本文写的内容可能在很多巨佬看来属实是一些简单的废话,但我的底子比较薄,很多东西都是想了好久,这篇文章的主要目的实际上也只不过是把我的一些改进的地方记录下来,防止以后忘记。。。
题目描述:
百度、谷歌等互联网搜索引擎提供高效的网页、文档搜索功能,用户可以通过一个和多个关键词查询感兴趣的网页信息。要实现超大规模的文本文档搜索,通常需要借助高效的索引和查询算法。
编程实现一个基于关键词的文档搜索程序,实现对大规模文本文档的快速搜索和排序。具体方法如下:
1、对给定的文档(网页)集合(含N个文档)中每个文档进行
单词
(英文)提取,并统计每个单词k在每个文档d出现的频次(即出现次数)TNkd(该文档总词数为
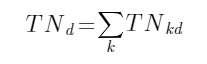
),由此可以计算其词频TFkd
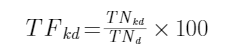
为了提高算法的准确性,在此只统计
字典中出现且不为停用词
(stop-word)的单词
。
单词为仅由字母组成的字符序列
,包含大写字母的单词应
将大写字母转换为小写字母
后进行词频统计。
在
课程网站下载区提供了
字典“dictionary.txt”文件和英文停用词表“stopwords.txt”文件(文件中只包含单词,不含其解释,且
已按字典序排序
)。
说明:在自然语言处理中,停用词(stop-word)指的是文本分析时不会提供额外语义信息的词的列表,如英文单词a,an,he,you等就是停用词。
2、统计每个单词k在文档集合中出现的次数(DNk,即出现该单词的文档数),并计算其逆文档频率IDFk(log以10为底)。定义如下:
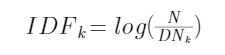
3、针对输入的关键词K1,K2,..,Km,按照TF-IDF对文档集合中的文档进行相关度打分。对任意一个文档d,针对所输入的关键词,其相关度计算公式如下:

若某个关键词未在文档集合中出现,则不用计算其IDFk,其对所有文档的相关度都为0。
4、依据相关度给出检索结果按由高至低进行排序,返回Top-N的结果。
为了简化搜索引擎的实现,从互联网上爬取(Web Crawling)相关网页(文档)的工作已经完成,并将爬取的网页文档数据已存入一个文本文件(aritcle.txt)中,其中每个网页第一行为网页标识号(如XX-XXXX,可按字符串来输入),然后为网页内容,网页文档间以
换页符\f
分隔。在
课程网站下载区提供了
一个用于测试的article.txt文件。
【输入形式】
从命令行输入作为需要返回的检索结果数量NUM和作为检索的关键词串K1,K2,..,Km
具体形式如下:
search NUM K
1 K2
.
. Km
其中search为搜索引擎运行程序,NUM与关键词之间以一个空格分隔。根据当前目录下的“dictionary.txt”文件、停用词文件“stopwords.txt”以及网页数据文件“article.txt”,按上面要求对网页文档进行相关度计算和排序。
注意:
1.输入串K1 K2 .. Km中的
停用词及非字典中单词将不进行相关度分析
。
2.由于Windows系统下文本文件中的’\n’回车符在(评测环境)Linux系统下会变为’\r’和’\n’2个字符,建议用fscanf(fp,”%s”,…)来处理
字典文件和停用词文件中
英文单词。
【输出形式】
先将Sim值
排名前5
(TOP 5)的网页信息
输出到屏幕上
,输出时先输出相关度Sim值(小数点后保留六位)、相应网页序号(从article.txt文件中读入网页文档时按序从1开始编号)及在文件article.txt中的标识号,三者之间由一个空格分隔,最后有一个回车。
同时将Sim值
排名前NUM
(TOP N)的网页信息输出到results.txt文件中,输出时先输出相关度Sim值(小数点后保留六位)、相应网页序号(从article.txt文件中读入网页文档时按序从1开始编号)及在文件article.txt中的标识号,三者之间由一个空格分隔,每个网页信息后有一个回车;若找到的网页文档数(
即Sim值大于0的文档数,即包含所给关键词的文档数
)少于
NUM,
则按实际数目输出(屏幕输出也如此)。
注意:
如果相关度Sim值相同
,则按照
网页序号由小到大
的顺序输出!
