参考文档:
精简2.0版
参考文档:找不到了
只对分词和去除停用词的步骤进行精简。
需要注意的是,比如“女士包”ana.extract_tags只会识别除“女士”,没有“包”,这与分词和字典无关。所以比较严谨的场景建议使用jieba.lcut
# 临时字典:把数字+单位算上。如2022年,3000w。
for i in articles.标题.str.findall('\d+.\d+.|\d+.').explode().dropna().unique():
jieba.add_word(i)
jieba.load_userdict('维护的分词字典.txt') # 加载自已维护的字典
ana.set_stop_words('stoplist.txt') # 添加停用词,ana.extract_tags直接分词
articles['分词'] = articles['标题'].apply(lambda x: ana.extract_tags(x, topK=None)).agg(set) # 分词并去除停用词 # 只统计包含关键词的标题数,故需去重。topK=None,统计所有关键词,默认为20
articles[['标题', '分词']]

精简1.0版
import pandas as pd
from io import StringIO
import jieba
from gensim import corpora, models
from collections import defaultdict
wx_kol.标题

# 旧字典👇
# # 增加分词字典
# add_words = ['老爹鞋', '巴黎世家']
# jieba.load_userdict(StringIO('\n'.join(add_words)))
# # 分词
# title = wx_kol[['标题']]
# title['分词'] = title.标题.str.findall('[\u4e00-\u9fa5]+|[a-zA-Z]+').apply(lambda x: '|'.join(x)).str.lower().agg(jieba.lcut) # 只取出中英文(去除奇怪的符号)
# # 去除停用词
# stop_list = pd.read_csv('../stopwords-master/stoplist.csv').停用词.to_list()
# stop_set = set(stop_list)
# title['去除停用词'] = title.分词.apply(lambda x: list(set(x)-stop_set))
# title
# 提取关键词(分词并剔除停用词)
jieba.load_userdict('维护的字典.txt') # 已维护字典:增加电商分词字典
title['标题关键词'] = title['标题'].str.replace('\W', ' ').str.lower().agg(jieba.lcut) # \W,只取数字、中英文
stop_set = set(pd.read_csv('stoplist.txt', header=None).iloc[:,0].to_list())|{' '}
title['标题关键词'] = title['标题关键词'].apply(lambda x: list(set(x)-stop_set))
去除停用词:
https://gitcode.net/mirrors/goto456/stopwords?utm_source=csdn_github_accelerator
# 变成词袋,生成词频和语料
texts = title['去除停用词'].to_list()
dictionary = corpora.Dictionary(texts) # 给每个词一个编号
corpus = title.分词.apply(dictionary.doc2bow) # dictionary.doc2bow 量化text,(id,出现次数)
# LDA模型训练
num_topics = 3
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics, iterations=500, random_state=100)
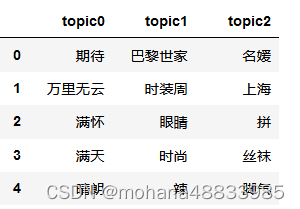
# 查看各主题的主题词
a = pd.DataFrame(lda.print_topics(num_words=20)).iloc[:, 1].str.findall('\*"(.*?)"')
df_topic = pd.DataFrame(a.apply(tuple).to_list()).T
df_topic.columns = ['topic%s'%i for i in range(df_topic.shape[1])]
df_topic
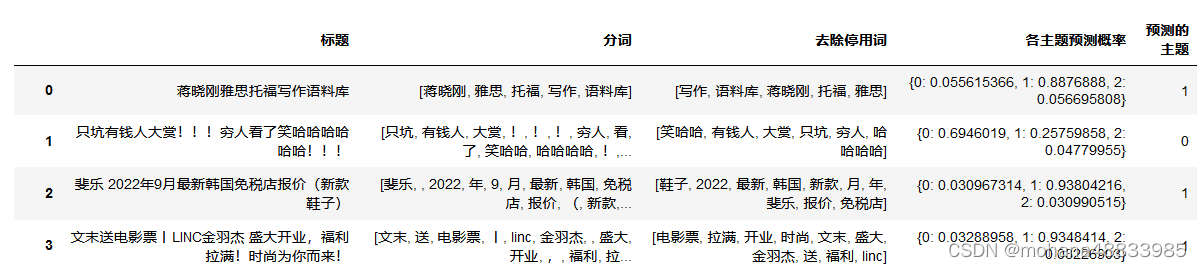
a = title.去除停用词.apply(dictionary.doc2bow).to_list()
title['各主题预测概率'] = list(lda.get_document_topics(a))
title['各主题预测概率'] = title['各主题预测概率'].apply(dict)
title['预测的主题'] = title['各主题预测概率'].apply(lambda x: list(x.values()).index(max(x.values())))
title
选择主题个数
参考链接:https://blog.csdn.net/weixin_51154479/article/details/123936270
https://blog.csdn.net/weixin_39676021/article/details/112187210
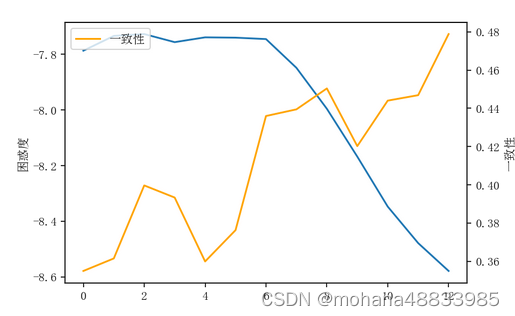
困惑度、一致性
%%time
model_list = [] # 存放模型
perplexitys = [] # 存放困惑度
coherences = [] # 一致性
for n in range(2, 15):
