一、flink简介
1、基本概念介绍
flink是一个流数据与批数据一体化处理的模型,既可以处理有界数据流,也可以处理无界数据流, flink更擅长流数据处理,而spark更加擅长批处理;

flink是一个分层的模型,不同层解决不同的问题
Spark 和 Flink 这两个主流框架中选择一个来进行实时流处理,更加推荐使用 Flink,主要的原因有:
Flink 的延迟是毫秒级别,而 Spark Streaming 的延迟是秒级延迟。 Flink 提供了严格的精确一次性语义保证。 Flink 的窗口 API 更加灵活、语义更丰富。 Flink 提供事件时间语义,可以正确处理延迟数据。 Flink 提供了更加灵活的对状态编程的 API。
2、基本项目环境搭建
构建flink项目,需要引入的依赖增加标签设置属性,然后增加标签引入需要的依赖
包括 flink-java、flink-streaming-java,以及 flink-clients(客户端,也可以省略)
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>在属性中,定义了<scala.binary.version>,这指代的是所依赖的 Scala 版本。这有一点奇怪:Flink 底层是 Java,而且我们也只用 Java API,为什么还会依赖 Scala 呢?这是因为 Flink的架构中使用了 Akka 来实现底层的分布式通信,而 Akka 是用 Scala 开发的。
配置日志管理 在目录 src/main/resources 下添加文件:log4j.properties,内容配置如下: log4j.rootLogger=error, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
处理的方式包括流处理,这其中又有有界流–文件,无界流–监听某个socket,批处理–按某个文件直接批处理;
批处理代码demo:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//当 Lambda 表达式使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示的声明类型信息
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
流处理代码demo:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDSS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}批处理的结果:
(java,1) (flink,1) (world,1) (hello,3)
流处理的结果: 其中无界流监听socker也是这个结果
3> (world,1) 2> (hello,1) 4> (flink,1) 2> (hello,2) 2> (hello,3) 1> (java,1)
3、并行计算
任务并行和数据并行的概念:
任务并行是指不同的代码模块同时在处理不同的任务,数据并行是指同一个代码模块如何在同一时刻处理一类数据
在 Flink 执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
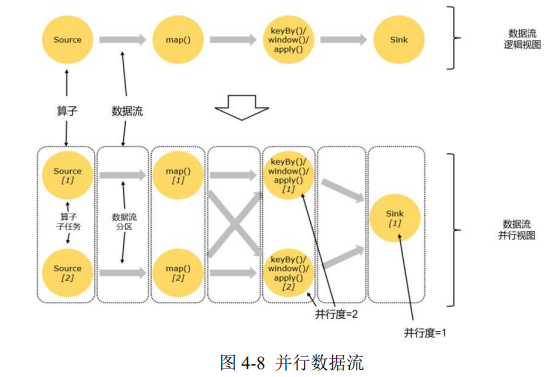
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流, 它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行 度。一个程序中,不同的算子可能具有不同的并行度。如图 4-8 所示,当前数据流中有 source、map、window、sink 四个算子, 除最后 sink,其他算子的并行度都为 2。整个程序包含了 7 个子任务,至少需要 2 个分区来并行执行。我们可以说,这段流处理 程序的并行度就是 2。
设置并行度的方式:
(1)代码中设置我们在代码中,可以很简单地在算子后跟着调用 setParallelism()方法,来设置当前算子的 并行度:stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2); 这种方式设置的并行度,只针对当前算子有效。另外,我们也可以直接调用执行环境的 setParallelism()方法,
全局设定并行度:env.setParallelism(2);这样代码中所有算子,默认的并行度就都为 2 了。我们一般不会在程序中设置全局
并行度,
因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。这里要注意的是,由于 keyBy 不是算子,所以无法对 keyBy
设置并行度。
(2)提交应用时设置
在使用 flink run 命令提交应用时,可以增加-p 参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置:
bin/flink run –p 2 –c com.atguigu.wc.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
如果我们直接在 Web UI 上提交作业,也可以在对应输入框中直接添加并行度。
(3)配置文件中设置
我们还可以直接在集群的配置文件 flink-conf.yaml 中直接更改默认并行度:parallelism.default: 2
这个设置对于整个集群上提交的所有作业有效,初始值为 1。无论在代码中设置、还是提交时的-p 参数,都不是必须的;
所以在没有指定并行度的时候,就会采用配置文件中的集群默认并行度。在开发环境中,没有配置文件,默认并行度就是
当前机器的 CPU 核心数。这也就解释了为什么我们在第二章运行 WordCount 流处理程序时,会看到结果前有 1~4 的分区
编号——运行程序的电脑是 4 核 CPU,那么开发环境默认的并行度就是 4。我们可以总结一下所有的并行度设置方法,
它们的优先级如下:
(1)对于一个算子,首先看在代码中是否单独指定了它的并行度,这个特定的设置优先级最高,会覆盖后面所有的设置。
(2)如果没有单独设置,那么采用当前代码中执行环境全局设置的并行度。
(3)如果代码中完全没有设置,那么采用提交时-p 参数指定的并行度。
(4)如果提交时也未指定-p 参数,那么采用集群配置文件中的默认并行度。
这里需要说明的是,算子的并行度有时会受到自身具体实现的影响。比如之前我们用到的读取 socket 文本流
的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么设置,它在运行时的并行度都是 1,
对应在数据流图上就只有一个并行子任务。这一点大家可以自行在 Web UI 上查看验证。那么实践中怎样设置并行度比较好呢?
那就是在代码中只针对算子设置并行度,不设置全局并行度,这样方便我们提交作业时进行动态扩容。
Flink 默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也 可以在代码中对算子做一些特定的设置:
// 禁用算子链 .map(word -> Tuple2.of(word, 1L)).disableChaining(); // 从当前算子开始新链 .map(word -> Tuple2.of(word, 1L)).startNewChain();
二、基础的DataStream API

一个flink程序,可以分为一下几个步骤:
获取执行环境(execution environment) 读取数据源(source) 定义基于数据的转换操作(transformations) 定义计算结果的输出位置(sink) 触发程序执行(execute)
1、获取执行环境 (图中第一步)
获取的执行环境,是StreamExecutionEnvironment 类的对象,这是所有 Flink 程序的基础。在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种。
1). getExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;
如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境;
2). createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数。
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3). createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment .createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
// 批处理环境 ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment(); // 流处理环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
设置执行模式:流执行模式(STREAMING)、批执行模式(BATCH)、自动(AUTOMATIC)
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。 主要有两种方式: (1)通过命令行配置 bin/flink run -Dexecution.runtime-mode=BATCH … 在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。 (2)通过代码配置 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);
用 BATCH 模式处理批量数据,用 STREAMING模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我 们没得选择——只有 STREAMING 模式才能处理持续的数据流。 Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”(lazy execution)。 所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。 env.execute();
2、原算子source,(图中第二步,获取数据源)
DataStream stream = env.addSource(…); 方法传入一个对象参数,需要实现 SourceFunction 接口;返回 DataStreamSource。
(1) 从集合中读取数据
ArrayList<Event> clicks = new ArrayList<>();
clicks.add(new Event("Mary","./home",1000L));
clicks.add(new Event("Bob","./cart",2000L));
DataStream<Event> stream = env.fromCollection(clicks);
stream.print();
env.execute();
DataStreamSource<Event> stream2 = env.fromElements(new Event("Mary", "./home", 1000L),new Event("Bob", "./cart", 2000L));
(2)从文件中读取
真正的实际应用中,自然不会直接将数据写在代码中。通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
DataStream stream = env.readTextFile(“clicks.csv”);
(3)从socket中读取
稳定性差用的少
DataStream stream = env.socketTextStream(“localhost”, 7777);
(4) 从kafka中读取
这个才是一般企业使用的方式。 与 Kafka 的连接比较复杂,Flink 内部并没有提供预实现的方法。所以我们只能采用通用的 addSource 方式、 实现一个SourceFunction 了。好在Kafka与Flink确实是非常契合,所以Flink官方提供了连接工具flink-connector-kafka, 直接帮我们实现了一个消费者 FlinkKafkaConsumer,它就是用来读取 Kafka 数据的SourceFunction。所以想要以 Kafka 作为 数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本 的Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka,读者使用时可以根据自己安装的 Kafka 版本选定连接器的依 赖版本。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class SourceKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>(
"clicks",
new SimpleStringSchema(),
properties));
stream.print("Kafka");
env.execute();
}
}
创建 FlinkKafkaConsumer 时需要传入三个参数:
第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic 列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据 时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条流中去。 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消 息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中 使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数 组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是 公共接口,所以我们也可以自定义反序列化逻辑。 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
(5)自定义 Source
在上面几种方式都不能满足的情况下,就会使用自定义source了个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()。 run()方法:使用运行时上下文对象(SourceContext)向下游发送数据; cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
3、转换算子
转换算子其实就是流式计算里面的一个个转换的api
(1)map映射
主要将数据流中的数据进行映射,形成新的数据流;方法需要传入的参数是
接口 MapFunction
的实现;返回值类型还是 DataStream,不过泛型(流中的元素类型)可能改 变。
// 传入匿名类,实现 MapFunction,匿名类中泛型的两个参数,一个是输入类型,一个是输出类型
stream.map(new MapFunction<Event, String>() {
@Override
public String map(Event e) throws Exception {
return e.user;
}
});
也可以是传入一个具体的类,同样需要实现MapFunction接口,并重写map方法
// 传入 MapFunction 的实现类 stream.map(new UserExtractor()).print();
public static class UserExtractor implements MapFunction<Event, String> {
@Override
public String map(Event e) throws Exception {
return e.user;
}
}
(2)filter过滤
对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉,
进行 filter 转换之后的新数据流的数据类型与原数据流是相同的。filter 转换需要传入的参数需要
实现 FilterFunction 接口
,而 FilterFunction 内要实现 filter()方法,就相当于一个返回布尔类型的条件表达式。泛型里面传入的参数就是原来流里面的数据类型event;
// 传入匿名类实现 FilterFunction,event是原来流里面元素的数据类型
stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
});
也可以将匿名内部类外置
// 传入 FilterFunction 实现类 stream.filter(new UserFilter()).print()
public static class UserFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
}
(3)扁平映射flatmap
主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten) 和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理;
同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。 flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出。希望输出结果时,只要调用收集器的.collect()方法就可以了;这个方法可以多次调 用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了简单的转换操作。
stream.flatMap(new MyFlatMap()).print();
public static class MyFlatMap implements FlatMapFunction<Event, String> {
/**
value 是输入事件类型
out是即收集器,里面的泛型是输出类型
*/
@Override
public void flatMap(Event value, Collector<String> out) throws Exception
{
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}
}
4、聚合算子
基本转换算子确实是在“转换”——因为它们都是基于当前数据,去做了处理和输出。而在实际应用中,我们往往需要对大量的数据进行统计或整合,从而提炼出更有用的信息。
(1) 按键分区(keyBy)
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。基于不同的 key,流中的数据将被分配到不同的分区中去,如图 5-8 所示;这样一来,所有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理了。
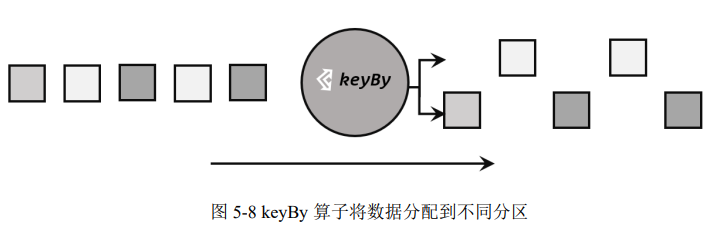
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组 key。有很多不同的方法来指定 key:比如对于 Tuple 数据类型,可以指定字段的位置或者多个位置的组合;对于 POJO 类型,可以指定字段的名称(String);另外,还可以传入 Lambda 表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取 key 的逻辑。
// 使用 Lambda 表达式
KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);
// 使用匿名类实现 KeySelector
KeyedStream<Event, String> keyedStream1 = stream.keyBy(new KeySelector<Event, String>() {
@Override
public String getKey(Event e) throws Exception {
return e.user;
}
});
需要注意的是,keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为KeyedStream。KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照key 的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外(event),还需要指定 key 的类型(string)。
(2)简单聚合
有了按键分区的数据流 KeyedStream,我们就可以基于它进行聚合操作了。Flink 为我们内置实现了一些最基本、最简单的聚合 API,主要有以下几种:
sum():在输入流上,对指定的字段做叠加求和的操作。 min():在输入流上,对指定的字段求最小值。 max():在输入流上,对指定的字段求最大值。 minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。 maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
而如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
stream.keyBy(e -> e.user).max(“timestamp”).print(); // 指定字段名称
(3) 归约聚合(reduce)
它可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。 与简单聚合类似,reduce 操作也会将 KeyedStream 转换为 DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。调用 KeyedStream 的 reduce 方法时,需要传入一个参数,实现 ReduceFunction 接口。接口在源码中的定义如下:
public interface ReduceFunction extends Function, Serializable { T reduce(T value1, T value2) throws Exception; }

5、富含数
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
一个常见的应用场景就是,如果我们希望连接到一个外部数据库进行读写操作,那么将连接操作放在 map()中显然不是个好选择——因为每来一条数据就会重新连接一次数据库;所以我们可以在 open()中建立连接,在 map()中读写数据,而在 close()中关闭连接。所以我们推荐 的最佳实践如下:
public class MyFlatMap extends RichFlatMapFunction<IN, OUT>> {
@Override
public void open(Configuration configuration) {
// 做一些初始化工作
// 例如建立一个和 MySQL 的连接
}
@Override
public void flatMap(IN in, Collector<OUT out) {
// 对数据库进行读写
}
@Override
public void close() {
// 清理工作,关闭和 MySQL 数据库的连接。
}
}
6、物理分区
前面的keyby是一种软分区,即逻辑上的分区,但是在物理层面被分到哪个区并不知道
物理分区与 keyBy 另一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变;
(1) 随机分区(shuffle)
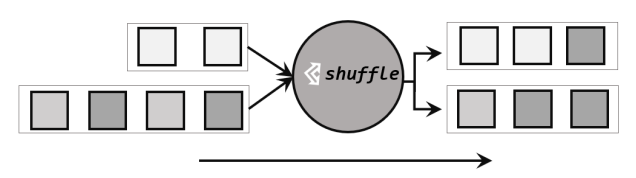
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。 随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,如图 5-9 所示。
因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
public class ShuffleTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 经洗牌后打印输出,并行度为 4
stream.shuffle().print("shuffle").setParallelism(4);
env.execute();
}
}
(2) 轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分 发。通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。rebalance 使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
// 经轮询重分区后打印输出,并行度为 4
stream.rebalance().print("rebalance").setParallelism(4);
(3) 重缩放分区(rescale)
(4)广播分区
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
// 经广播后打印输出,并行度为 4 stream. broadcast().print(“broadcast”).setParallelism(4);
(5) 全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所 有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行 度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
(6) 自定义分区(Custom)
当 Flink 提 供 的 所 有 分 区 策 略 都 不 能 满 足 用 户 的 需 求 时 , 我 们 可 以 通 过 使 用 partitionCustom()方法来自定义分区策略。 在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个 是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定, 也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
public class CustomPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
})
.print().setParallelism(2);
env.execute();
}
}
** 6、输出算子(Sink)**
输出算子是在flink中处理完数据之后,将数据输出出来
(1) 输出到文件
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly once)的一致性语义。
它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保 存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
行编码:StreamingFileSink.forRowFormat(basePath,rowEncoder)。 批量编码:StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)。 在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
public class SinkToFileTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
DataStreamSource<Event> stream = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
StreamingFileSink<String> fileSink = StreamingFileSin
// 传入的两个参数分别是路径和编码格式
.<String>forRowFormat(new Path("./output"), new SimpleStringEncoder<>("UTF-8"))
// 指定滚动策略
.withRollingPolicy(
// 包含了十五分钟的数据
DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
// 五分钟没有收到新的数据
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
// 文件大小到达1GB
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
// 将 Event 转换成 String 写入文件
stream.map(Event::toString).addSink(fileSink);
env.execute();
}
}
“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
至少包含 15 分钟的数据 最近 5 分钟没有收到新的数据 文件大小已达到 1 G
(2) 输出到kafka
flink作为生产者,将数据处理后直接将结果写入到kafka中
FlinkKafkaProducer 继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提 交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状态一致性。
Flink 从 Kakfa 的一个 topic 读取消费数据,然后进行处理转换,最终将结果数据写入 Kafka 的另一个 topic——数据从 Kafka 流入、经 Flink处理后又流回到 Kafka 去,这就是所谓的“数据管道”应用
public class SinkToKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");
// TODO flink处理数据
// 写出数据到kafka
stream.addSink(new FlinkKafkaProducer<String>("clicks",new SimpleStringSchema(),properties));
env.execute();
}
}
(3) 输出到redis
导入的 Redis 连接器依赖 <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.0</version> </dependency>
public class SinkToRedisTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 创建一个到 redis 连接的配置
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop102").build();
// 第一个参数是redis的连接配置,第二个参数是redis里面的映射规则,即写入到redis里面的每条消息,key和value的内容
env.addSource(new ClickSource()).addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
env.execute();
}
}
public static class MyRedisMapper implements RedisMapper<Event> {
// 每条消息都已user为key
@Override
public String getKeyFromData(Event e) {
return e.user;
}
// 以url为value
@Override
public String getValueFromData(Event e) {
return e.url;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "clicks");
}
}
保存到 Redis 时调用的命令是 HSET,所以是保存为哈希表(hash),表名为“clicks”;保存的数据以 user 为 key,以 url 为 value,每来一条数据就会做一次转换。