【样例输入】
假设search.exe为搜索引擎程序,以下面方式运行该程序:
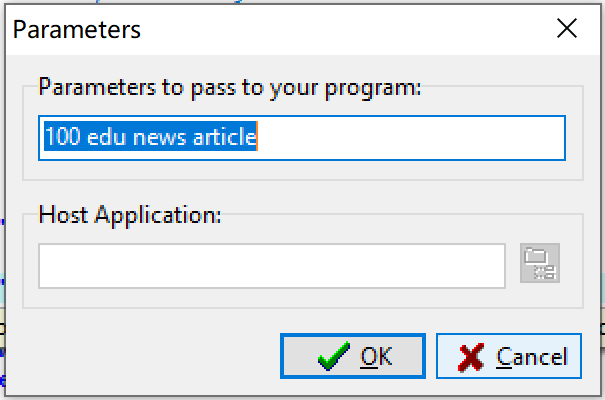
search 100 edu news article
(运行程序前,从课程网站下载区下载文件:article.txt, dictionary.txt, stopwords.txt, results(样例).txt到本地)
说明:若本地编程环境为dev-C++,可点击菜单Execute\Parameters…,在下面对话框中输入相应命令行参数。
【样例输出】
程序运行后,屏幕上输出Top-5的结果为:
0.581744 24 1-24
0.466224 230 1-230
0.447891 543 1-543
0.446951 54 1-54
0.440138 87 1-87
所生成的结果文件“results.txt”内容应与下载区文件“results(样例).txt”完全相同。
【样例说明】
样例屏幕输出为按相关度排序由高到低排名前5的结果。其中每一行第一部分为网页文档的相关度(Sim)值,第二部分为相应文档在文件中的序号,第三部分为文档在文件中的标识号。文件results.txt中为按相关度排序由高到低排名前100的结果。
【评分标准】
本综合功能测试题,其评分标准为通过测试数据即可得满分。程序运行无结果或结果错误将不得分。
思路分析
最开始的时候没有多思考,因为对于一个.c文件到底能开多大的数组不太确定(),索性放弃了思考,按照最简单的想法,开一个巨大的数组将dictionary中所有词存入数组,设置这样一个结构体,flag标记是否为stopword,之后对应的DNk,DNkd。。。各种量全部储存下来(好家伙,做完一看真是什么牛马都存下来了),结果费了半天劲,终于将代码写完,结果一编译,编译器直接报错为

这还是我第一次见这种错误,急忙上了百度搜了搜,不出所料是数组开大了,之后就卡住了,原有的思路根本没法应对这个,之后再群里讨教大佬,大佬为我仙人指路,告诉我Trie树是一条名路,从此我便踏上了Trie树的道路。
最开始对于Trie树的印象是完全由链式结构组成,结果上网一看大佬的操作才知道数组也能玩的这么花,但是当时总感觉时间紧任务重,没有时间来理解这个方法了,于是直接照着网上的模板copy了插入与查找操作,最开始不理解,用的都没自信,写了一段时间便没勇气写下去了。
但ddl是第一生产力,不得已又开始去写,后来逐渐意识到了统计的单词只需要关键词的数据,完全没必要将所有单词存下来
(实际上是舍友问我的时候我才看到的,属实是审题失误了)
,之后我将Words的组成缩减了,但是后来审视自己的代码时又发现完全没必要将Trie树变成结构体,这样[][26]中将会有大部分的空间是被浪费的,这时才反应过来可以变成[][28],前0~25号表示下一级的位置,26号表示关键词的位置,27号表示这是要统计的关键词,之后的操作就丝滑起来了。
可是,本地终于过了,交上去发现还是不对,我TM改了若干处才发现是命令行参数用错了,这才修成正果
(泪目了,蒟蒻的眼泪从嘴角滑了出来)
代码部分:(请求巨佬批评指正)
// pro1:Trie树确定索引位置; 用stopWord除去不该计算的词
// pro2:以文档为单位(N)记录每个单词的频次;
//##data:以结构体{TNkd,DNk,TFkd[pages],IDFk}来记录##ki的TNkd++,DNk++
// pro3:一篇文档结束后,计算TFkd,TNkd清0,读入文档时记录对应的文档数以及其网页序号;
// pro4:读完所有文档,
// pro5:计算IDFk,计算完计算Sim
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
#include <math.h>
#define PageSize 16000
#define WordSize 10000
struct node {
int TNkd, DNk;
double TFkd[PageSize];
double IDFk;
} Words[WordSize*10];
struct ednode {
char eno[10];
double sim;
int id;
} Pages[PageSize];
int Trie[4200000][28]; // flag为1说明
int num_word = 0, pos, num_page = 0;
int TNd[PageSize],NUM;
char arr[1024], s[35000000];
int search(char word[]) { //查找操作,在Trie树中找寻单词
int p = 0;
for (int i = 0; word[i]; i++) {
int ch = word[i] - 'a';
if (!Trie[p][ch]) {
return 0;
}
p = Trie[p][ch];
}
return p;
}
int cmp(const void *a, const void* b)
{
struct ednode *tmpa = (struct ednode*)a,*tmpb = (struct ednode*)b;
if(tmpa->sim < tmpb->sim) return 1;
else if(tmpa->sim > tmpb->sim) return -1;
else
{
return tmpa->id -tmpb->id;
}
}
int main(int argc, char *argv[]) {
//这一部分是将词典里的词录入到Trie树里,涉及插入操作,但这块的pos值特别大
FILE *dictionary = fopen("dictionary.txt", "r");
while (fscanf(dictionary, "%s", arr) != EOF) {
int p = 0, i;
for (i = 0; arr[i] != '\0'; i++) {
int ch = arr[i] - 'a';
if (!Trie[p][ch]) {
Trie[p][ch] = ++pos;
