本文主要讲述了一种识别简单验证码的方法,本文重点不是识别这些简单的数字,而是通过识别数字这个过程理解到图片的数字构造。任何一张图片都是由三个图层构成的,每个图层是一张二维矩阵表,三张表上位置相同的三个数值组成一个像素点,数值范围是0到255,黑白图片三张表是相同的,所以是256种颜色,彩色图片三张表的数值不一样,所以液晶电视打广告的真彩色有256
256
256=16777216种颜色。
识别步骤主要分为3步:
1、对验证码图片打标签并创建文字和图片一一对应的识别模板集,以供后续比对使用;
2、提取待识别验证码图片并按照模板创建的规则创建图片集;
3、把待识别的图片集和模板集进行比对,以判断待识别的图片是什么文字。
本文用的匹配方法是位置匹配,是将像素点在图片中的位置转换为二维坐标值,左下角为原点(0,0)。匹配的时候是将两张图片的坐标进行比对,待识别图片坐标值在与之匹配的图片中有相同坐标值的,正确数+1,反之错误数+1,公式如下:
匹配率 = (正确数 – 错误数)/ 待识别图片坐标总数 * 100%
文件构成:
待识别图片:
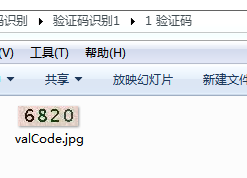
图片特征库:

提取图片像素后坐标化:

提取图片中的一个数字:

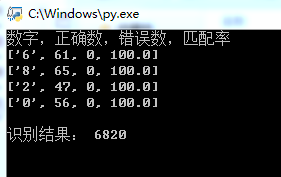
运行结果:
图片识别部分:
import numpy as np
import random
from PIL import Image
import matplotlib.pyplot as plt
import os
import operator
import k_means1
import time
def Mapping1(mpp): #绘图
if mpp!=[]:
colors=['b','g','r','c','m','y','k']
s=0
for j in mpp:
plt.plot(j[0], j[1], color=colors[s%len(colors)], marker='.')
plt.ion()
plt.show()
plt.pause(3)
plt.close()
def Mapping2(mpp): #绘图
if mpp!=[]:
colors = ['b','g','r','c','m','y','k']
s=0
for j in mpp:
for i in j:
plt.plot(i[0], i[1], color=colors[s%len(colors)], marker='.')
s = s+1
#plt.ion()
plt.show()
#plt.pause(3)
#plt.close()
#提取图片中的字符(通用函数)
def Picture_processing(image,characters): #输入一张图片,返回4个列表
#print(image.format, image.size, image.mode)
#image_array = image.load(); #获取像素点
#image.show()
gray = image.convert("L"); #转换灰度
gray_array = gray.load(); #获取像素点
#2分类去除淡色部分
data = []
for j in range(0,image.size[0]):
for i in range(0,image.size[1]):
#print(gray_array[j,i])
data.append(gray_array[j,i])
data_list = k_means1.k_means(data,2); #k个均值分k份
#提取黑色部分坐标
mpp = []
for j in range(0,image.size[0]):
for i in range(0,image.size[1]):
if gray_array[j,i]<data_list[1][0]:
gray_array[j,i] = 0
mpp.append([j,image.size[1]-i])
else:
gray_array[j,i] = 255
#Mapping1(mpp); #绘图
#按照图片字符分4组
mpp2 = []
for j in range(0,len(characters)):
mpp2.append([])
for j in mpp:
if j[0]<=17:
mpp2[0].append(j)
if 17<j[0]<=30:
mpp2[1].append(j)
if 30<j[0]<=43:
mpp2[2].append(j)
if 43<j[0]:
mpp2[3].append(j)
#Mapping2(mpp2); #绘图
#x轴向0点移动
for j in range(0,len(mpp2)):
mpp2[j].sort(reverse=False,key=operator.itemgetter(0)) #正序
min0 = mpp2[j][0][0]
for i in range(0,len(mpp2[j])):
mpp2[j][i][0] = mpp2[j][i][0]-min0
#y轴向0点移动
for j in range(0,len(mpp2)):
mpp2[j].sort(reverse=False,key=operator.itemgetter(1)) #正序
min0 = mpp2[j][0][1]
for i in range(0,len(mpp2[j])):
mpp2[j][i][1] = mpp2[j][i][1]-min0
#for j in mpp2:
# Mapping2([j]); #绘图
mpp3 = mpp2[0:4]; #返回4个字符图案
for j in range(0,len(mpp3)):
for i in range(0,len(mpp3[j])):
mpp3[j][i] = (str(mpp3[j][i][0])+','+str(mpp3[j][i][1]))
mpp4 = []
for j in range(0,len(mpp3)):
mpp4.append([mpp3[j],characters[j],len(mpp3[j]),(str(characters[j])+','+str(len(mpp3[j])))]); #像素点数特征,字符,像素点数量
return mpp3,mpp4
#提取图片
def get_picture_library():
images = []
photos = os.listdir(os.getcwd()+'\\3 验证码特征库')
for j in photos:
images.append(Image.open(os.getcwd()+"\\3 验证码特征库\\"+j))
return images,photos
#构建图库特征
def get_feature_library(): #返回图库特征
images,photos = get_picture_library() #提取图片
wb1 = []
for j in photos:
wb1.append([j[0],j[1],j[2],j[3]]); #提取文件名前4个字符
mpp5 = []
for image,j in zip(images,wb1):
mpp3,mpp4 = Picture_processing(image,j); #输入一张图片,返回3个列表(3个字符)
mpp5.extend(mpp4)
Unique_set = set()
for j in mpp5:
Unique_set.add(j[3])
mpp6 = []
for j in Unique_set:
for i in mpp5:
if j==i[3]:
mpp6.append(i)
break
mpp6.sort(reverse=False,key=operator.itemgetter(1)) #正序
mpp6.sort(reverse=False,key=operator.itemgetter(2)) #正序
#for j in mpp6:
# print(j[1],j[2],j[3]) #0是坐标特征(坐标值)列表,1是表征字符,2是坐标点数,3是1和2的字符结合
return mpp6
#提取图片
def get_sample_picture():
images = []
photos = os.listdir(os.getcwd()+'\\1 验证码')
for j in photos:
images.append(Image.open(os.getcwd()+"\\1 验证码\\"+j))
return images,photos
#单张图片识别
def image_recognition(mpp6): #图片识别
images,photos = get_sample_picture() #提取图片
wb1 = []
for j in photos:
wb1.append(['a','b','c','d'])
mpp5 = []
for image,j in zip(images,wb1):
mpp3,mpp4 = Picture_processing(image,j); #输入一张图片,返回4个列表(4个字符)
mpp5.extend(mpp4)
wb2 = []
for j in mpp5: #样本
temporary_list = []
for i in mpp6: #图库
yes = 0
no = 0
for m in j[0]: #样本坐标特征列表
if m in i[0]:
yes = yes+1
else:
no = no+1
temporary_list.append([i[1],yes,no,int((yes-no)/j[2]*10000)/100]); #字符,正确数,错误数,匹配率
#j[2]是样本中图片的坐标点数,因为前面是按照样本的坐标点数来计数正确和错误数的,又因为全部图片不是一样大小的,
#所以只有用计数的坐标总点数,如能完全匹配,匹配率才能刚好100%
temporary_list.sort(reverse=False,key=operator.itemgetter(2)); #错误数升
temporary_list.sort(reverse=True,key=operator.itemgetter(1)); #准确数降序
temporary_list.sort(reverse=True,key=operator.itemgetter(3)); #匹配率降序
wb2.append(temporary_list[0]) #提取匹配率最高的数字
return wb2
def main():
#构建图库特征
mpp6 = get_feature_library()
#单张图片识别
data = image_recognition(mpp6)
print("数字,正确数,错误数,匹配率")
rec = ''
for j in data:
print(j)
rec = rec + j[0]
print()
print("识别结果:",rec)
return rec
if __name__=='__main__':
main()
time.sleep(60)
k-means函数:
import numpy as np
import random
def func00(): #生成随机数列表
#random.seed(1)
kjz1=[random.randint(1,50) for j in range(0,7000)]
kjz1.extend([random.randint(80,150) for j in range(0,8000)])
kjz1.extend([random.randint(200,300) for j in range(0,5000)])
kjz1.extend([random.randint(400,500) for j in range(0,8000)])
return kjz1
def func01(kjz1): #2分类
bj=1;kjz1=np.sort(kjz1)
while(True):
if bj==1:
kj=np.mean([kjz1[0],kjz1[len(kjz1)-1]]) #初始分组均值使用最小值和最大值的平均值
else:
k1=s1;k2=s2;
kj=np.mean([k1,k2]);
kjz2=[[],[]];
for j in kjz1:
if j<=kj:
kjz2[0].append(j)
else:
kjz2[1].append(j)
s1=np.mean(kjz2[0]);
s2=np.mean(kjz2[1]);
if bj==2:
if s1==k1 and s2==k2:
break
bj=2;
return kjz2
def func02(kjz1,k): #k个均值分k份
kjz1=np.sort(kjz1);#正序
wb2=kjz1.copy();
#初始均匀分组wb1
xlb=[];a=round(len(wb2)/(k));b=len(wb2)%(k);
for j in range(1,k+1):
xlb.append(j*a)
if j==k:
xlb[j-1]=xlb[j-1]+b;
j=0;wb1=[];
for j in range(0,k):
wb1.append([])
i=0;j=0;
while(i<=len(wb2)-1):
wb1[j].append(wb2[i]);
if i>=xlb[j]-1:
j=j+1;
i=i+1;
kj1=means(wb1);#初始分组均值
bj=1;
while(True):
wb2=kjz1.copy().tolist();
if bj!=1:
kj1=kj2.copy();
wb3=[];
for j in range(0,k-1):
wb3.append([])
for j in range(0,k-1):
i=-1;
while(True):
if wb2[i]<=kj1[j]:
wb3[j].append(wb2.pop(i));
else:
i=i+1;
if i>=len(wb2):
break
wb3.append(wb2)
kj2=means(wb3);#过程均值
if bj==2:
if kj1==kj2:
break
bj=2;
return wb3
def means(lb1): #计算均值
mean1=[];mean2=[];std1=[];
for j in lb1:
mean1.append(np.mean(j).tolist())
for j in range(1,len(mean1)):
mean2.append(np.mean([mean1[j-1],mean1[j]])) #分组均值使用各组的均值
return mean2
def k_means(data,k):
#data=func00() #生成随机数列表
#kjz2=func01(data) #2分类
kjz3=func02(data,k) #k个均值分k份
return kjz3
版权声明:本文为qq_24311495原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。