Python爬虫基础
对象序列化
对象序列化
序列化
-
对象序列化
程序运行时能将内存中的对象、信息直接保存下来的机制,称为对象序列化
-
对象反序列化
将保存的数据读取并转换为存储区域的对象信息,称之为对象反序列化
使用pickle模块
-
概述
-
pickle模块是Python自带模块
-
将Python对象转化为字节流,此过程为
Pickling -
将字节流转化为Python对象,此过程为
Unpickling -
这些对象的字节流可以被传输或存储,然后再重构出一个拥有相同特征的新对象
-
-
dump()函数和load()函数-
dump()函数可接受一个文件柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中。
-
load()函数可以接受一个文件柄(包含序列化后的数据的字符串对象、直接返回的对象),并读取文件中序列化后的数据
-
-
dumps()函数和loads()函数-
dumps()函数可接受流对象并将其序列化后的数据保存到磁盘文件中,并返回序列化的数据。
-
loads()函数可接受流对象(包含序列化后的数据的字符串对象、直接返回的对象),并读取文件中序列化后的数据
-
使用shelve模块
-
概述
- shelve模块是Python自带模块,内置对象持久化保存的方法
- 将对象保存到文件中。
- 缺省的数据存储文件是二进制的。
- 提供一个简单的数据存储方案
-
open()函数和close()函数-
open()函数创建或打开一个shelve对象
shelve.open('filename',flag='c',protocol=None,writeback=False)- shelve:默认打开方式支持同时读写操作。
- filename:关联的文件路径。
- flag:可选参数,默认为’c’,允许读写,如果数据文件不存在就创建;’r’只读;’w’可读写;’n’可读写,每次调用
open()都重新创建一个空的文件。 - protocol:序列化模式,默认值为None。
- writeback:默认值为False;True,shelve对象把DB中读取的对象存放到一个内存缓存中。
-
close()函数使用完shelve对象后必须将shelve对象关闭的操作
-
-
用法
使用
shelve.open()函数获取一个shelve对象就可以对数据增删改查,再使用shelve.close()函数将shelve对象关闭-
普通的使用
import shelve s=shelve.open('filename',writeback=True) xxx s.close() -
with语句的使用
import shelve with shelve.open('filename',writeback=True) as fw: xxx
-
列表代表整个记录集,元组代表一条记录
数据库与数据文件管理
sqlite 3数据库
-
sqlite 3是Python中内置模块
-
创建一个表示数据库的连接对象,再创建光标对象,再编写需执行的SQL语句
-
内置API
API 参数列表 描述 sqlite3.connect()(database[,timeout,other optional arguments]) 该 API 打开一个到 SQLite 数据库文件 database 的链接。如果数据库成功打开,则返回一个连接对象 connection.cursor()([cursorClass]) 该函数可以创建一个cursor游标对象,配合数据库编程语句中使用 cursor.execute()(sql[,optional parameters]) 该函数执行SQL语句,参数化时使用占位符替代SQL文本,。sqlite3 模块支持两种类型的占位符:问号 ?和命名占位符%s。connection.execute()(sql,[optional parameters]) 该函数类似 cursor.execute()功能,省略创建中间游标对象的过程connection.executemany()(sql,[seq_of_parameters]) 该函数可直接对于多个SQL语句进行多次执行 connection.commit()该函数用于提交当前事物,否则会停留在上次提交动作。 connection.rollback()该函数回滚到上次调用 commit()的修改前connection.close()该函数用于关闭数据库连接。关闭前需要提交,即 commit()cursor.fetchone()该函数获取查询结果集的下一行,返回一个单一的序列。 cursor.fetchmany()([size=cursor.arraysize]) 该函数获取查询结果集中的下一行组,返回一个列表 cursor.fetchall()该函数获取查询结果集中的所有行(或剩余行),返回一个列表。 在查询过程中,游标对象类似一个记录指针,每读取一条记录,指针都是后移,所以同函数内对应的
fetchone()、fetchmany()、fetchall()对应的数据也是不一致的。 -
操作
-
连接数据库
-
直接连接
import sqlite3 conn = sqlite3.connect('xxx.db')如果数据库不存在,那么它就会被创建,最后将返回一个数据库对象。
-
with连接
import sqlite3 with sqlite3.connect('xxx.db') as conn:
-
-
创建表
import sqlite3 conn = sqlite3.connect('xxx.db') cur = conn.cursor() create_sql ='''CREATE TABLE t();''' cur.execute(create_sql) conn.commit() conn.close() -
insert、update、delete、select操作
import sqlite3 conn = sqlite3.connect('xxx.db') cur = conn.cursor() # insert操作 insert_sql = 'INSERT INTO t(xxx,XXX) VALUES(?,?);' cur.execute(insert_sql,(xxx,XXX)) conn.commit() # update操作 update_sql = 'UPDATE t SET xxx=? WHERE XXX=?;' cur.execute(update_sql,(xxx,XXX)) conn.commit() # delete操作 delete_sql = 'DELETE FROM t WHERE XXX=?;' cur.execute(delete_sql,(XXX,)) conn.commit() # select操作 select_sql = 'SELECT * FROM t;' cur.excute(select_sql) conn.commit() con.close()
-
访问MySQL数据库
-
简述
PyMySQL是运行在Python3.x版本中的用于连接MySQL服务器的一个库,非内置,需安装
-
安装驱动
pip install PyMySQL利用Python终端进行安装,需在Python目录下的Scripts目录进行操作命令
-
数据库连接
