至少有K个重复字符的最长子串
找到给定字符串(由小写字符组成)中的最长子串 T , 要求 T 中的每一字符出现次数都不少于 k 。输出 T 的长度。
示例 1:
输入:
s = “aaabb”, k = 3
输出:
3
最长子串为 “aaa” ,其中 ‘a’ 重复了 3 次。
示例 2:
输入:
s = “ababbc”, k = 2
输出:
5
最长子串为 “ababb” ,其中 ‘a’ 重复了 2 次, ‘b’ 重复了 3 次。
解法
看题目有点像用动态规划的方法来做,但是并没有好方法,而是用递归。
首先判断字符串的长度,若小于k,直接返回0。然后对字符串中的每一个字符依次判断其出现次数,若次数小于k,则在不包括该字符的子串中继续递归判断,最后返回各个符合条件子串长度的最大值即可。
代码非常的Python化
class Solution(object):
def longestSubstring(self, s, k):
"""
:type s: str
:type k: int
:rtype: int
"""
if len(s) < k:
return 0
for x in set(s):
if s.count(x) < k:
return max(self.longestSubstring(sub, k) for sub in s.split(x))
return len(s)
爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
- 1 阶 + 1 阶
- 2 阶
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
- 1 阶 + 1 阶 + 1 阶
- 1 阶 + 2 阶
- 2 阶 + 1 阶
class Solution(object):
def climbStairs(self, n, dic={}):
"""
:type n: int
:rtype: int
"""
if n in dic:
return dic[n]
if n in [0, 1, 2, 3]:
return n
res = self.climbStairs(n - 1, dic) + self.climbStairs(n - 2, dic)
dic[n] = res
return res
第K个语法符号
在第一行我们写上一个 0。接下来的每一行,将前一行中的0替换为01,1替换为10。
给定行数 N 和序数 K,返回第 N 行中第 K个字符。(K从1开始)
例子:
输入: N = 1, K = 1
输出: 0
输入: N = 2, K = 1
输出: 0
输入: N = 2, K = 2
输出: 1
输入: N = 4, K = 5
输出: 1
解释:
第一行: 0
第二行: 01
第三行: 0110
第四行: 01101001
注意:
N 的范围 [1, 30].
K 的范围 [1, 2^(N-1)].
解法
递归法:第N行的K位是根据第N-1行的M位得到的。
M = (K + 1)/2,然而再判断是0还是1即可
class Solution(object):
def kthGrammar(self, N, K):
"""
:type N: int
:type K: int
:rtype: int
"""
if N == 1:
return 0
if K == 0:
return 0
if K % 2 == 0:
x = K // 2
y = 1
else:
x = K // 2 + 1
y = 0
last = self.kthGrammar(N - 1, x)
if last == 0:
z = [0, 1]
else:
z = [1, 0]
return z[y]
从二维矩阵中查找是否存在某个字符串s
# 二维数组,随机字母,给定字符串,判断是否在二维数组中。
dx = [0, 0, 1, -1]
dy = [1, -1, 0, 0]
def dfs(nums, s, i, j, k):
if i < 0 or j < 0 or i >= len(nums) or j >= len(nums[0]):
return False
if nums[i][j] == s[k]:
tmp = nums[i][j]
nums[i][j] = '*'
if k == len(s) - 1:
return True
else:
for m in range(4):
x, y = i + dx[m], j + dy[m]
if dfs(nums, s, x, y, k + 1):
return True
nums[i][j] = tmp
return False
def find(nums, s):
for i in range(len(nums)):
for j in range(len(nums[0])):
if dfs(nums, s, i, j, 0):
return True
return False
机器人的运动范围
地上有一个m行和n列的方格。一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于k的格子。 例如,当k为18时,机器人能够进入方格(35,37),因为3+5+3+7 = 18。但是,它不能进入方格(35,38),因为3+5+3+8 = 19。请问该机器人能够达到多少个格子?