(4) 输出到mysql
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
(5)自定义输出
三、flink中的时间和窗口
“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。
水位线的特性:
水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展 水位线是基于数据的时间戳生成的 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进 水位线可以通过设置延迟,来保证正确处理乱序数据 一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据;
Flink 中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略
1、水位线
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间: public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy)
具体使用时,直接用 DataStream 调用该方法即可,与普通的 transform 方法完全一样。
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(<watermark strategy>);
.assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,这就是所谓的 “ 水位线生成策略 ” 。 WatermarkStrategy 中包含了一个 “ 时间戳分配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()。 onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳,以及允许发出水位线的一个 WatermarkOutput,可以基于事件做各种操作 onPeriodicEmit:周期性调用的方法,可以由 WatermarkOutput 发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置, 默认为200ms。 env.getConfig().setAutoWatermarkInterval(60 * 1000L);
2、窗口
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理, 这就是所谓的“窗口”(Window)。
窗口分为时间窗口和计数窗口
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能 应用。根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前, 是否有 keyBy 操作。
(1) 按键分区窗口
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),这
就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时
执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的
处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调
用.window()定义窗口。
stream.keyBy(...).window(...)
(2) 非按键分区
实际上就是没有调用keyby的数据流,这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。实际应用中一般不推荐使用
这种方式。
stream.windowAll(...)
代码中如何使用窗口:
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy() .window() .aggregate()
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。
(1) 窗口分配器
按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型 Flink
中都给出了内置的分配器实现,可以方便地调用实现各种需求。
(1)滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()。
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...);
(2)滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()。
stream.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).aggregate(...)
这里.of()方法需要传入两个 Time 类型的参数:size 和 slide,前者表示滑动窗口的大小,
后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
(3) 滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。
stream.keyBy(...).countWindow(10)
我们定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发
计算执行并关闭窗口。
(4)滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size 和 slide,前
者表示窗口大小,后者表示滑动步长。
stream.keyBy(...).countWindow(10,3);
我们定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每
隔 3 个数据就统计输出一次结果。
(5). 全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调
用.window(),分配器由 GlobalWindows 类提供。
stream.keyBy(...).window(GlobalWindows.create());
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
(2) 窗口函数
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类
型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须
进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream
- 增量聚合函数
窗口将无界数据转换成了有界数据,但是并不是收集齐了这个窗口里面的所有数据之后,才开始处理,而是跟流式处理一样,来一条处理一条 就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
(1)归约函数(ReduceFunction)
public class WindowReduceExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>()
{
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
// 将数据转换成二元组,方便计算
return Tuple2.of(value.user, 1L);
}
})
.keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1,
Tuple2<String, Long> value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
.print();
env.execute();
}
}