OpenVINO 2022.3之四:OpenVINO模型转换
OpenVINO 2022.3 支持的模型格式:
-
OpenVINO IR(中间表示) – OpenVINO™的专有格式,可以完全利用其全部功能。
-
ONNX和PaddlePaddle – 直接支持的格式,这意味着它们可以在OpenVINO Runtime中使用,无需进行任何先前的转换。有关如何在ONNX和PaddlePaddle上运行推理的指南,请参阅如何将OpenVINO™与您的应用程序集成。
-
TensorFlow、PyTorch、MXNet、Caffe、Kaldi – 间接支持的格式,这意味着在运行推理之前需要将其转换为OpenVINO IR。转换由Model Optimizer完成,在某些情况下可能需要进行中间步骤。
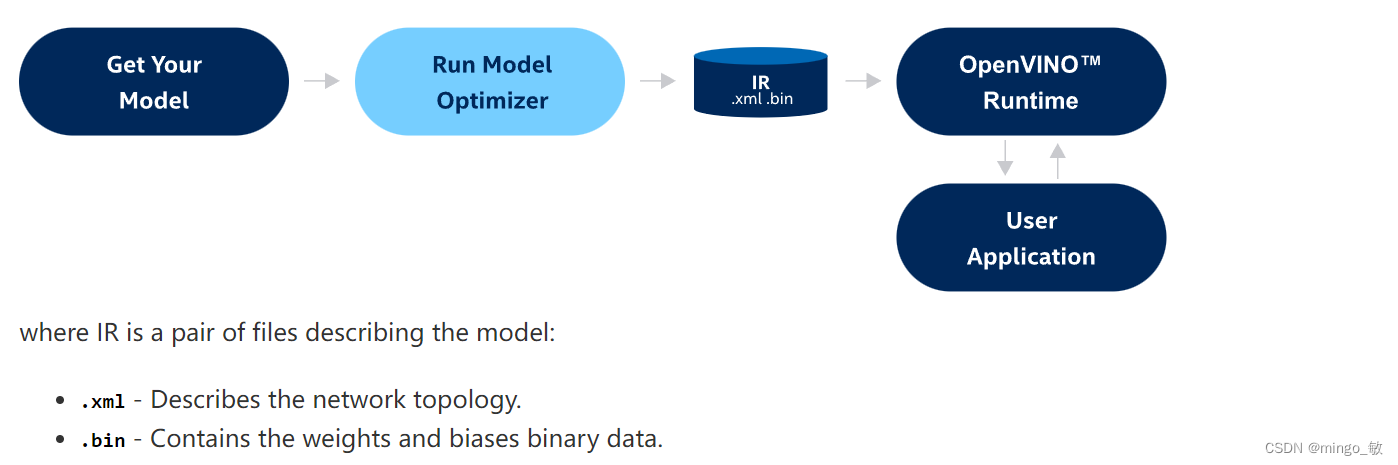
运行 Model Optimizer 将模型转换为IR格式mo –input_model INPUT_MODEL
指定输入形状
–input 和 –input_shape: 用于覆盖模型转换的原始输入形状;
示例如下:
# 单个输入
mo --input_model MobileNet.pb --input_shape [2,300,300,3]
# 多个输入
mo --input_model ocr.onnx --input data,seq_len --input_shape [3,150,200,1],[3]
# 使用 input
mo --input_model ocr.onnx --input data[3,150,200,1],seq_len[3]
# 动态维度可以用 -1 * 或 * ? 标记
mo --input_model ocr.onnx --input data,seq_len --input_shape [-1,150,200,1],[-1]
# 定义未知维度的边界,以优化模型的内存消耗
mo --input_model ocr.onnx --input data,seq_len --input_shape [1..3,150,200,1],[1..3]
模型优化
–disable_fusing, –disable_resnet_optimization 和 –finegrain_fusing: openvino 默认提供了一些方法来加速卷积神经网络(CNN)的推理,可以使用–disable_fusing来关闭这些优化,特别地,对于ResNet系列网络使用 –disable_resnet_optimization;进一步,可以使用–finegrain_fusing关闭特定的节点优化;
预处理嵌入模型(重要)
–scale_values, –reverse_input_channels, 和–layout: 基于这些参数,Model Optimizer生成OpenVINO IR并插入其他子图以执行定义的预处理操作,可以加快整个流水线(包括预处理和推理);
# 单个输入的 layout
mo --input_model tf_nasnet_large.onnx --layout nhwc
# 多个输入的 layout
mo --input_model yolov3-tiny.onnx --layout input_1(nchw),image_shape(n?)
# 改变模型的layout
mo --input_model tf_nasnet_large.onnx --source_layout nhwc --target_layout nchw
mo --input_model tf_nasnet_large.onnx --layout "nhwc->nchw"
# 改变多个输入的模型的layout
mo --input_model yolov3-tiny.onnx --source_layout "input_1(nchw),image_shape(n?)" --target_layout "input_1(nhwc)"
mo --input_model yolov3-tiny.onnx --layout "input_1(nchw->nhwc),image_shape(n?)"
# 使用 --mean_values, --scale_values, --scale 指定均值和比例值
mo --input_model unet.pdmodel --mean_values [123,117,104] --scale 255
# 反转输入通道
mo --input_model alexnet.pb --reverse_input_channels
模型压缩为FP16格式
–compress_to_fp16: 将模型转换为FP16格式,以支持半精度推理,会导致一定的精度下降;
mo --input_model INPUT_MODEL --compress_to_fp16
剪裁模型
–input 和 –output 参数定义转换模型的新输入和输出,为了去除模型中不需要的部分(例如不受支持的操作和训练子图);
# Cutting at the End
mo --input_model inception_v1.pb -b 1 --output=InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
# Cutting from the Beginning
mo --input_model=inception_v1.pb -b 1 --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --input InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
# Shape Override for New Inputs
mo --input_model inception_v1.pb --input_shape=[1,5,10,20] --output InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --input InceptionV1/InceptionV1/Conv2d_1a_7x7/Relu --output_dir <OUTPUT_MODEL_DIR>
1 转换ONNX模型
mo --input_model <INPUT_MODEL>.onnx
2 转换PyTorch模型
可以通过导出到ONNX格式来支持转换PyTorch模型。为了优化和部署使用了PyTorch训练的模型:
1.将PyTorch模型导出到ONNX。
2.基于训练好的网络拓扑结构、权重和偏差值,将ONNX模型转换为生成优化中间表示(IR)的模型。
import torch
# Instantiate your model. This is just a regular PyTorch model that will be exported in the following steps.
model = SomeModel()
# Evaluate the model to switch some operations from training mode to inference.
model.eval()
# Create dummy input for the model. It will be used to run the model inside export function.
dummy_input = torch.randn(1, 3, 224, 224)
# Call the export function
torch.onnx.export(model, (dummy_input, ), 'model.onnx')