时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。本文我们会分享如何用历史股票数据进行基本的时间序列分析(以下简称时序分析)。首先我们会创建一个静态预测模型,检测模型的效度,然后分享一些用于时序分析的重要工具。
在创建模型之前,我们先简要了解时间序列的一些基本参数,比如移动平均线、趋势、季节性等。
获取数据
我们本文会用到 MRF 过去五年的“调整价格”,用 pandas_datareader 可以从 Yahoo财经上获取所需的数据。我们首先导入需要的库:
import pandas as pd
import pandas_datareader as web
import matplotlib.pyplot as plt
import numpy as np
现在我们用 datareader 获取数据,主要是自 2012 年 1 月 1 日至 2017 年 12 月 21 日的股票数据。当然也可以只用调整收盘价,因为这是最相关的价格,应用在所有的金融分析中。
stock = web.DataReader('MRF.BO','yahoo', start = "01-01-2012", end="31-12-2017")
stock = stock.dropna(how=’any’)
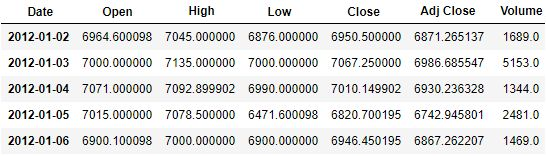
我们可以用 head() 函数检查数据。
stock.head()
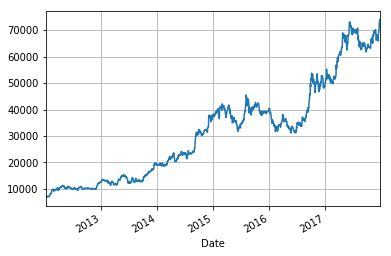
我们可以用导入的 matplotlib 库再次绘制出时间段内的调整价格。
stock[‘Adj Close’].plot(grid = True)
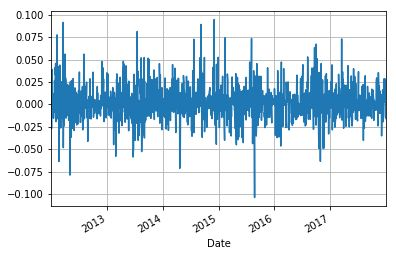
计算和绘制每日收益
利用时间序列,我们可以计算出随着时间变化的每日收益,并绘制出收益变化图。我们将从股票的调整收盘价中计算出每日收益,以列名“ret”储存在同一数据帧“stock”中。
stock['ret'] = stock['Adj Close'].pct_change()
stock['ret'].plot(grid=True)
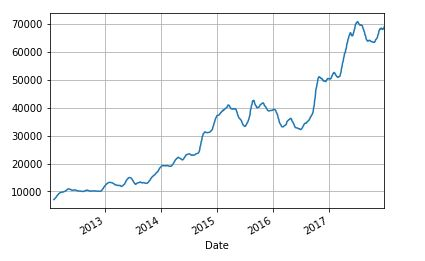
移动平均数
和收益相同,我们可以计算和绘制出调整收盘价格的移动平均线。移动平均线是广泛应用于技术分析中的一个非常重要的指标。出于简要说明的目的,这里我们只计算 20 天移动平均线作为示例。
stock['20d'] = stock['Adj Close'].rolling(window=20, center=False).mean()
stock['20d'].plot(grid=True)
在搭建模型预测前,我们先快速看看时间序列中的趋势和季节性。
趋势和季节性
简单来说,趋势表示时间序列在一段时间内的整体发展方向。趋势和趋势分析同样广泛应用于技术分析中。如果在时间序列中定期出现一些模式,我们就说数据具有季节性。时间序列中的季节性会影响预测模型的结果,因此对它不能掉以轻心。
预测
我们会讨论一个简单的线性分析模型,假设时间序列呈静态,且没有季节性。也就是这里我们假设时间序列呈线性趋势。模型可以表示为:
Forecast (t) = a + b X t
这里的“a”为时间序列在Y轴上的截距,“b”为斜率。我们现在看看 a 和 b 的计算。我们考虑时间序列在时间段“t”内的值D(t)。
在这个方程式中,“n”是样本大小。我们可以通过用上面的模型计算 D(t)的预测值,并将值和实际观测值比较,进而验证我们的模型。我们可以计算出平均误差,即预测 D(t)值和实际 D(t)值之间的差距的平均值。
在我们的股票数据中,D(t)是 MRF 的调整收盘价。我们现在用 Python 计算 a,b,预测值和它们的误差值。
#Populates the time period number in stock under head t
stock['t'] = range (1,len(stock)+1)
#Computes t squared, tXD(t) and n
stock['sqr t']=stock['t']**2
stock['tXD']=stock['t']*stock['Adj Close']
n=len(stock)
#Computes slope and intercept
slope = (n*stock['tXD'].sum() - stock['t'].sum()*stock['Adj Close'].sum())/(n*stock['sqr t'].sum() - (stock['t'].sum())**2)
intercept = (stock['Adj Close'].sum()*stock['sqr t'].sum() - stock['t'].sum()*stock['tXD'].sum())/(n*stock['sqr t'].sum() - (stock['t'].sum())**2)
print ('The slope of the linear trend (b) is: ', slope)
print ('The intercept (a) is: ', intercept)
上面的代码会给出如下输出:
The slope of the linear trend (b) is: 41.2816591061
The intercept (a) is: 1272.6557803
我们现在可以通过计算预测值和平均误差来验证模型的效度。
#Computes the forecasted values
stock['forecast'] = intercept + slope*stock['t']
#Computes the error
stock['error'] = stock['Adj Close'] - stock['forecast']
mean_error=stock['error'].mean()
print ('The mean error is: ', mean_error)
输出的平均误差如下所示:
The mean error is: 1.0813935108094419e-10
从平均误差值可以看出,我们的模型给出的值非常接近实际值。因此数据没有受到任何季节性方面的影响。
下面我们讨论一些用于分析时序数据的很实用的工具,它们对于金融交易员在设计和预先测试交易策略时非常有帮助。
交易员们常常要处理大量的历史数据,并且根据这些时间序列进行数据分析。我们这里重点分享一下如何应对时间序列中的日期和频率,以及索引、切片等操作。主要会用到 datetime库。
我们首先将 datetime 库导入到程序中。
#Importing the required modules
from datetime import datetime
from datetime import timedelta
处理日期和时间的基本工具
先将当前日期和时间保存在变量“current_time”中,执行代码如下:
#Printing the current date and time
current_time = datetime.now()
current_time