# 引入pymysql库 import pymysql # 方法一:进行连接 db = pymysql.connect(host="localhost",port=3306,user="root",password="?",database="?",charset="utf8") # 关闭连接 db.close # 方法二:with语句进行连接 with pymysql.connect(host="localhost",port=3306,user="root",password="?", database="?",charset="utf8") as db:with语句进行管理数据库资源无需关闭
常见错误有提前结束with而又继续调用SQL语句导致报错。
直接连接数据库时要保证此数据库存在。
-
操作
# create database操作 db = pymysql.connect(host='localhost', user='root', password='?') cur = db.cursor db_sql = 'create database db_name ()' cur.execute(db_sql) # create table操作 table_sql = 'create table t_name ()' cur.execute(table_sql) # insert 操作(参数化插入) insert_sql = 'insert into t_name (%s[,…,%s])' cur.execute(insert_sql,'tuple') # tuple=(?,[?,?]) # insert 操作(批量化插入) # 方式一 lst = [(,),(,)] insert_sql = 'insert into t_name (%s[,…,%s])' cur.executemany(insert_sql,lst) # 方式二 for item in lst: cur.execute(insert_sql,item) # select 操作 select_sql = 'select * from t_name' cur.execute(select_sql) # 显示第一条记录 data = cur.fetchone() print(data) # 显示第一条到第n条记录 dataN = cur.fetchmany(n) print(dataN) # 显示所有记录 dataAll = cur.fetchall() print(dataAll) # update 操作 update_sql = 'update t_name set ?=? where ?=?' cur.execute(update_sql) # delete 操作 delete_sql = 'delete from t_name where ?=?' cur.execute(delete_sql)上述语句均可无需借助游标进行传递SQL语句,可直接由数据库执行语句,即
db.execute(sql),但游标对象更灵活一些。MySQL不支持具名占位符,所以使用
%s作为占位符,不考虑数据类型pymysql.connect.execute(sql,tuple)其中第二参数必须以元组类型进行传递,顺序必须一一对应。在查询过程中,游标对象类似一个记录指针,每读取一条记录,指针都是后移,所以同函数内对应的
fetchone()、fetchmany()、fetchall()对应的数据也是不一致的。
数据文件操作
读写Excel文件
-
准备工作
安装两个需要的包
pip install xlrdpip install xlwt -
读取Excel文件操作
# 引入xlrd库,不支持xlsx格式文件,仅支持xls格式 import xlrd # 打开表格文件,即xxx工作簿 table = xlrd.open_workbook('xxx.xls') # 对应的表格,即yyy工作表(两种方式,根据索引或表名) sheetN = table.sheet_by_index(n)||table.sheets()[n] # table.sheets()返回所有表的列表 sheetY = table.sheet_by_name('yyy') # 获取表中总行数和总列数 rows = sheet.nrows # 总行数 cols = sheet.ncols # 总列数 # 获取某行或某列的值,值以列表方式展示 rowN = sheet.row_values(n) # 第n-1行的行数据 colN = sheet.col_values(n) # 第n-1列的列数据 # 循环遍历行或列数据 for r in range(rows): print(sheet.row_value(r)) for c in range(cols): print(sheet.col_value(c)) # 获取某一单元格的数据 cell_YX = sheet.cell(x,y).value # 以单元格形式获取第x-1行第y-1列的单元格数据 cell_XY = sheet.row(x)[y].value # 以行列索引形式获取第y-1行第x-1列的单元格数据 cell_XY = sheet.row(y)[x].value # 以行列索引形式获取第y-1行第x-1列的单元格数据 -
写入Excel文件操作
-
基本写入操作
# 引入xlwt库,依旧不支持xlsx格式文件,仅支持xls格式 import xlwt # 创建一个workbook工作簿,并设置编码格式 workbook = xlwt.Workbook(encoding="utf8") # 创建一个worksheet工作表,并命名为yyy worksheet = workbook.add_sheet('yyy') # 写入对应单元格的数据,以x-1行、y-1列、demo值的格式写入 worksheet.write(x,y,label="demo") # 将上述工作簿保存为xxx.xls文件 workbook.save('xxx.xls') -
高阶写入操作
# 引入xlwt库,依旧不支持xlsx格式文件,仅支持xls格式 import xlwt # 创建一个workbook工作簿,并设置编码格式 workbook = xlwt.Workbook(encoding="utf8") # 创建一个worksheet工作表,并命名为yyy worksheet = workbook.add_sheet('yyy') # 对应格式化写入,包括样式,字体等 style = xlwt.XFStyle() # 初始化样式 #为样式创立字体,设置字体类型;开启字体黑体;开启字体下划线;开启字体斜体;定义样式 font = xlwt.Font() font.name = '' font.bold = True font.underline = True font.italic = True style.font = font worksheet.write(x,y,'Contents',style) # 写入日期类型 style = xlwt.XFStyle() # 初始化样式 # 写入日期数据 style.num_format_str = 'M/D/YY' worksheet.write(x,y,datetime.datetime.now(),style) # 写入公式 worksheet.write(x,y,xlwt.Formula('SUM(A1,B1)')) # 写入超链接 worksheet.write(x,y,xlwt.Formula('HYPERLINK("http://www.xxx.com");"xxx"')) # 设置单元格格式 worksheet.col(y).width = n # 设置第y-1列的宽度 worksheet.row(x).height = n # 设置第x-1行的高度 worksheet.write(x,y,'Contents') # 将上述工作簿保存为xxx.xls文件 workbook.save('xxx.xls')
-