}
p = Trie[p][ch];
}
Trie[p][27] = 1; //用flag标记这个单词是词典中的词
}
fclose(dictionary);
//用stopwords里的单词在Trie树中寻找,找到的将flag变为0,以后就只统计flag为1的单词,涉及查找,用函数search
FILE *stopwords = fopen("stopwords.txt", "r");
while (fscanf(stopwords, "%s", arr) != EOF) {
int index = search(arr);
if (Trie[index][27])
Trie[index][27]= 0;
}
fclose(stopwords);
//读入ki部分
NUM = atoi(argv[1]);
for (int i = 2; i < argc; i++) {
int index = search(argv[i]);
if(Trie[index][27] == 1)
Trie[index][27] = 2;
}
//将所有内容读入到一个大树组中
FILE *article = fopen("article.txt", "r");
int c = fread(s, sizeof(char), 35000000, article);
fclose(article);
//读取article
char word[85]; //word是用来存储文档中的单词
for (int i = 0; i<c; i++) {
if (i == 0) { //将第一页的页码录入,存在数组Pages中,从0开始
int j;
for (j = i; s[j] != '\n'; j++) {
Pages[num_page].eno[j-i] = s[j];
}
Pages[num_page].id = num_page+1; //将第几页录入,方便以后排序后能确定正确的顺序
} else if ((s[i] <= 'z' && s[i] >= 'a') || (s[i] <= 'Z' && s[i] >= 'A')) {
int j;
for (j = i;(s[j] <= 'z' && s[j] >= 'a') || (s[j] <= 'Z' && s[j] >= 'A'); j++) {
word[j - i] = tolower(s[j]); //将单词都转换为小写单词
}
word[j-i]='\0';
i = j - 1;
int index = search(word); //找到Trie树中单词对应的位置index
if(Trie[index][27] == 1)
{
TNd[num_page]++;
}
else if (Trie[index][27] == 2) { //如果是这个单词是Ki,则在Words中输入该单词,actual对应的是实际单词在Words中的位置
Trie[index][27] = 3; //表示该单词不是第一次出现了
Trie[index][26] = num_word++; //actual对应的位置正是最后一位
if(Words[Trie[index][26]].TNkd == 0)
Words[Trie[index][26]].DNk++; // DNk++
Words[Trie[index][26]].TNkd++;//单词的TNkd++
TNd[num_page]++;
} else if (Trie[index][27] == 3) { //flag为3表示该单词不是第一次出现了,actual是单词在Words中的位置
if(Words[Trie[index][26]].TNkd == 0)
Words[Trie[index][26]].DNk++;
Words[Trie[index][26]].TNkd++;
TNd[num_page]++;
}
} else if (s[i] == '\f') { //一页结束,处理如下
int j;
for(j = 0; j < num_word;j++) //清算本页的TFkd,并将TNkd归0
{
Words[j].TFkd[num_page] = 100.0*Words[j].TNkd/TNd[num_page];
Words[j].TNkd = 0;
}
num_page++; //页码增加
for(j = i+1; !isdigit(s[j]);j++); //找到页码表示的位置
i = j;
for(j = i; s[j] != '\n';j++) //读入新页码
{
Pages[num_page].eno[j-i] = s[j];
}
Pages[num_page].id = num_page+1;
}
}
num_page++;
//计算部分
for(int i = 0; i < num_word;i++)
{
if(Words[i].DNk!=0)
Words[i].IDFk = log10(1.0*num_page/Words[i].DNk); //计算IDFk
}
for(int i=0;i< num_page;i++){
for(int j = 0; j< num_word;j++)
{
Pages[i].sim += 1.0*Words[j].TFkd[i]*Words[j].IDFk;//计算Sim
}
}
//输出部分
FILE *results = fopen("results.txt","w");
qsort(Pages,num_page,sizeof(Pages[0]),cmp);
for(int i = 0 ; i <NUM && i < num_page;i++)
{
fprintf(results,"%.6lf %d %s\n",Pages[i].sim,Pages[i].id,Pages[i].eno);
}
for(int i = 0; i < 5 && i <num_page;i++)
{
printf("%.6lf %d %s\n",Pages[i].sim,Pages[i].id,Pages[i].eno);
}
fclose(results);
return 0;
}