RPN(Region Proposal Networks)
RPN 的全称为 Region Proposal Networks,提取用于目标检测的 regions,这一步骤意在取代传统 R-CNN中利用 selective search 提取候选框的过程。

特征图中每个红色框的中心点都可以对应到原图的某个点,原图中的这个点被称为锚点(anchor)。对于每个锚点,我们都会以它为中心点选择 9 个不同大小和长宽比例的框(论文中为 128 * 128,256 * 256,512 * 512 的三种尺寸,每种尺寸按 1:1,1:2,2:1的长宽比例缩放,共 9 个,它们在预测时的顺序是固定的),作为 RPN 需要评估的候选框。RPN 的目标就是对原图中的每个锚点对应的 9 个框,预测他是否是一个存在目标的框(并不一定包含完整的目标,只要这个框与 groud truth 的 IoU>0.7就认为这个框是一个 region proposal)。并且对于预测为 region proposal 的框, RPN 还会预测一种长宽缩放和位置平移的位置修正,使得对这个 anchor box 修正后与 groud truth 的位置尽可能重叠度越高,修正后的框作为真正的 region proposal。
RPN 的主要步骤如下:
1、利用 VGG16 等卷积神经网络的卷积层的到一些特征图,例如图中的 256 个 H * W 的特征图
2、在特征图上用 3 * 3 的滑动窗口进行卷积,得到进一步的 256 * H * W 的特征图,从特征的维度看可以看成 H * W 的特征图上每个点都有一个 256 维的特征向量
3、将特征图上每个点的 256 维特征与两个全连接层连接。第一个全连接层输出 2 * 9 个值,即这个锚点对应的 9 个 achor box,每个 box 两个值分别表示包含目标的概率与不包含的概率(使用了 softmax loss 所以需要两个值)。例如前两个值表示 128 * 128 的 box 包含与不包含目标的概率。第二个全连接层输出 4 * 9 个值,每个 anchor box 对应 4 个值,它们分别表征对 groud truth 的长宽与x、y坐标的预测(其实为四个平移缩放系数)。(训练时只有包含目标(即与 groud truth 的 IoU>0.7)的 anchor box 对 groud truth 位置与大小预测的误差才会对 loss 有贡献)
4、对步骤 3 中预测包含目标的 anchor box,
利用 4 个位置回归值对 box 进行平移和缩放
,就能产生大量的候选框,此时利用非极大值抑制筛选一些预测分较高的候选框,作为最终的 region proposals

为了生成region proposals,我们在卷积的feature map上滑动一个小的网络,这个feature map 是最后一个共享卷积层的输出。这个小网络需要输入卷积feature map的一个n*n窗口。每个滑动窗口都映射到一个低维特征(ZF是256维,VGG是512维,后面跟一个ReLU激活函数)。这个特征被输入到两个全连接层中(一个box-regression层(reg),一个box-classification层(cls))。
我们在这篇论文中使用了n=3,使输入图像上有效的接受域很大(ZF 171个像素,VGG 228个像素)。这个迷你网络在图3(左)的位置上进行了说明。注意,由于迷你网络以滑动窗口的方式运行,所以全连接层在所有空间位置共享。这个体系结构是用一个n
n的卷积层来实现的,后面是两个1
1的卷积层(分别是reg和cls)。
Anchors(锚点)
在每个滑动窗口位置,我们同时预测多个region proposals,其中每个位置的最大可能建议的数量表示为k。所以reg层有4 k输出来编码k个box的坐标(可能是一个角的坐标(x,y)+width+height),cls层输出2 k的分数来估计每个proposal是object的概率或者不是的概率。这k个proposals是k个参考框的参数化,我们把这些proposals叫做Anchors(锚点)。锚点位于问题的滑动窗口中,并与比例和纵横比相关联。默认情况下,我们使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个锚点。对于W
H大小的卷积特性图(通常为2,400),总共有W
H*k个锚点
平移不变性的锚点
我们的方法的一个重要特性是是平移不变性,锚点本身和计算锚点的函数都是平移不变的。**如果在图像中平移一个目标,那么proposal也会跟着平移,这时,同一个函数需要能够在任何位置都预测到这个proposal。我们的方法可以保证这种平移不变性。**作为比较,the MultiBox method使用k聚类方法生成800个锚点,这不是平移不变的。因此,MultiBox并不保证当一个对象被平移式,会生成相同的proposal。
多尺度锚点作为回归参考
我们的锚点设计提出了一种解决多个尺度(和纵横比)的新方案。如图所示,有两种流行的多尺度预测方法。

