如我们想要更多地观察自变量与因变量之间复杂的变化关系,此时若仅分为二组,则会遗漏很多重要的信息,使得数据本身的价值没有得到更充分的利用。
因此,在借鉴二分类分组思想的基础上,我们可以对连续型变量进一步离散化,根据样本量和分析的需要,通常可以按照该变量的三分位、四分位或者五分位等切点来进行分组。
进行等分位分组,其优点在于不仅可以保证每一组的研究人群在样本量上能够保持相对一致,而且可以较为直观的反映自变量与因变量之间复杂的变化关系,为进一步探讨两者之间的关联性提供了一定的依据。
3、等距分组
在进行等分位分组时,研究对象被均匀分组,基本上每一组研究人群的样本量大致相同,但是组与组之间的
间距却很难保证是一致的
。例如上述研究中,研究人员对水果纤维摄入水平进行5分位分组,每一组的中位数分别为1.45、2.55、3.55、4.69、6.68,相邻两组之间的
间距是不相等的
。
当我们需要探讨某个连续型自变量,在每增加固定间距的单位水平时,引起的因变量的变化效应,就可以将该
自变量以一个设定好的固定间距
,对其进行分组,然后再引入到模型中进行分析。
这样分组转换的好处在于,在实际的临床应用中,分析结果的临床意义易于解释和理解。等分位分组时,切点的选择是依赖于当前的研究人群,如果研究人群发生了变化,其分组的切点也会跟着发生变化;
但是如果以固定的单位间距作为切点去分组,在进行临床解释时则更加便于病人理解和接受
。
采用等距分组的方式进行转换,实际上并不会改变该自变量对因变量的作用大小,只是相当于放大了效应值本身的数值,从而使得结果更为好看和直观。
4、
组内中位数转换
对等级资料赋值为0、1、2、3的前提,是假定每个分组内相邻两组之间的间距是相等的,但是多数情况下无法满足这一等距的条件,因此我们需要用到
组内中位数转换方法
。
研究人员在表格的标注中已经明确指出:Test for trend based on variable containing median value for each quintile。
在Ann Inter Med期刊(影响因子:17.14)2017年8月份发表的一篇文章《Association of Coffee Consumption With Total and Cause-Specific Mortality Among Nonwhite Populations》中也提到:We performed tests for linear trend by entering the median value of each category of coffee consumption as a continuous variable in the models。
即此时不再将原始的连续型变量赋值为0、1、2、3,而是用每组的中位数进行重新赋值,然后将重新赋值的变量以连续型变量的形式带入到模型中,所求得的该变量的P值即为P for trend的检验结果。
5
、临床界值分组
和自定义
对连续型变量进行等分位分组或等距分组时,它们对于数据本身的依赖性较强,主要适用于那些较新的研究指标,这些指标往往是探索性的,还没有或者即将应用的临床实践中,此时可以利用等分位或等距法作为分组切点的依据。但是对于那些已经在临床中得到广泛应用的指标,指南对其已经推荐了明确的诊断切点,为了更好的用于临床解释,我们可以直接将指南推荐的诊断切点作为分组的依据来进行划分。
当然,除了按照上述分组的切点原则,对于较新颖的、非常规的指标,临床上并没有给定参考的界值,此时你可以根据自身数据的特点和分析的需要,自行设置合理的分组切点,可以尝试不同的切点分组方法,只要你的分组切点有理有据,能够说服大家,结果能够被重复出来,我们都认为这样的切点是合理的,因为真理总是在不断的尝试中才能逐渐显现出来。
三、spss实现
根据目标变量的不同,分为3类:
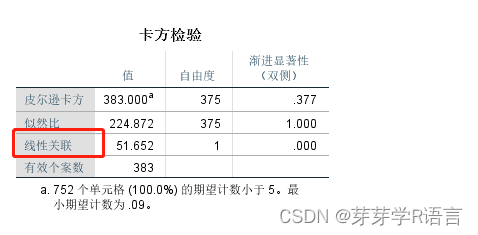
1、分类变量趋势性分析:统计方法采用趋势卡方,具体操作与普通卡方检验步骤相同。下图中“线性关联”即为趋势卡方检验的结果,此例中,卡方值为51.652,P值为0.000,提示存在线性关联。表格中的
“线性关联”
即为趋势卡方检验的结果
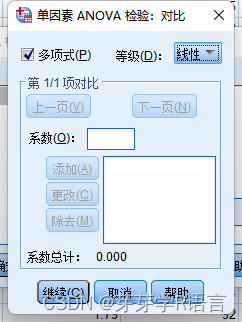
2.数值变量趋势性分析:
统计方法采用趋势方差,具体操作与单因素方差分析步骤相同,但需要在对比模块中,
勾选多项式,选择线性。
3、多因素回归
如果要校正混杂因素,需要使用多因素回归分析,如Logistic回归、Cox回归和多重线性回归。步骤也不复杂,做回归分析时,自变量直接选入模型进行分,得到的p值即为p for trend。
哑变量的设置的条件是自变量和因变量没有线性关系。有线性关系就可以不设置,没有线性关系就需要设置。
等级资料不需要设置
哑
变量
,
但如果等级变量严重不等距也需要考虑设置哑变量。
参考::
高分SCI都在用 P for trend,快来看看吧_统计与绘图_实用技巧_科研星球
想将连续变量转化为哑变量纳入回归模型,咋分组? – 专栏课程 – 医咖会 (mediecogroup.com)
:
想将连续变量转化为哑变量纳入回归模型,咋分组? – 专栏课程 – 医咖会
文献中常看到的P for trend,到底是个啥,该怎么操作实现? (sohu.com)
:
logistic与Cox回归的P for trend:一个临床医生创造的指标