print("\r主题数量:", n, end='')
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=n, iterations=500, random_state=100)
model_list.append(lda)
perplexitys.append(lda.log_perplexity(corpus))
coherencemodel = models.CoherenceModel(model=lda, texts=title.分词.to_list(), dictionary=dictionary, coherence='c_v')
coherences.append(coherencemodel.get_coherence())
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(perplexitys, label='困惑度')
plt.ylabel('困惑度')
ax.twinx()
plt.plot(coherences, color='orange', label='一致性')
plt.ylabel('一致性')
plt.legend()
网页可视化
import pyLDAvis # pip install pyLDAvis
import pyLDAvis.gensim_models
vis_data = pyLDAvis.gensim_models.prepare(model_dic[3], corpus, dictionary)
pyLDAvis.show(vis_data, open_browser=False, local=False)
import报错参考链接:https://blog.csdn.net/she_is_brilliant/article/details/121750537
如网页输出报错参考链接:https://www.pudn.com/news/62f36fcaf97302478e2b8fcf.html
旧版本,啰嗦的代码
以中文为例
pht.公告
分词
# 导入包
import jieba
from gensim import corpora, models
from collections import defaultdict
for i in ['粉丝群', 'B站', 'BC勿扰', '周一', '周二', '周三', '周四', '周五', '周六', '周日','一点','0点', '1点', '2点', '3点', '4点', '5点', '6点', '7点', '8点', '9点', '10点', '11点', '12点', '13点', '14点', '15点', '16点', '17点', '18点', '19点', '20点', '21点', '22点', '23点', '24点']: # 添加自己想不分离的词
jieba.add_word(i)
去除停用词(Github上可以找到——哈工大停用词表)
with open('哈工大停用词表.txt', 'r', encoding='utf-8') as f:
a = f.read()
r_ty = re.sub('\n','|',a)[955:] # 去掉停用词 我、你、就等
def cut2list(x):
try:
return list(x)
except:
return ['']
r = '[’!"#$%&\'()*+,-./|:|:|;<=>?@[\\]^_`{|}~]+|欢迎|来到|直播间|的|、|小|不|群|便|客|' # 去掉符号
# r = r+r_ty
pht['公告词袋'] = pht.公告.apply(lambda x: re.sub(r_ty, '', re.sub(r,'', x))).map(jieba.cut).map(cut2list)
变成词袋,生成词频和语料
texts = pht.公告词袋.to_list() # 评论数最高的企业进行分析
dictionary = corpora.Dictionary(texts) # 生成词频字典
corpus = [dictionary.doc2bow(text) for text in texts] # 生成语料库
LDA模型的训练
num_topics = 3
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=3, iterations=200, random_state=100) # 迭代200次
查看各主题的主题词
word_pro = lda.get_topic_terms(0, topn=10000)
word_pro_x = list(map(lambda x: x[0],word_pro))
word_pro_y = list(map(lambda x: x[1],word_pro))
topic_list = lda.print_topics(num_words=40) # num_words:显示词数
df_topic = pd.DataFrame()
len_df = 10 # ------------想查看的前10个词---------------
for n,topic in enumerate(topic_list):
# print(topic)
df_topic.insert(0,f'topic{n}',re.findall('\*"(\w+)"', topic[1])[:len_df])
# 查看每个主题前num_words个词
df_topic
# 主题1:直播时间
# 主题2:对粉丝的感谢
# 主题3:粉丝马甲、卡牌子
lda模型预测
# 测试数据转换
test_vec = [dictionary.doc2bow(doc) for doc in pht.直播标题词袋]
#预测并打印结果
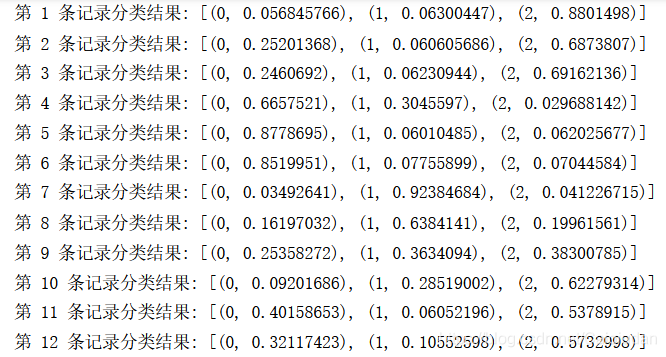
for i, item in enumerate(test_vec):
topic = lda.get_document_topics(item)
# keys = target.keys()
print('第',i+1,'条记录分类结果:',topic)