读写CSV文件
详参python基础
读写JSON文件
-
JSON简介
JavaScript Object Notation,即JavaScript对象表示法,简称JSON
是一种轻量级的数据交换格式,是一个序列化的对象或数组。
由六个构造字符组成:
"[","]","{","}",":",","JSON格式与JavaScript对象文字表示格式类似。
JSON对象由
{}起来的、逗号分隔的成员组成,成员是字符串键和值有逗号分隔的键值对组成JSON的值可以是
数字、使用双引号的字符串、JavaScript数组、子JSON的对象或"false"、"null"、"true"中的一个组成,英文值必须使用小写 -
JSON基本操作
# 引入JSON模块 import json jsonD = { "sNo": "1", "sName": "张三", "age": 20, "course": ["python", "专业外语", "Java"], "score": {"python": 89, "专业外语": 90, "Java": 79}, "married": "false" } # 序列化过程,将json对象序列化为Python的字符串,类似将字典转换为字符串。 # 参数列表: # sort_keys=True 排序(没有错误的键) # indent=整数,缩进字符数 # ensure_ascii=False:不用ASCII码形式显示; # skipkeys=True:当键有错误(不是字符串),忽略错误,不显示 # separators('',''):换行位置 s = json.dumps(jsonD) print(s) # 反序列化过程,用于将str类型的数据转成dict类型 jsonObj=json.loads(s) print(jsonObj) try: # 对象序列化过程,将json对象序列化为Python的字符串,类似将字典转换为字符串,还需写入json文件 json.dump(s,fw) with open("jsonFile.json","w") as fw: json.dump(s,fw) print("ok") # 反序列化过程,读取json文件,并转换为字符串 with open("jsonFile.json","r") as fr: json.load() except: print("error")
网络爬虫与信息提取
爬虫
简介
通过一个程序,根据url进行爬取网页,获取有用信息,即爬取互联网上的信息;使用程序模拟浏览器选罢法服务器发送请求,获取响应信息的过程,即爬虫爬取数据与手动获取数据途径和流程很相似,在数据挖掘获取数据之后,对于数据进行筛选,得到有用的信息。
核心
爬取整个网页,包含网页中所有内容;将网页中需要的数据进行解析;解决爬虫和反爬虫之间的核心。
分类
-
通用爬虫
-
简述
将互联网上的网页下载到本地,形成一个互联网内容的镜像备份,是搜索引擎的重要部分;
实例:百度、360、Google、sougou等搜索引擎
-
流程
抓取网页–>数据存储–>数据预处理–>提供检索服务及网络排名
-
局限性
通用爬虫搜索引擎所返回的结果是网页,对于用户是无用的;
搜索引擎无法针对具体用户提供个性化的搜索结果
搜索引擎无法对图片、音频、视频等多媒体数据检索
因搜索引擎基于关键字检索,无法准确理解用户具体需求
-
-
聚焦爬虫
-
简述
“面向特定主题需求”的爬虫程序,在实施网页抓取时会针对内容进行处理和筛选,满足抓取需求
-
设计思路
确定要爬取的url–>模拟浏览器通过http协议访问url,获取服务器返回的html代码–>解析html字符串(根据一定规则提取需要的数据)
-
反爬手段
-
User-Agent(用户代理)
使得服务器能够识别客户使用的操作系统、版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
-
代理IP
-
验证码访问
-
动态加载网页
网页返回的是js数据,非真实数据,使用selenium驱动真实的浏览器发送请求
-
数据加密
分析js代码
-
-
请求与响应
-
服务器
服务器中前端(用于数据展示)、中间层(用于数据处理)和数据库(用于数据存储)
-
请求与响应
用户通过浏览器发送请求到服务器,由中间层进行请求解析,在数据库中拿到用户所需的数据,再通过前端网页把数据展现给用户,此过程称为响应
URL
-
统一资源定位符
用于完整描述Internet上网页和其他资源的地址的一种标识方法
-
url内容
http / https :// www.baidu.com / 80/443 / s? / wd = # scheme + host + port + path + query-string + anchorscheme–协议,其中有http、https、ftphost–服务器的ip地址或域名port–端口号(服务器默认为80)path–访问资源路径query-string–参数,发送给http服务器的数据anchor–锚 跳转到网页的制作锚点位置,退出后再次进入,会自定位到上次位置
GET请求和POST请求
-
GET请求
从服务器上获取的数据。GET请求参数都显示在浏览器网址上,HTTP服务器根据请求所包含URL中的参数来产生响应内容,即GET请求的参数是URL的一部分
-
post请求
向服务器传送的数据。POST请求参数在请求体中,消息长度没有限制而以隐式方式进行发送,通常用来向HTTP服务器提交量较大的数据(如请求中包含许多参数,上传文件等),请求的参数包含在Content-Type消息头中指明消息体的媒体类型和编码。
头部信息
-
Host
主机端口号;对应与网站URL的web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常是数据URL的一部分
-
Connection
连接类型;表示客户端与服务器的连接类型
-
Client
发起一个包含Connection:keep-alive请求
-
Server
- 如果Server支持keep-alive,回复一个包含Connection:keep-alive的响应,同时不关闭连接
- 如果Server不支持keep-alive,回复一个包含Connection:close的响应,同时不关闭连接
-
keep-alive
如果Client收到包含Connection:keep-alive的响应,想同一个连接发送下一个请求,直到已发送主动关闭连接
keep-alive在很多情况下呢个重用连接,减少资源消耗,锁住单响应时间,不需要每次都去请求建立连接
-
-
Upgrade-Insecure-Requests
升级为安全请求;在加载HTTP资源会自动替换HTTPS请求,让浏览器不再显示HTTPS页面的HTTP请求警告
-
Cookie
保护用户浏览网页的记录(加密的用户名和密码等信息)
-
User-Agent
浏览器名称或手机型号的信息
数据挖掘
urllib
-
简介
-
基本使用
import urllib.request url = "http://www.baidu.com" # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) print(type(response)) content = response.read().decode('utf-8') print(content) # 返回n个字节 content = response.read(n) print(content) # 读取一行 content = response.readline() print(content) # 读取一行多行 content = response.readlines() print(content) # 返回状态码 print(response.getcode()) # 返回url地址 print(response.geturl()) # 获取状态信息即响应头 print(response.getheaders()) # 一个类型 'http.client.HTTPResponse' # 六个方法 read readline readlines getcode geturl getheaders urllib.request.urlretrieve() # 可下载请求的网页 # 可下载请求的图片 # 可下载请求的视频解码与编码
-
解码
字节流–>字符串 解码 decode
-
编码
字符串–>字节流 编码 encode
-
-
UA
User-Agent 用户代理,是一个特殊字符串头,使得服务器能够识别客户使用的操作系统、版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
import urllib.request url = '' header = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55" } request = urllib.request.Request(url=url,headers=header) response = urllib.request.urlopn(request) -
编解码
-
get请求方法
urllib.parse.quote()import urllib.parse name = urllib.parse.quote('周杰伦')urllib.parse.urlencode()import urllib.parse data={ 'wd':'周杰伦', 'sex':'男', } info = urllib.parse.urlencode(data) -
post请求方法
-
语法
-
格式
import urllib.parse import urllib.request url = "https://fanyi.baidu.com/sug" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55" } data = { 'kw': 'spider' } data = urllib.parse.urlencode(data).encode('utf-8') request = urllib.request.Request(url=url, data=data, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8') print(content)post请求方式的参数必须编码,编码后还需要调用
encode()方法,即data = urllib.parse.urlencode(data).encode('utf-8')post请求方式的参数必须放在请求对象定制的方法中,即
request = urllib.request.Request(url=url, data=data, headers=headers)
-
-
编解码的演变
ASCII编码、GB2312编码、Unicode统一编码
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号, 这个编码表被称为
ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突, 所以,中国制定了
GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里, 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。 Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。 现代操作系统和大多数编程语言都直接支持Unicode。
-
-
Ajax的get请求
-
Ajax的post请求
-
异常
URLError\HTTPError- HTTPError类是URLError类的子类
import urllib.error.HTTPError或者import urllib.error.URLError- http错误是针对浏览器无法连接到服务器而增加出来的错误提示,引导并告诉浏览者该页面的问题
- 通过urllib发送请求时,可能会发送失败,通过捕获
try-except异常使代码更健壮
-
Handler处理器
定制更高级的请求头
import urllib.request url = 'http://www.baidu.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.39' } request = urllib.request.Request(url=url, headers=headers) handler = urllib.request.HTTPHandler() opener = urllib.request.build_opener(handler) response = opener.open(request) content = response.read().decode('utf-8') print(content) -
代理及代理池
-
常用功能
突破自身IP访问限制,访问国外站点。
访问一些单位或团体内部资源
提高访问速度
隐藏真实IP
-
代码配置代理
import urllib.request url = 'http://www.baidu.com/s?wd=ip' headers = { 'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.169Safari / 537.36' } # 创建Reuqest对象 request = urllib.request.Request(url=url,headers=headers) proxies = { 'http':'117.141.155.244:53281' } # 创建ProxyHandler对象 handler = urllib.request.ProxyHandler(proxies=proxies) # 用handler对象创建opener对象 opener = urllib.request.build_opener(handler) # 使用opener.open函数发送请求 response = opener.open(request) content = response.read().decode('utf‐8') with open('daili.html','w',encoding='utf‐8')as fp: fp.write(content)
-
-
cookie登录
requests
-
简介
requests模块是基于Python内置的urllib模块编写而成的,且比之使用简单、方便,但不是Python内置的库。官方文档:Requests: — Requests 2.18.1 文档
快速上手:
-
requests安装与使用
安装requests
pip install requests使用requests,即导入模块
import requests -
基本使用
import requests url = 'http://www.baidu.com' response = requests.get(url=url) print(type(response)) # 设置响应的编码格式 response.encoding = 'utf-8' # 返回网页编码,以字符串形式 print(response.text) # 返回url地址 print(response.url) # 返回网页编码,以二进制的形式返回 print(response.content) # 返回响应的状态码 print(response.status_code) # 返回响应头 print(response.headers)类型为
'requests.models.Response'response.text–获取网页源码response.encoding–访问或定制编码方式response.url–获取请求的urlresponse.content–响应的字节类型response.status_code–响应的状态码response.headers–响应的头部信息 -
添加请求头(请求对象定制)
-
UA
User-Agent 用户代理,是一个特殊字符串头,使得服务器能够识别客户使用的操作系统、版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
import requests url = "" word = {'word':''} headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55"} r = requests.get(url,headers=headers,params=word)
-
-
发送GET请求
# encoding=uft-8 import requests url = "" response = requests.get(url).text # 或 response = requests.request('get',url).text-
返回类型选择
-
get().text–以encoding解析返回内容,即字符串方式的响应体,会自动根据响应头部的字符编码进行解码 -
get().content–以二进制(字节)形式返回,即字节方式的响应体,会自动解码gzip和deflate压缩,通常用来保存图片等二进制文件,也可通过deocde()设置编码方式返回对应的编码结果。
-
- 请求携带参数
- 接受params参数,但格式必须为字典,将请求参数传入
- 可以携带HTTP请求和响应的信息,诸如
response.cookies、response.ip、response.header、response.url、response.ok(查看返回码是否为’200 OK’)、response.status_code(查看返回HTTP的状态码)、response.reason(查看HTTP状态码文本原因)
- get请求参数会自动拼接到url后面,请求后得到相应的请求结果。
- requests对于特定类型的响应较方便,通过
json()方法即可直接获取json序列化结果 - 对比urllib:
- 参数使用params传递
- 参数无需urlencode编码
- 不需要请求对象定制
- 请求资源路径中的
?可加可不加
-
-
代理ip
为避免被反爬虫机制(判断请求来源的ip,重复多重访问会被屏蔽)阻止,需要采用代理ip进行爬取;
突破自身IP访问;可以访问一些单位或团体的内部资源;提高访问速度;隐藏真实IP
import requests url = "" proxys=[ {"http":"110.189.152.86:6023"}, {"http":"101.248.64.82:6023"}, {"http":"115.171.85.141:6023"} {"http":"113.236.192.79:6023"}, {"http":"223.100.176.122:6023"}, {"http":""} ] for proxy in proxys: try: response = requests.get(url,proxies=proxy) except: pass定义代理ip的列表字典,需要遵循协议充当字典的键,而值为”-url:端口号”
找到ip存活时间较长,获取其ip和端口
-
处理post请求
import requests url = "" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.39' } data={ 'kw':'eye' } response = requests.post(url=url,headers=headers,data=data).text # 或 response = requests.request('post',url).textget和post区别:- get请求的参数名字是params post请求的参数的名字是data
- 请求资源路径后面可以不加
? - 不需要手动编解码
- 不需要做请求对象的定制
- 对比
urllib.post:- 参数使用data传递
- 参数无需urlencode编码
- 不需要请求对象定制
- 请求资源路径中的
?可加可不加
-
获取响应的cookie
-
利用session实现登录验证
数据清洗
xPath
-
解析简述
提前安装xpath库
安装lxml库
pip install lxml -
基本使用
from lxml import etree # 解析 本地文件 etree.parse() html_tree = etree.parse('xx.html') # 解析 服务器响应文件 etree.HTML() html_tree = etree.HTML(response.read().decode('utf-8')) html_tree.xpath(xpath路径)基本语法
- 路径查询:
//:查找所有子孙节点,不考虑层级关系;/:找直接子节点;- 谓词查询:
//div[@id]//div[@id="maincontent"]- 属性查询:
//@class- 模糊查询:
//div[contains(@id,"he")]//div[starts-with(@id,"he")]- 内容查询
//div/h1/text()- 路径查询
//div[@id="head" and @class="s_down"]//title | //price(必须通过标签进行或) -
xpath_helper浏览器插件的辅助
RegularExpress
-
简述
正则表达式是一种文本模式,包括普通字符(a-z之间的字母)和特殊字符(元字符)。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
-
基本使用
# 导入re模块 import re # 根据一个模式字符串r'xxx'和可选标志参数flags生成一个正则表达式对象 re.compile(r'xxx',flags=0) # flags默认为0,可设置为以下内容: # re.I匹配时不区分大小写; # re.M多行模式; # re.S '.'包含换行符在内的任意字符; # re.U表示特殊字符集`\w,\W,\b,\B,\d,\D,\s,\S`依赖于Unicode库; # re.L表示特殊字符集`\w,\W,\b,\B,\s,\S`依赖于当前环境; # re.X忽略空格和'#'后面的注释,增加可读性 # 对字符串string的起始位置匹配 # 匹配成功返回一个Match对象;失败返回None; re.match(r'xxx',string,flags=0) re.compile(r'xxx',flags=0).match(r'xxx',flags=0) # 对整个字符串进行扫描并返回第一个匹配结果 # 匹配成功返回一个Match对象;失败返回None; re.search(r'xxx',string,flags=0) Match.group(num=0) Match.groups() Match.start(group=0) Match.end(group=0) # 对字符串string的起始位置匹配,找到所有与正则表达式匹配的字符串 # 匹配成功返回匹配字符元组的列表;失败返回空列表; re.findall(r'xxx',string,flags=0) # 对字符串string的起始位置匹配,找到所有与正则表达式匹配的字符串 # 匹配成功返回匹配字符元组的可迭代对象;失败返回对象; re.finditer(r'xxx',string,flags=0) # 将字符串string按照与正则表达式匹配的子串分割 re.split(r'xxx',string,maxsplit=0,flags=0) # maxsplit是最大分割次数,默认0表示不限分割次数 # 替换字符串string与正则表达式匹配的子串 re.sub(r'xxx',replaceString,string,count=0,flags=0) # replaceString表示将匹配子串替换成的字符串; # string表示待做替换操作的字符串; # 替换字符串string与正则表达式匹配的子串,返回匹配子串得到的新字符串和替换次数组成的元组 re.subn(r'xxx',replaceString,string,count=0,flags=0) -
基础语法
字符 描述 例子 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。‘\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” 而 “(” 则匹配 “(”。 ^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 $ 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性, 也匹配 ‘\n’ 或 ‘\r’ 之前的位置 * 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 + 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 {n} n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 {n,} n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 {n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 . 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像”(.|\n)“的模式。 (pattern) 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(’ 或 ‘)’。 (?:pattern) 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 (?=pattern) 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配”Windows2000″中的”Windows”,但不能匹配”Windows3.1″中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (?!pattern) 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如”Windows(?!95|98|NT|2000)“能匹配”Windows3.1″中的”Windows”,但不能匹配”Windows2000″中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (?<=pattern) 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,”`(?<=95 98 (?<!pattern) 反向否定预查,与正向否定预查类似,只是方向相反。例如”`(?<!95 98 x|y 匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。 [xyz] 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 [^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]'可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。[a-z] 字符范围。匹配指定范围内的任意字符。例如,‘[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 [^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如, '[^a-z]'可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。\b 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 \B 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 \cx 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 \d 匹配一个数字字符。等价于 [0-9]。 \D 匹配一个非数字字符。等价于 [^0-9]\f 匹配一个换页符。等价于 \x0c 和 \cL。 \n 匹配一个换行符。等价于 \x0a 和 \cJ。 \r 匹配一个回车符。等价于 \x0d 和 \cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 \S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。\t 匹配一个制表符。等价于 \x09 和 \cI。 \v 匹配一个垂直制表符。等价于 \x0b 和 \cK。 \w 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 \W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'\xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,‘\x41’ 匹配 “A”。‘\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 \num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,‘(.)\1’ 匹配两个连续的相同字符。 \n 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 \nm 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 \nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 \un 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。
JsonPath
-
基本使用
pip下载
pip install jsonpath使用
import jsonpath obj = json.load(open('./files/store.json', 'r', encoding='utf-8')) author_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
BeautifulSoup
-
简述
简称
bs4,和lxml一样,是一个html的解析器,主要功能是解析和提取数据。接口设计人性化,使用方便;但效率没有lxml高
-
基本使用
安装
pip install bs4基本使用
from bs4 import BeautifulSoup # 创建对象 soup = BeautifulSoup(response.read().decode(),'lxml') # 解析服务器响应的文件而生成对象 soup = BeautifulSoup(open(''),'lxml') # 解析本地文件而生成对象默认打开文件的编码格式为
gbk,需要指定编码格式
Scrapy框架
-
简介
scrapy是一个为了爬取网站资源,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列操作的程序中。
-
安装
pip install scrapy -
基本使用
-
创建爬虫项目
scrapy startproject 项目名称 # 项目名称不允许以数字开头,也不能包含中文 -
创建爬虫文件
# 进入爬虫文件夹 cd 项目名称\项目名称\spiders # 创建爬虫文件 scrapy genspider 爬虫名称 爬取的网页 # URL地址最好去掉https://或http://,去掉结尾的/,保证域名即可 -
编写爬虫文件
爬数据–>取数据
-
运行爬虫代码
# 直接运行查看提取信息结果 scrapy crawl 爬虫名称 # 查看提取信息结果的同时把信息保存在json文件中 scrapy crawl 爬虫名称 -o jsonName.json -
编写启动模块,
run.py创建在项目根目录下from scrapy import cmdline cmdline.execute("scrapy crawl 爬虫名称".split())此步骤可选做,但必须保证
run.py文件在项目根目录下
-
项目组成分析
└─项目文件夹 ├─ 项目文件夹 │ ├─ __pycache__文件夹 │ ├─ spiders文件夹 │ │ ├─ __pycache__文件夹 │ │ ├─ __init__.py │ │ └─ spider.py 自行创建的爬虫文件,实现爬虫核心功能的文件 │ ├─ __init__.py │ ├─ items.py 定义数据结构的地方,继承自scrapy.Item的类 │ ├─ middlewares.py 中间件文件,编写代理 │ ├─ pipelines.py 管道文件,内含一个用于处理下载数据后续处理的类,默认优先级为300,值越小优先级越高(1-1000) │ └─ settings.py 配置文件,含robots协议,User-Agent定义 │ └─ scrapy.cfg -
response的属性和方法
response.text–返回响应的字符串response.body–返回响应的二进制数据response.xpath–返回xpath语法解析response中的内容response.extract()–提取seletor对象的data属性值response.extract_first()–提取seletor列表的第一个数据
-
scrapy架构组成
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等;自动运行,无需关注,会自动组织所有的请求对象,分发给下载器Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理;Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方;一般做清理HTML数据、验证爬取的数据(检查item包含某些字段)、查重(并丢弃)、将爬取结果保存到数据库中等操作Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
-
scrapy工作原理
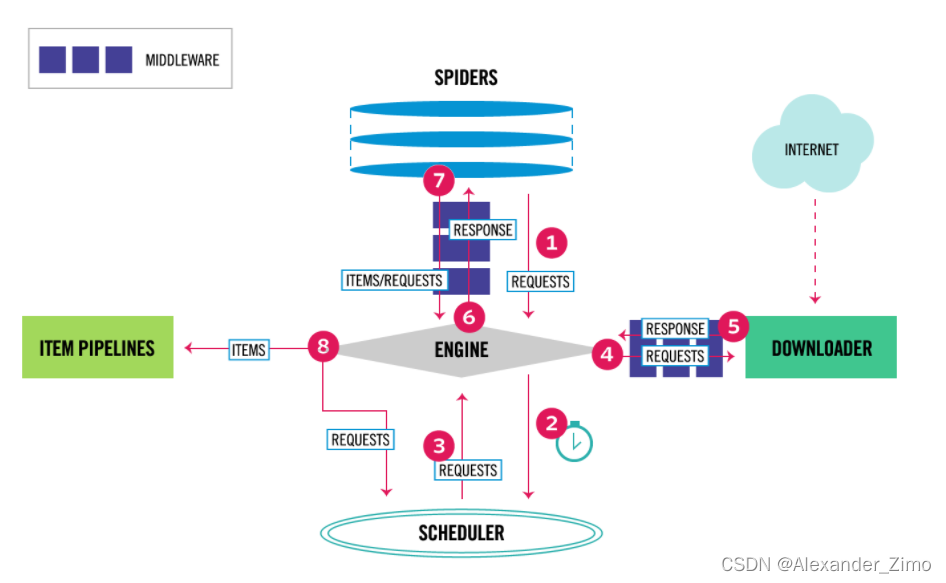
过程:
- Engine向Spider要url
- Engine将要爬取的url发送给Scheduler
- Scheduler将url生成requests对象放入到指定队列中,同时从队列中出队一个请求
- Engine将requests交给Downloader进行处理,Downloader发送requests请求获取互联网数据
- Downloader将数据返回给Engine
- Engine将数据再次给到Spider,Spider通过xpath解析数据,得到数据或url
- Spider将数据或url给到Engine
- Engine判断该数据是url还是数据,数据交给Item Pipeline处理,url交给Scheduler处理
-
-
scrapy shell工具
-
简介
即Scrapy终端,一个交互终端,供在未启动spider情况下尝试及调试爬虫代码。
用于测试提取数据的代码,即测试xpath或css表达式,查看其工作方式及从爬取的网页中提取的数据;
在编写spider时,改终端提供了交互性测试表达式代码功能,免去每次修改spider而运行的步骤
-
安装
-
基本使用
-
-
yield
-
简介
带有yield的函数不再是一个普通函数,而是一个迭代生成器
generator,可用于迭代yield类似return关键字,迭代一次遇到yield时就返回yield后面的值
下一次迭代时,从上一次迭代遇到的yield后面的代码开始执行
yield只能用在函数中
yield关键字使得他所在的函数返回一个生成器(generator)
两种方法对生成器变量访问:
(1) for –in 循环
(2) next(generator): try-catch
-
简要理解
yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始
-
-
日志信息
-
日志级别
CRITICAL–严重错误
ERROR–一般错误
WARNING–警告
INFO–一般信息
DEBUG–调试信息
默认的日志等级为DEBUG,只要出现DEBUG或者DEBUG以上等级的日志日志就会打印
-
setting.py文件设置默认的日志等级为DEBUG,会显示上面所有的信息;在配置文件中,可以指定日志的级别
LOG_LEVEL=''设置日志显示级别、LOG_FILE=''就屏幕中的显示信息记录到文件中,屏幕则不显示,文件后缀为.log
-
-
post请求
-
重写
start_requests()方法def start_requests(self): -
start_requests()返回值scrapy.FormRequest(url=url,headers=headers,callback=self.parse_item,formdata=data)url–要发送的post地址
headers–定制的头部信息
callback–回调函数
formdata–post携带的数据,是一个字典
-
-
代理
-
到settings.py中,打开一个选项
DOWNLOADER_MIDDLEWARES = { 'postproject.middlewares.Proxy': 543, } -
到middlewares.py中写代码
def process_request(self, request, spider): request.meta['proxy'] = 'https://113.68.202.10:9999' return None
-
-
CrawlSpider
-
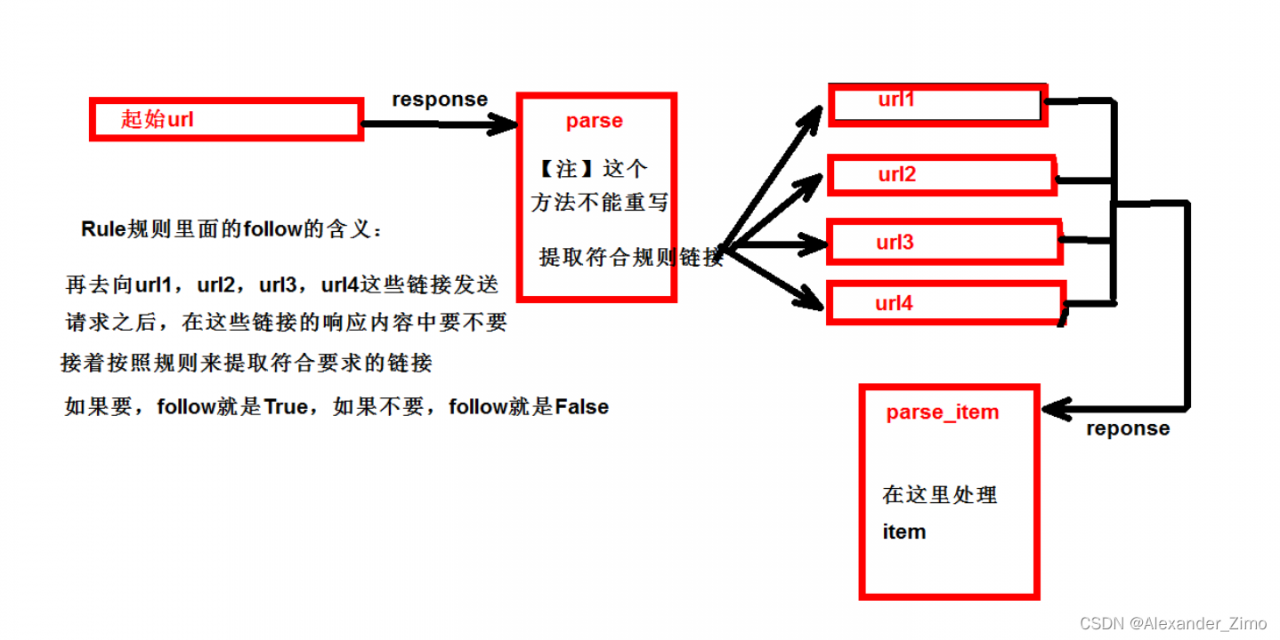
简介
继承自scrapy.Spider;CrawlSpider可以定义规则,再解析html内容,可以根据连接规则提取指定的链接,然后再向这些链接发送请求
如果需要跟进链接的需求(即,爬取了网页之后再提取链接后再次爬取),使用CrawlSpider是很适用的
-
基本使用
-
创建项目
# 创建项目 scrapy startproject 项目名称 # 进入spiders路径 cd 项目名称\项目名称\spiders # 创建爬虫 scrapy genspider -t crawl 爬虫名称 爬取的网页callback智能写函数名字符串,即
callback='parse_item'在基本的spider中,如果重新发送请求,
callback=self.parse_item;follow=true表示是否跟进,就是按照提取连接规则进行提取 -
提取链接
链接提取器
from scrapy.linketractors import LinkExtractor scrapy.linketractors.LinkExtractor( allow = (), # 正则表达式,提取符合正则的链接 deny = (), # (不用)正则表达式,不提取符合正则的链接 allow_domains = (), # (不用)允许的域名 deny_domains = (), # (不用)不允许的域名 restrict_xpaths = (),# xpath,提取符合xpath规则的链接 restrict_css = (), # 提取符合选择器规则的链接 ) -
模拟使用
# 正则表达式用法 link = LinkExtractor(allow = r'list_23_\d+\.html') # xpath用法 link = LinkExtractor(restrict_xpaths = r'//div[@class="x"]') # css用法 link = LinkExtractor(restrict_css = r'.x') -
提取连接
link.extract_links(response)
-
-
运行原理
-
Selenium
-
简述
Selenium是一个用于Web应用程序测试的工具。
Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动 真实浏览器完成测试。
selenium也是支持无界面浏览器操作的。
-
基本使用
from selenium import webdriver path = 'msedgedriver.exe' browser = webdriver.Edge(path) url = 'https://www.jd.com' browser.get(url) content = browser.page_source print(content) -
元素定位
自动化要做的事模拟鼠标和键盘来操作这些元素进行点击、输入等操作,而需要定位这些元素
find_element_by_idfind_elements_by_namefind_elements_by_xpathfind_elements_by_tag_namefind_elements_by_css_selectorfind_elements_by_link_text
-
元素信息访问
- 获取元素的属性
.get_attribute('class') - 获取元素文本
.text - 获取id
.id - 获取标签名
.tag_name
- 获取元素的属性
-
Phantomjs
-
简介
是一个无界面的浏览器;支持页面元素查找,js执行等;不进行css和gui渲染,运行效率更高。
-
基本使用
from selenium import webdriver # 获取Phantomjs.exe文件路径 path path = 'Phantomjs.exe' browser = webdriver.PhantomJS(path) url = 'https://www.jd.com' browser.get(url) content = browser.page_source print(content)
-
-
Chrome handless
-
简介
Chrome-headless 模式,Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以在不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
-
基本使用
pip install msedge-selenium-tools seleniumfrom msedge.selenium_tools import Edge, EdgeOptions options = EdgeOptions() options.use_chromium = True options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" options.add_argument("headless") options.add_argument("disable-gpu") browser = Edge(options = options) browser.get('https://www.google.com') browser.save_screenshot('google.png')
-