解法
- BFS:
- DFS:注意对范围的判断
# -*- coding:utf-8 -*-
class Solution:
def __init__(self):
self.res = 0
self.vis = []
self.dx = [-1, 0, 1, 0]
self.dy = [0, -1, 0, 1]
def get_num(self, num):
cnt = 0
while num > 0:
cnt += num % 10
num /= 10
return cnt
def movingCount(self, threshold, rows, cols, x = 0, y = 0):
# write code here
if threshold <= 0:
return 0
if x < 0 or x >= rows or y < 0 or y >= cols or (x, y) in self.vis:
return
if self.get_num(x) + self.get_num(y) > threshold:
return
self.res += 1
self.vis.append((x, y))
for i in range(4):
self.movingCount(threshold, rows, cols, x + self.dx[i], y + self.dy[i])
return self.res
子树中标签相同的节点数
给你一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n – 1 的 n 个节点组成,且恰好有 n – 1 条 edges 。树的根节点为节点 0 ,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点的标签就是 labels[i] )
边数组 edges 以 edges[i] = [ai, bi] 的形式给出,该格式表示节点 ai 和 bi 之间存在一条边。
返回一个大小为 n 的数组,其中 ans[i] 表示第 i 个节点的子树中与节点 i 标签相同的节点数。
树 T 中的子树是由 T 中的某个节点及其所有后代节点组成的树。
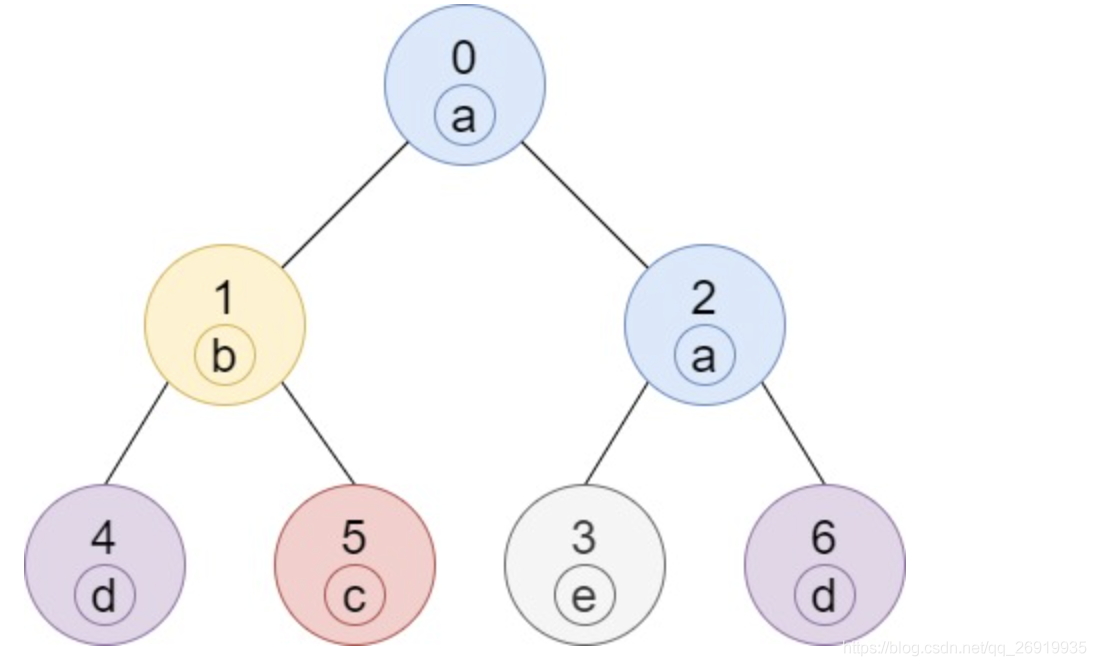
输入:n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = “abaedcd”
输出:[2,1,1,1,1,1,1]
解释:节点 0 的标签为 ‘a’ ,以 ‘a’ 为根节点的子树中,节点 2 的标签也是 ‘a’ ,因此答案为 2 。注意树中的每个节点都是这棵子树的一部分。
节点 1 的标签为 ‘b’ ,节点 1 的子树包含节点 1、4 和 5,但是节点 4、5 的标签与节点 1 不同,故而答案为 1(即,该节点本身)。
提示:
1 <= n <= 10^5
edges.length == n – 1
edges[i].length == 2
0 <= ai, bi < n
ai != bi
labels.length == n
labels 仅由小写英文字母组成
解法
用dfs递归的记录每个节点子树上的标签都有多少个,然后返回的时候加起来就可以了。
class Solution:
def countSubTrees(self, n: int, edges: List[List[int]], labels: str) -> List[int]:
dic = {}
for s, e in edges:
if s not in dic:
dic[s] = []
if e not in dic:
dic[e] = []
dic[s].append(e)
dic[e].append(s)
res = [0] * n
vis = set()
def dfs(idx):
vis.add(idx)
char_dic = {}
char_dic[labels[idx]] = 1
for node in dic[idx]:
if node not in vis:
ne_dic = dfs(node)
for c in ne_dic:
if c not in char_dic:
char_dic[c] = 0
char_dic[c] += ne_dic[c]
res[idx] = char_dic[labels[idx]]
return char_dic
dfs(0)
return res
排列组合问题:
参考:https://juejin.im/post/5e5fc7eae51d4526c26fc732
回溯法的模式概括:
res = []
tmp = []
if <1.设置条件:把需要的当前列表加入res>:
res.append(当前列表)
return res
for 选择 in 选择列表:
<2.做选择>
<3.递归调用> backtrack(选择列表,当前列表,res)
<4.撤销选择>
全排列:
给定一个没有重复数字的序列,返回其所有可能的全排列。 示例: Input: [1,3,5] Output: [1,3,5], [1,5,3], [3,1,5], [3,5,1], [5,1,3], [5,3,1]
def permute(self, nums: List[int]) -> List[List[int]]:
# 函数输入为空时的特殊情况
if not nums: return nums
# 参数赋值初始化
res = []
tmp = []
# 调用backtrack函数,在类(class Solution)中要用self调用函数
self.backtrack(nums, tmp, res)
return res
def backtrack(self, nums, tmp, res): # nums是选择列表,tmp是当前选择
#<满足条件> 到达底层的条件就是选择列表nums为空
if not nums:
res.append(tmp[:])
for i in range(len(nums)):
#<做出选择> 把选择列表中的元素append到当前选择中
tmp.append(nums[i])
# <backtrack(选择列表, 当前选择, 结果)>
# nums[0:i] + nums[i+1:]就是把选了的nums[i]去掉,更新选择列表nums
self.backtrack(nums[0:i] + nums[i+1:], tmp, res)
# <撤销选择> 上面的调用结束即从下一层回溯到这一层,这时要更新当前选择tmp
tmp.pop()
非递归方法:字典序排列
起点:字典序最小的排列,例如122345。起点为正序
终点:字典序最大的排列,例如543221。终点为倒序
过程:按当前的排列找出刚好比它大的下一个排列
如:524321的下一个排列是531224
如何计算?
我们从后向前找第一双相邻的递增数字,”24”即满足要求,再从后面找一个比替换数大的最小数(这个数必然存在),1、2都不行,3可以,将3和2交换得到”534221”,然后再将替换点后的字符串”4221”颠倒即得到”531224”。
对于像”543221”这种已经是最“大”的排列,返回false。
这样,一个while循环再加上计算字符串下一个排列的函数就可以实现非递归的全排列算法。
总的步骤:后找、小大、交换、翻转
- 后找:字符串中最后一个升序的位置i,即:S[i]<S[i+1];
- 查找(小大):S[i+1…N-1]中比S[i]大的最小值S[j];
- 交换:S[i],S[j];交换操作前和操作后,S[i+1…N-1]一定都是降序的
- 翻转:S[i+1…N-1]
from copy import deepcopy
def swap(li, i, j):
if i == j:
return
temp = li[j]
li[j] = li[i]
li[i] = temp
def reverse(li, i, j):
"""
翻转
:param li: 字符串数组
:param i: 翻转开始位置
:param j: 翻转结束位置
"""
if li is None or i < 0 or j < 0 or i >= j or len(li) < j + 1:
return
while i < j:
swap(li, i, j)
i += 1
j -= 1
def get_next_permutation(li, size):
# 后找:字符串中最后一个升序的位置i,即:S[i]<S[i+1]
i = size - 2
while i >= 0 and li[i] >= li[i + 1]:
i -= 1
if i < 0:
return False
# 查找(小大):S[i+1…N-1]中比S[i]大的最小值S[j]
j = size - 1
while li[j] <= li[i]:
j -= 1
# 交换:S[i],S[j]
swap(li, i, j)
# 翻转:S[i+1…N-1]
reverse(li, i + 1, size - 1)
return True
if __name__ == '__main__':
li = [1, 2, 3, 2, 4, 5]
li.sort() # 初始的li必须是正序的 [1, 2, 2, 3, 4, 5]
size = len(li)
result = [deepcopy(li)]
while get_next_permutation(li, size):
result.append(deepcopy(li))
for i in result:
print(i)
有重复字符串的排列组合
有重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合。
示例1:
输入:S = “qqe”
输出:[“eqq”,“qeq”,“qqe”]
示例2:
输入:S = “ab”
输出:[“ab”, “ba”]
提示:
字符都是英文字母。
字符串长度在[1, 9]之间。
解法
- 按照全排列的方法,得到结果后用set去重,但是运行时间O(N!)