Output: datetime.datetime(2018, 2, 14, 9, 52, 20, 625404)
我们可以用 datetime 计算两个日期的不同之处。
#Calculating the difference between two dates (14/02/2018 and 01/01/2018 09:15AM)
delta = datetime(2018,2,14)-datetime(2018,1,1,9,15)
delta
Output: datetime.timedelta(43, 53100)
使用如下代码将输出转换为用“天”或“秒”表达:
#Converting the output to days
delta.days
Output: 43
#Converting the output to seconds
delta.seconds
Output: 53100
如果我们想变换日期,可以用前面导入的 timedelta 模块。
#Shift a date using timedelta
my_date = datetime(2018,2,10)
#Shift the date by 10 days
my_date + timedelta(10)
Output: datetime.datetime(2018, 2, 20, 0, 0)
我们也可以用 timedelta 函数的乘法。
#Using multiples of timedelta function
my_date - 2*timedelta(10)
Output: datetime.datetime(2018, 1, 21, 0, 0)
我们前面看过了 datetime 模块的“datetime”和“timedelta”数据类型。我们简要说明一下在分析时间序列时用到的主要数据类型:
数据类型
描述
Date
用公历保存日历上的日期(年,月,日)
Time
将时间保存为小时、分钟、秒和微秒
Datetime
保存date和time两种数据类型
Timedelta
保存两个datetime值的不同之处
字符串和 datetime 之间的转换
我们可以将 datetime 格式转换为字符串,并以字符串变量进行保存。也可以反过来,将表示日期的字符串转换为 datetime 数据类型。
#Converting datetime to string
my_date1 = datetime(2018,2,14)
str(my_date1)
Output: '2018-02-14 00:00:00'
我们可以用 strptime 函数将字符串转换为 datetime。
#Converting a string to datetime
datestr = '2018-02-14'
datetime.strptime(datestr, '%Y-%m-%d')
Output: datetime.datetime(2018, 2, 14, 0, 0)
也可以用 Pandas 处理日期。我们先导入 Pandas。
#Importing pandas
import pandas as pd
在 Pandas 中用“to_datetime”将日期字符串转换为 date 数据类型。
#Using pandas to parse dates
datestrs = ['1/14/2018', '2/14/2018']
pd.to_datetime(datestrs)
Output: DatetimeIndex(['2018-01-14', '2018-02-14'], dtype='datetime64[ns]', freq=None)
在 Pandas 中,将缺失的时间或时间中的 NA 值表示为 NaT。
时间序列的索引和切片
为了更好的理解时间序列中的多种操作,我们用随机数字创建一个时间序列。
#Creating a time series with random numbers
import numpy as np
from random import random
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5), datetime(2011, 1, 7), datetime(2011, 1, 8), datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
Output:
2011-01-02 0.888329
2011-01-05 -0.152267
2011-01-07 0.854689
2011-01-08 0.680432
2011-01-10 0.123229
2011-01-12 -1.503613
dtype: float64
用我们展示的索引,可以将该时间序列的元素调用为任何其它 Pandas 序列。
ts[’01/02/2011′] 或 ts[‘20110102’]会给出同样的输出0.888329
切片操作和我们对其它 Pandas 序列的切片操作相同。
时间序列中的重复索引
有时你的时间序列会包含重复索引。看一下如下时间序列:
#Slicing the time series
ts[datetime(2011,1,7):]
Output:
2011-01-07 0.854689
2011-01-08 0.680432
2011-01-10 0.123229
2011-01-12 -1.503613
dtype: float64
在上面的时间序列中,我们可以看到“2018-01-02”重复出现了 3 次。我们可以用 index 函数的“is_unique”属性检查这一点。
dup_ts.index.is_unique
Output: False
可以用 groupby 功能集合有相同索引的记录。
grouped=dup_ts.groupby(level=0)
我们现在可以根据自己的需求,使用这些记录的平均值、计数、总和等等。
grouped.mean()
Output:
2018-01-01 -0.471411
2018-01-02 -0.013973
2018-01-03 -0.611886
dtype: float64
grouped.count()
Output:
2018-01-01 1
2018-01-02 3
2018-01-03 1
dtype: int64
grouped.sum()
Output:
2018-01-01 -0.471411
2018-01-02 -0.041920
2018-01-03 -0.611886
dtype: float64
数据位移
我们可以用 shift 函数转移时间序列的索引。
#Shifting the time series
ts.shift(2)
Output:
2011-01-02 NaN
2011-01-05 NaN
2011-01-07 0.888329
2011-01-08 -0.152267
2011-01-10 0.854689
2011-01-12 0.680432
dtype: float64
总结
本文我们简要讨论了时间序列的一些属性,以及如何用 Python 计算它们。同时也用一个简单的线性模型预测时间序列。最后分享了分析时间序列时用到的一些基本功能,比如将日期从一种格式转换为另一种格式。
推荐阅读: