1、在github官网上下载YOLOv3的源码,我下载的是YOLOv3-4.0版本的


2、对YOLOv3-4.0压缩包解压,解压完就是这样的

3、利用Pycharm打开YOLOv3-4.0文件
新建一个目录,命名为mydata。

在mydata目录中,一共创建5个子目录,分别为Annotations(用于存放.xml标注文件)、JPEGImages(用于存放训练图片)、images(用于存放训练图片)、labels(空子目录)、ImageSets(空子目录)。

4、创建make_txt.py文件,放到和mydata同级目录下

# -*- coding:utf-8 -*
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'mydata/Annotations'
txtsavepath = 'mydata/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml) #统计所有的标注文件
list = range(num)
tv = int(num * trainval_percent) # 设置训练验证集的数目
tr = int(tv * train_percent) # 设置训练集的数目
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
# txt 文件写入的只是xml 文件的文件名(数字),没有后缀,如下图。
ftrainval = open('mydata/ImageSets/trainval.txt', 'w')
ftest = open('mydata/ImageSets/test.txt', 'w')
ftrain = open('mydata/ImageSets/train.txt', 'w')
fval = open('mydata/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行make_txt.py文件,在ImageSets子目录中生成4个.txt文件,分别是test.txt、train.txt、trainval.txt、val.txt。

5、创建voc_label.py文件,放到和mydata同级目录下
# -*- coding:utf-8 -*
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['CW1S', 'CW2S','CW3S','CW4S','CW5S','CW6S','CW7S','CW8S','CW9S','CW10S',
'CW10S','CW2M','CW3M','CW4M','CW5M','CW6M','CW7M','CW8M','CW9M','CW10M',
'CW1H','CW1H','CW3H','CW4H','CW5H','CW6H','CW7H','CW8H','CW9H','CW10H']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('mydata/Annotations/%s.xml' % (image_id),encoding='gb18030')
out_file = open('mydata/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('mydata/labels/'):
os.makedirs('mydata/labels/')
image_ids = open('mydata/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('mydata/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('mydata/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
修改第9行的classes,存放自己数据集的类别

第47行这里注意自己的文件夹位置,我是mydata文件夹,如果你们自己创建的时候不是mydata,记得修改

运行voc_label,py文件,在mydata目录中得到3个.txt文件,分别是test.txt、train.txt、val.txt;同时mydata/labels子目录中也生成了一些.txt文件。


6、在cfg子目录中创建yolo.data,如图填写

7、在mydata目录中创建yolo.name文件,在yolo.name中填写自己数据集的类别名称

8、修改cfg目录中yolov3.cfg文件中,610行、696行、783行classes=自己数据集的类别数;603行、689行、776行filters=(自己数据集的类别数+5)*3。

9、修改train.py文件中的101行的
# Update scheduler scheduler.step()
放到170行


修改第60行yolov3权重文件的名称
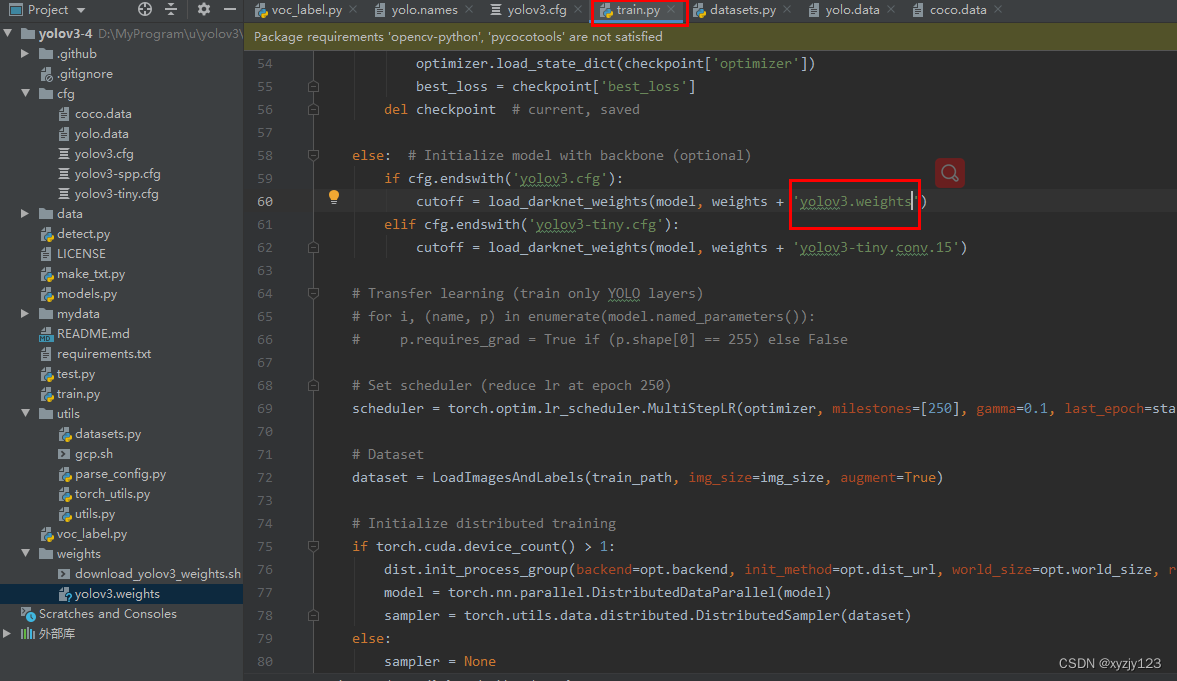
修改210行,改成yolo.data

10.根据weights目录中的download_yolov3_weights.sh下载yolov3-4.0的权重文件

11、在ultils/datasets.py中的第104行将images修改成JPEGImages。

12、运行train.py文件

本博客参考了其他兄弟姐妹的博客,下面将参考到的博客的链接全部放在这里
(pytorch)yolov3训练自己的模型_Mihu_Tutu的博客-CSDN博客_pytorch yolo3模型
Python报错 UnicodeDecodeError: ‘gbk‘ codec can‘t decode bytein position 2: illegal multibyte sequence_是杰夫呀的博客-CSDN博客
UserWarning: Detected call of `lr scheduler.step()` before `optimizer.step()`. – Trouvaille_fighting – 博客园
使用YOLOV3训练自己的数据集_FlyDremever的博客-CSDN博客_用yolov3训练自己的数据集