- 对散列表进行全排列,每次挑选一种字符加进去。
class Solution(object):
def permutation(self, S):
"""
:type S: str
:rtype: List[str]
"""
res, tmp = [], ""
dic = {}
for x in S:
if x not in dic:
dic[x] = 0
dic[x] += 1
self.dfs(len(S), res, tmp, dic)
return res
def dfs(self, remain, res, tmp, dic):
if remain == 0:
res.append(tmp)
return
for char, cnt in dic.items():
if cnt > 0:
dic[char] = cnt - 1
self.dfs(remain - 1, res, tmp + char, dic)
dic[char] = cnt
求子集
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
示例: Input: [1, 5, 3] Output: [], [1], [5], [3], [1,5], [1,3], [5,3], [1,5,3]
解法
<满足条件>因为所有出现的当前列表都是子集,不用设置条件,把所有tmp加到res中
不能从选择列表中取所有元素,因为找子集只考虑当前元素之后的元素们,不能出现重复元素,所以要设起始点idx排除用过的元素,idx影响的是range的范围(选择列表)。递归调用时,因为 nums 不包含重复元素,并且每一个元素只能使用一次,所以下一次搜索从 i + 1 开始。
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
if not nums: return None
res = []
self.backtrack(nums, [], res, 0)
return res
def backtrack(self, nums, tmp, res, idx):
# <满足条件>所有出现的当前列表都是子集,不用条件,直接append到res
res.append(tmp[:])
# 只考虑当前元素之后的元素们,要设起始点排除用过的元素
for i in range(idx, len(nums)):
# <做选择>
tmp.append(nums[i])
# <递归调用>
# 因为 nums 不包含重复元素,并且每一个元素只能使用一次,所以下一次搜索从 i + 1 开始
self.backtrack(nums, tmp, res, i+1)
# <撤销选择>
tmp.pop()
解法2
迭代,从空元素开始,循环每加入一个数组中的数值都相当于在上一个数组中的每项加入一个这个数值,再append到这个结果里
def subsets(nums):
res = []
res.append([])
# 大循环,取出数组内的每个元素
for i in nums:
#for j in res: #不要直接循环列表,用索引循环
# a = j.append(i) 这里j是列表,但不能这么写
# 小循环,取出结果的每个索引
for j in range(len(res)):
a = list(res[j])
# append大循环取出的元素
a.append(i) #不要写成b = a.append(a)
res.append(a)
return res
组合
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。 输入: n = 4, k = 2 输出: [[2,4], [3,4], [2,3], [1,2], [1,3], [1,4]]
解法
k作为<满足条件>,n用来创建<选择列表>,跟子集一样,这里用过的元素不能再出现,要在range选择列表中设置起始点idx排除已经用过的元素
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
if not n or not k:
return None
nums = range(1, n+1)
res = []
self.backtrack(nums, [], res, k, 0)
return res
def backtrack(self, nums, tmp, res, k, idx):
# <满足条件> k限制树的高度,达到高度时加上当前列表tmp
if len(tmp) == k:
res.append(tmp[:])
# 参考子集的做法,设置起始点idx用来排除已经用过的元素
for i in range(idx, len(nums)):
# <做选择>
tmp.append(nums[i])
# <递归调用>
self.backtrack(nums, tmp, res, k, i+1)
# <撤销选择>
tmp.pop()
分割回文串
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例:
输入: “aab”
输出:
[
[“aa”,“b”],
[“a”,“a”,“b”]
]
使用dfs递归算法,从左往右,依次看每个子串是否是回文;
注意把dfs算法写在里面,才能给res.append。
class Solution(object):
def partition(self, s):
"""
:type s: str
:rtype: List[List[str]]
"""
res = []
def dfs(s, path):
if not s:
res.append(path)
return
for i in range(1, len(s)+1):
if s[:i] == s[:i][::-1]:
dfs(s[i:], path+[s[:i]])
dfs(s, [])
return res
电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例:
输入:“23”
输出:[“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”].
说明:
尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
解法
- 用一个结果列表存储当前得到的字符串集合,每读取到下一个数字,在结果列表的末尾分别追加该数字对应的字母
- 同上回溯的DFS的方法
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
numberMap = {
'1': '',
'2': 'abc',
'3': 'def',
'4': 'ghi',
'5': 'jkl',
'6': 'mno',
'7': 'pqrs',
'8': 'tuv',
'9': 'wxyz'
}
if digits =='':
return []
ansSet = ['']
for num in digits:
tempSet = []
for ans in ansSet:
tempSet += [ans + c for c in numberMap[num]]
ansSet = tempSet
return ansSet
class Solution(object):
def letterCombinations(self, digits):
"""
:type digits: str
:rtype: List[str]
"""
if not digits:
return []
res, tmp = [], ""
dic = {'2': 'abc', '3': 'def', '4': 'ghi', '5': 'jkl', '6':'mno', '7':'pqrs', '8': 'tuv', '9': 'wxyz'}
self.dfs(digits, res, tmp, dic, 0)
return res
def dfs(self, digits, res, tmp, dic, start):
if start >= len(digits):
res.append(tmp)
return res
for i in range(len(dic[digits[start]])):
x = dic[digits[start]][i]
self.dfs(digits, res, tmp + x, dic, start + 1)
括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例:
输入:n = 3
输出:[
“((()))”,
“(()())”,
“(())()”,
“()(())”,
“()()()”
]
解法
设置两个计数变量,记录左右括号的数量,生成左括号做选择的时候就是判断左括号数目是否还不够,生成右括号的选择就是判断左括号数目是不是超过了右括号的输入。只有当左右括号数目都等于N的时候才返回。
class Solution(object):
def generateParenthesis(self, n):
"""
:type n: int
:rtype: List[str]
"""
res, tmp = [], ""
self.dfs(n, res, tmp, 0, 0)
return res
def dfs(self, n, res, tmp, l, r):
if l == n and r == n:
res.append(tmp)
return
if l < n:
self.dfs(n, res, tmp + '(', l + 1, r)
if l > r:
self.dfs(n, res, tmp + ')', l, r + 1)
八皇后
设计一种算法,打印 N 皇后在 N × N 棋盘上的各种摆法,其中每个皇后都不同行、不同列,也不在对角线上。这里的“对角线”指的是所有的对角线,不只是平分整个棋盘的那两条对角线。
注意:本题相对原题做了扩展
示例:
输入:4
输出:[[“.Q…”,”…Q”,“Q…”,”…Q.”],[“…Q.”,“Q…”,”…Q”,”.Q…”]]
解释: 4 皇后问题存在如下两个不同的解法。
[
[“.Q…”, // 解法 1
“…Q”,
“Q…”,
“…Q.”],
[“…Q.”, // 解法 2
“Q…”,
“…Q”,
“.Q…”]
]
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
st = [['.' for i in range(n)] for j in range(n)]
res = []
def dfs(x_d, y_d, cur):
j = len(cur)
if len(cur) == n:
m = []
for i in st: m.append(''.join(i))
res.append(m)
for i in range(n):
if i not in cur and i + j not in x_d and i-j not in y_d:
st[j][i] = 'Q'
dfs(x_d+[i+j],y_d+[i-j],cur+[i])
st[j][i] = '.'
dfs([], [], [])
return res
堆箱子
堆箱子。给你一堆n个箱子,箱子宽 wi、深 di、高 hi。箱子不能翻转,将箱子堆起来时,下面箱子的宽度、高度和深度必须大于上面的箱子。实现一种方法,搭出最高的一堆箱子。箱堆的高度为每个箱子高度的总和。
输入使用数组[wi, di, hi]表示每个箱子。
示例1:
输入:box = [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
输出:6
示例2:
输入:box = [[1, 1, 1], [2, 3, 4], [2, 6, 7], [3, 4, 5]]
输出:10
提示:
箱子的数目不大于3000个。
解法
每次选择最大的可以放到箱子里的,也可以提前按照某个维度排个序。
class Solution:
def pileBox(self, box: List[List[int]]) -> int:
@functools.lru_cache(maxsize=3000)
def sol(w, d, h) :
inners = [(iw,id,ih) for iw,id,ih in box if iw<w and id<d and ih<h]
if not inners : return h
return max((sol(iw,id,ih) for iw,id,ih in inners)) + h
return max((sol(w,d,h) for w,d,h in box))
矩阵中的最长递增路径
给定一个整数矩阵,找出最长递增路径的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
示例 1:
输入: nums =
[
[9,9,4],
[6,6,8],
[2,1,1]
]
输出: 4
解释: 最长递增路径为 [1, 2, 6, 9]。
示例 2:
输入: nums =
[
[3,4,5],
[3,2,6],
[2,2,1]
]
输出: 4
解释: 最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
解法
- DFS:但是要提前用一个字典存一下已经遍历过的位置
- 排序+动态规划

解法一:
class Solution:
def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
if not matrix: # 为空返回0
return 0
dic = {} # 初始化记忆化的字典,字典的查找为O(1),字典的值存储的是 以(raw,col)为开始节点的最长递增节点个数
for i in range(len(matrix)):
for j in range(len(matrix[0])):
dic[(i,j)] = -1
raws = len(matrix)
cols = len(matrix[0])
change = [[1,0],[-1,0],[0,1],[0,-1]] # 定义上下左右四个方向
def dfs(raw,col):
temp = 0
if dic[(raw,col)] != -1:# 如果这这个节点已经访问过,即它的最长递增数已经求出来了,直接返回即可
return dic[(raw,col)]
for s in change:# 如果这个节点没有访问过,开始上下左右遍历吧 !!!奥利给!!!
raw_ = raw + s[0]
col_ = col + s[1]
if 0 <= raw_ < raws and 0 <= col_ < cols and matrix[raw][col] < matrix[raw_][col_]: # 判断条件,防止越界和必须递增
temp = max(temp,dfs(raw_,col_)) # 取最大递增序列
dic[(raw,col)] = temp + 1 # 最大的递增序列加上当前的一个节点就是以(raw,col)为开始节点的最长递增节点个数
return temp + 1
res = 1
for raw in range(len(matrix)):
for col in range(len(matrix[0])):
if dic[(raw,col)] != -1: # 如果这这个节点已经访问过,即它的最长递增数已经求出来了
res = max(res,dic[(raw,col)])
else:
res = max(res,dfs(raw,col))
return res
解法二:
class Solution:
def longestIncreasingPath(self, matrix: List[List[int]]) -> int:
if not matrix:
return 0
x = len(matrix)
y = len(matrix[0])
dp = [[1 for __ in range(y)] for __ in range(x)]
numsSort = sorted(sum([[(matrix[i][j], i, j) for j in range(y)] for i in range(x)], []))
for i, j, k in numsSort:
dp[j][k] = 1+max(
dp[j-1][k] if j and matrix[j-1][k]<i else 0,
dp[j][k-1] if k and matrix[j][k-1]<i else 0,
dp[j+1][k] if j != x-1 and matrix[j+1][k]<i else 0,
dp[j][k+1] if k != y-1 and matrix[j][k+1]<i else 0
)
return max(sum(dp, []))
正则表达式匹配问题
字符串模式匹配 I
Given an input string (s) and a pattern §, implement regular expression matching with support for ‘.’ and ‘*’.
‘.’ Matches any single character.
‘*’ Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
Note:
s could be empty and contains only lowercase letters a-z.
p could be empty and contains only lowercase letters a-z, and characters like . or *.
Example 1:
Input:
s = "aa"
p = "a"
Output: false
Explanation: "a" does not match the entire string "aa".
Example 2:
Input:
s = "aa"
p = "a*"
Output: true
Explanation: '*' means zero or more of the preceding element, 'a'. Therefore, by repeating 'a' once, it becomes "aa".
Example 3:
Input:
s = "ab"
p = ".*"
Output: true
Explanation: ".*" means "zero or more (*) of any character (.)".
Example 4:
Input:
s = "aab"
p = "c*a*b"
Output: true
Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore, it matches "aab".
Example 5:
Input:
s = "mississippi"
p = "mis*is*p*."
Output: false
仔细看examples,注意’*‘的两种情况,一个是代表前一个字符重复0次(相当于忽略前一个字符),另一个是代表前一个字符重复n次,而且’*‘是不可以单独出现的;
感觉使用递归比动态规划更容易理解一些;
返回条件是p为空的时候,子问题是对’*‘的情况的分类考虑;
可以首先考虑没有’*’的情况,比较简单,就判断当前s[0]和p[0]是否匹配以及子问题是否匹配,即:
class Solution(object):
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
if not p:
return not s
first_m = bool(s) and p[0] in {s[0], '.'}
return first_m and self.isMatch(s[1:], p[1:])
加上’*‘就是考虑当p[2]==’*’的时候的两种情况,要么直接忽略前一个字符,要么当前匹配,而且重复n次:
class Solution(object):
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
if not p:
return not s
first_m = bool(s) and p[0] in {s[0], '.'}
if len(p)>=2 and p[1] == '*':
return (self.isMatch(s, p[2:])) or (first_m and self.isMatch(s[1:], p))
else:
return first_m and self.isMatch(s[1:], p[1:])
正则表达式匹配 II
给定s1, s2, (s1只包含正则表达式匹配中的 .* ? 和正常字符,s2只包含正常字符),判定s1 s2是否匹配。.代表任意一个字符,*代表长度,?代表前面的一个字符。*代表重复次数大于等于0,? 代表重复次数 0-1
下面是两个匹配成功的例子:
s1: abc.*abc
s2: abcabc
s1: abc?abc
s2: abcabc
解法
外面一层三个 if else 选择支在判断是不是有 * ? 这两种重复标记,每个选择支里面两个选择支判断当前字符是否匹配成功
简易版:https://blog.csdn.net/qq_20141867/article/details/80910724
def match(s, partten, i, j):
if i == len(s) and j == len(partten):
return True
elif i == len(s) or j == len(partten):
return False
if j + 1 < len(partten) and partten[j + 1] == '*':
if partten[j] == '.' or partten[j] == s[i]:
return match(s, partten, i + 1, j) or \
match(s, partten, i + 1, j + 2) or \
match(s, partten, i, j + 2)
else:
return match(s, partten, i, j + 2)
elif j + 1 < len(partten) and partten[j + 1] == '?':
if partten[j] == '.' or partten[j] == s[i]:
return match(s, partten, i + 1, j + 2) or match(s, partten, i, j + 2)
else:
return match(s, partten, i, j + 2)
else:
if partten[j] == '.' or partten[j] == s[i]:
return match(s, partten, i + 1, j + 1)
else:
return False
def main():
print(match("", "", 0, 0))
print(match("a", "a", 0, 0))
print(match("a", ".", 0, 0))
print(match("a", ".*", 0, 0))
print(match("a", "a?", 0, 0))
print(match("abcabc", "abc.*abc", 0, 0))
print(match("abcabc", "abc?abc", 0, 0))
print(match("abxxxacc", "abc.*abc", 0, 0))
print(match("abcdabc", "abc?abc", 0, 0))
if __name__ == "__main__":
main()
目标和
给定一个非负整数数组,a1, a2, …, an, 和一个目标数,S。现在你有两个符号 + 和 -。对于数组中的任意一个整数,你都可以从 + 或 -中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
示例 1:
输入: nums: [1, 1, 1, 1, 1], S: 3
输出: 5
解释:
-1+1+1+1+1 = 3
+1-1+1+1+1 = 3
+1+1-1+1+1 = 3
+1+1+1-1+1 = 3
+1+1+1+1-1 = 3
一共有5种方法让最终目标和为3。
注意:
数组非空,且长度不会超过20。
初始的数组的和不会超过1000。
保证返回的最终结果能被32位整数存下。
解法
题意:返回加减数组中每个数字和为目标数 S 的所有可能性。(如果用动态规划的思路的话:在背包问题中,我们要考虑物品放还是不放)
很快想到用DFS,定义函数f(i,target)表示i长度内目标为target的方法数,那么f(i,target)=f(i−1,target−nums[i])+f(i−1,target+nums[i])。直接这样做容易超时,所以可以想到用一个字典保存下来已经遍历过的方法数目。
class Solution(object):
def findTargetSumWays(self, nums, S):
"""
:type nums: List[int]
:type S: int
:rtype: int
"""
vis = {(0, 0): 1}
res = self.dfs(nums, S, vis)
return res
def dfs(self, nums, S, vis):
if (len(nums), S) in vis:
return vis[(len(nums), S)]
elif len(nums) == 0:
return 0
vis[(len(nums), S)] = self.dfs(nums[1:], S - nums[0], vis) + self.dfs(nums[1:], S + nums[0], vis)
return vis[(len(nums), S)]
图像渲染
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
最后返回经过上色渲染后的图像。
示例 1:
输入:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析:
在图像的正中间,(坐标(sr,sc)=(1,1)),
在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,
因为它不是在上下左右四个方向上与初始点相连的像素点。
注意:
image 和 image[0] 的长度在范围 [1, 50] 内。
给出的初始点将满足 0 <= sr < image.length 和 0 <= sc <image[0].length。
image[i][j] 和 newColor 表示的颜色值在范围 [0, 65535]内。
解法
很显然就是”迷宫“类问题,用dfs即可。也可以用队列解决
dfs方法:
class Solution(object):
def floodFill(self, image, sr, sc, newColor):
"""
:type image: List[List[int]]
:type sr: int
:type sc: int
:type newColor: int
:rtype: List[List[int]]
"""
if not image:
return image
curC = image[sr][sc]
self.vis = [[False for i in range(len(image[0]))] for j in range(len(image))]
image = self.dfs(image, sr, sc, curC, newColor)
return image
def dfs(self, image, r, c, curC, newC):
image[r][c] = newC
self.vis[r][c] = True
if r > 0 and image[r - 1][c] == curC and not self.vis[r - 1][c]:
image = self.dfs(image, r - 1, c, curC, newC)
if r < len(image) - 1 and image[r + 1][c] == curC and not self.vis[r + 1][c]:
image = self.dfs(image, r + 1, c, curC, newC)
if c > 0 and image[r][c - 1] == curC and not self.vis[r][c - 1]:
image = self.dfs(image, r, c - 1, curC, newC)
if c < len(image[0]) - 1 and image[r][c + 1] == curC and not self.vis[r][c + 1]:
image = self.dfs(image, r, c + 1, curC, newC)
return image
队列:
class Solution(object):
def floodFill(self, image, sr, sc, newColor):
"""
:type image: List[List[int]]
:type sr: int
:type sc: int
:type newColor: int
:rtype: List[List[int]]
"""
m, n = len(image), len(image[0])
color = image[sr][sc]
image[sr][sc] = newColor
visited = [[0 for _ in range(n + 1)] for _ in range(m + 1)]
dx = [1, -1, 0, 0]
dy = [0, 0, 1, -1]
q = deque()
q.append([sr,sc])
while q:
x0, y0 = q.popleft()
for k in range(4):
x = x0 + dx[k]
y = y0 + dy[k]
if 0 <= x < m and 0 <= y < n and image[x][y] == color and visited[x][y] == 0:
image[x][y] = newColor
visited[x][y] = 1
q.append([x, y])
return image
岛屿数量
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1
示例 2:
输入:
11000
11000
00100
00011
输出: 3
解法
标准的回溯问题:遍历整个矩阵,找到为1的就上下左右遍历,并把遍历过的设置为0,因为不会再遍历第二次(省掉visited数组).
