相信做过网站爬虫工作的同学都知道,python的urllib2用起来很方便,使用以下几行代码就可以轻松拿到某个网站的源码:
#coding=utf-8
import urllib
import urllib2
import re
url = "http://wetest.qq.com"
request = urllib2.Request(url)
page = urllib2.urlopen(url)
html = page.read()
print html
最后通过一定的正则匹配,解析返回的响应内容即可拿到你想要的东东。
但这样的方式在办公网和开发网下,处理部分外网站点时则会行不通。
比如:
http://tieba.baidu.com/p/2460150866,执行时一直报10060的错误码,提示连接失败。
http://tieba.baidu.com/p/2460150866,执行时一直报10060的错误码,提示连接失败。
#coding=utf-8
import urllib
import urllib2
import re
url = "http://tieba.baidu.com/p/2460150866"
request = urllib2.Request(url)
page = urllib2.urlopen(url)
html = page.read()
print html
执行后,错误提示截图如下:
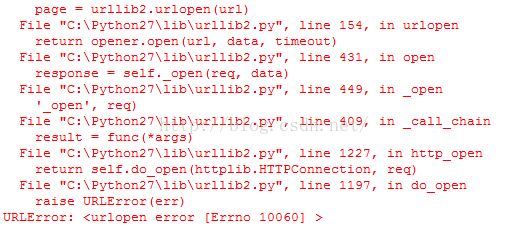
为了分析这一问题的原因,撸主采用了如下过程:
1、在浏览器里输入,可以正常打开,说明该站点是可以访问的。
2、同样的脚本放在公司的体验网上运行OK,说明脚本本身没有问题。
通过以上两个步骤,初步判断是公司对于外网的访问策略限制导致的。于是查找了下如何给urllib2设置ProxyHandler代理 ,将代码修改为如下:
#coding=utf-8
import urllib
import urllib2
import re
# The proxy address and port:
proxy_info = { 'host' : 'web-proxy.oa.com','port' : 8080 }
# We create a handler for the proxy
proxy_support = urllib2.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
# We create an opener which uses this handler:
opener = urllib2.build_opener(proxy_support)
# Then we install this opener as the default opener for urllib2:
urllib2.install_opener(opener)
url = "http://tieba.baidu.com/p/2460150866"
request = urllib2.Request(url)
page = urllib2.urlopen(url)
html = page.read()
print html
再次运行,可以拿到所要的Html页面了。
到这里就完了么?没有啊!撸主想拿到贴吧里的各种美图,保存在本地,上代码吧:
#coding=utf-8
import urllib
import urllib2
import re
# The proxy address and port:
proxy_info = { 'host' : 'web-proxy.oa.com','port' : 8080 }
# We create a handler for the proxy
proxy_support = urllib2.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
# We create an opener which uses this handler:
opener = urllib2.build_opener(proxy_support)
# Then we install this opener as the default opener for urllib2:
urllib2.install_opener(opener)
url = "http://tieba.baidu.com/p/2460150866"
request = urllib2.Request(url)
page = urllib2.urlopen(url)
html = page.read()
#正则匹配
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
print 'start dowload pic'
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'pic\\%s.jpg' % x)
x = x+1
再次运行,发现还是有报错!尼玛!又是10060报错,我设置了urllib2的代理了啊,为啥还是报错!
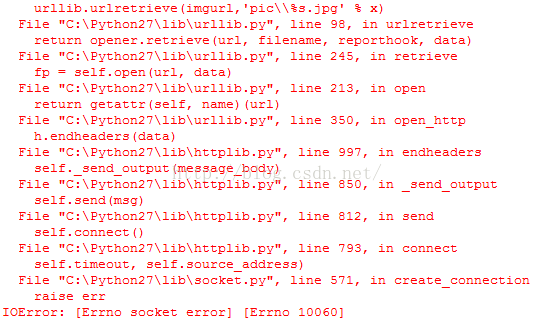
于是撸主继续想办法,一定要想拿到贴吧里的各种美图。既然通过正则匹配可以拿到贴吧里的图片的url,为何不手动去调用urllib2.urlopen去打开对应的url,获得对应的response,然后read出对应的图片二进制数据,然后保存图片到本地文件。于是有了下面的代码:
#coding=utf-8
import urllib
import urllib2
import re
# The proxy address and port:
proxy_info = { 'host' : 'web-proxy.oa.com','port' : 8080 }
# We create a handler for the proxy
proxy_support = urllib2.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
# We create an opener which uses this handler:
opener = urllib2.build_opener(proxy_support)
# Then we install this opener as the default opener for urllib2:
urllib2.install_opener(opener)
url = "http://tieba.baidu.com/p/2460150866"
request = urllib2.Request(url)
page = urllib2.urlopen(url)
html = page.read()
#正则匹配
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
print 'start'
for imgurl in imglist:
print imgurl
resp = urllib2.urlopen(imgurl)
respHtml = resp.read()
picFile = open('%s.jpg' % x, "wb")
picFile.write(respHtml)
picFile.close()
x = x+1
print 'done'
再次运行,发现还是图片的url按预期的打印出来,并且图片也被保存下来了:
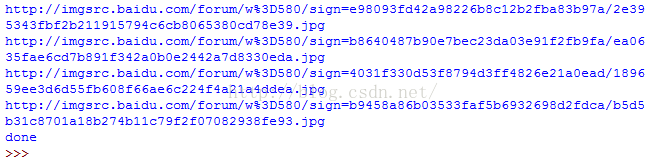

至此,已完成撸主原先要做的目的。哈哈,希望总结的东东对其他小伙伴也有用。
本文由腾讯WeTest团队提供,更多资讯可直接戳链接查看:http://wetest.qq.com/lab/
微信号:TencentWeTest
版权声明:本文为wetest_tencent原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。