(a.建立了图像和特征图的金字塔,分类器在所有的尺度上运行。b. 具有多个尺寸/大小的过滤器金字塔在feature map上运行。c. 我们在回归函数中使用了参考框的金字塔。)
第一种方法是基于图像/特征金字塔,例如,在DPM和基于cnn方法的方法。这些图像在多个尺度上进行了调整,并且为每个尺度计算特征图(占用或深度卷积特性)(图1(a))。这种方法通常很有用,但很耗费时间。第二种方法是在feature map上使用多个尺度(和/或方面比率)的滑动窗口。例如,在DPM中,不同方面比率的模型分别使用不同的过滤大小(如5 7和7 5)进行单独训练。如果这种方法用于处理多个尺度,它可以被认为是一个过滤器金字塔(图1(b))。第二种方法通常是与第一种方法共同使用的
IOU
用于测量真实和预测之间的相关度,相关度越高,该值越高。

标签分类规定
前面已经得到了每个框是不是物体的的概率,现在根据IOU对其进行背景和前景的标签:
为了训练RPN,需要给每个anchor分配的类标签{前景(目标)、背景(非目标)}。
-
对于positive label(正标签),论文中给了如下规定(满足以下条件之一即可判为正标签):
1.与GT包围盒最高IoU重叠的anchor
2.与任意GT包围盒的IoU大于0.7的anchor
注意,一个GT包围盒可以对应多个anchor,这样一个GT包围盒就可以有多个正标签
事实上,采用第②个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的anchor box与groud truth的IoU不大于0.7,可以采用第一种规则生成。 -
negative label(负标签):
与所有GT包围盒的IoU都小于0.3的anchor。
对于既不是正标签也不是负标签的anchor(大于0.3小于0.7的),以及跨越图像边界的anchor我们给予舍弃,因为其对训练目标是没有任何作用的。
NMS
对候选框进行标记之后,只留下了为前景(目标)的候选框,而此时很多候选框是存在很多重叠的

然后再次根据分类score的大小进行筛选(保留较大值的框):

经过NMS筛选之后,在剩下的128个候选框中进行窗口分类和位置精修
窗口分类和位置精修
分类层(cls_score)输出每一个位置上,9个anchor属于
前景和背景的概率。
窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数(x,y,w,h)。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中
输出4个平移缩放参数。
需要注意的是:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
实际上步骤 3 中预测的 4 个值不是直接预测 H, W, x, y,很显然由于特征图上每个点都是共享权值的,它们根本没法对不同的长宽和位置做出直接的预测(想象一下输入的特征只是图像的卷积特征,完全没有当前 anchor box 的位置大小信息,显然不可能预测出 groud truth 的绝对位置和大小)。这 4 个值是预测如何经过平移与缩放使得当前这个 anchor box 能与 groud truth 尽可能重合(见 R-CNN 论文附录C):
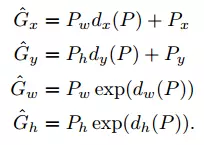
公式中 P 表示预测包含目标的 region proposal,G 表示这个 region proposal 对应的 groud truth,x, y, w, h分别表示横坐标、纵坐标、宽和高。dx§, dy§, dw§, dh§ 即 RPN 预测的 4 个值,它们表征的是对位置平移与大小缩放的系数。
由于 4 个 G 值与 4 个 P 值都是已知的,那么我们训练时就有了 dx§, dy§, dw§, dh§ 的目标值如图所示:
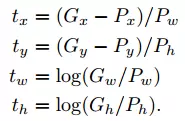
全连接层就是一个回归函数,用于预测 4 个系数 d:
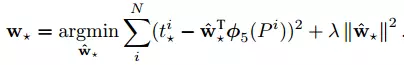
只有图像像素卷积信息确实没法预测 groud truth 的绝对位置和大小,但是利用图像信息完全有可能预测当前 region proposal 在 grouth truth 中的相对位置,我们也就可以预测怎么对当前 anchor box 进行平移与缩放得到包含整个目标的候选框。例如一辆自行车,可能当前的 anchor box 中包含着自行车的前轮与把手部分,当 cnn 检测到这样的特征时,他就能预测将这个 box 向右平移并且水平方向扩大一倍就是整个自行车目标的 groud truth部分。
ROIPooLing
我们先把roi中的坐标映射到feature map上,映射规则比较简单,就是把各个坐标除以“输入图片与feature map的大小的比值”,得到了feature map上的box坐标后,我们使用Pooling得到输出;由于输入的图片大小不一,所以这里我们使用的类似Spp Pooling,在Pooling的过程中需要计算Pooling后的结果对应到feature map上所占的范围,然后在那个范围中进行取max或者取average。
原文链接:https://blog.csdn.net/qq_22637925/article/details/79474863
ROI pooling层能实现training和testing的显著加速,并提高检测accuracy。该层有两个输入:
- 从具有多个卷积核池化的深度网络中获得的固定大小的feature maps;
- 一个表示所有ROI的N*5的矩阵,其中N表示ROI的数目。第一列表示图像index,其余四列表示其余的左上角和右下角坐标;
ROI pooling具体操作如下:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
-
对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
原文链接:https://blog.csdn.net/u011436429/article/details/80279536
ROI Pooling 就是将大小不同的feature map 池化成大小相同的feature map,利于输出到下一层网络中。