回溯其实还可以通过队列的防止保存下来,用迭代解决。
class Solution(object):
def numIslands(self, grid):
"""
:type grid: List[List[str]]
:rtype: int
"""
if not grid:
return 0
res = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == '1':
res += 1
self.dfs(grid, i, j)
return res
def dfs(self, grid, x, y):
grid[x][y] = '0'
if x > 0 and grid[x-1][y] == '1':
self.dfs(grid, x-1, y)
if x < len(grid) - 1 and grid[x+1][y] == '1':
self.dfs(grid, x+1, y)
if y > 0 and grid[x][y-1] == '1':
self.dfs(grid, x, y-1)
if y < len(grid[0]) - 1 and grid[x][y+1] == '1':
self.dfs(grid, x, y+1)
24点游戏
你有 4 张写有 1 到 9 数字的牌。你需要判断是否能通过 *,/,+,-,(,) 的运算得到 24。
示例 1:
输入: [4, 1, 8, 7]
输出: True
解释: (8-4) * (7-1) = 24
示例 2:
输入: [1, 2, 1, 2]
输出: False
注意:
除法运算符 / 表示实数除法,而不是整数除法。例如 4 / (1 – 2/3) = 12 。
每个运算符对两个数进行运算。特别是我们不能用 – 作为一元运算符。例如,[1, 1, 1, 1] 作为输入时,表达式 -1 – 1 – 1 – 1 是不允许的。
你不能将数字连接在一起。例如,输入为 [1, 2, 1, 2] 时,不能写成 12 + 12 。
解法
回溯法:一共有 4 个数和 3 个运算操作,因此可能性非常有限。使用一个列表存储目前的全部数字,每次从列表中选出 2 个数字,再选择一种运算操作,用计算得到的结果取代选出的 2 个数字,这样列表中的数字就减少了 1 个。重复上述步骤,直到列表中只剩下 1 个数字,这个数字就是一种可能性的结果,如果结果等于 24,则说明可以通过运算得到 24。如果所有的可能性的结果都不等于 24,则说明无法通过运算得到 24。
注意:
- 除法运算为实数除法,因此结果为浮点数,列表中存储的数字也都是浮点数。在判断结果是否等于 24 时应考虑精度误差,这道题中,误差小于 10^{-6}可以认为是相等。
- 进行除法运算时,除数不能为 00,如果遇到除数为 00 的情况,则这种可能性可以直接排除。由于列表中存储的数字是浮点数,因此判断除数是否为 00 时应考虑精度误差,这道题中,当一个数字的绝对值小于 10^{-6} 时,可以认为该数字等于 00。
- 加法和乘法都满足交换律,因此如果选择的运算操作是加法或乘法,则对于选出的 2 个数字不需要考虑不同的顺序,在遇到第二种顺序时可以不进行运算,直接跳过。
class Solution:
def judgePoint24(self, nums: List[int]) -> bool:
TARGET = 24
EPSILON = 1e-6
ADD, MULTIPLY, SUBTRACT, DIVIDE = 0, 1, 2, 3
def solve(nums: List[float]) -> bool:
if not nums:
return False
if len(nums) == 1:
return abs(nums[0] - TARGET) < EPSILON
for i, x in enumerate(nums):
for j, y in enumerate(nums):
if i != j:
newNums = list()
for k, z in enumerate(nums):
if k != i and k != j:
newNums.append(z)
for k in range(4):
if k < 2 and i > j:
continue
if k == ADD:
newNums.append(x + y)
elif k == MULTIPLY:
newNums.append(x * y)
elif k == SUBTRACT:
newNums.append(x - y)
elif k == DIVIDE:
if abs(y) < EPSILON:
continue
newNums.append(x / y)
if solve(newNums):
return True
newNums.pop()
return False
return solve(nums)