1.基本分词函数与用法
# jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode)
#
# jieba.cut 方法接受三个输入参数:
#
# 需要分词的字符串
# cut_all 参数用来控制是否采用全模式
# HMM 参数用来控制是否使用 HMM 模型
# jieba.cut_for_search 方法接受两个参数
#
# 需要分词的字符串
# 是否使用 HMM 模型。
# 该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
#jieba中文文本处理
# encoding=utf-8
import jieba
#jieba.cut和jieba.cut_for_search:返回的是一个可迭代的genertor,可使用for循环获得分词后的每一个词语。
seg_list = jieba.cut("我在学习自然语言处理", cut_all=True)
#print (seg_list)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我在学习自然语言处理", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他毕业于上海交通大学,在百度深度学习研究院进行研究") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造") # 搜索引擎模式
print(", ".join(seg_list))
#jieba.lcut以及jieba.lcut_for_search直接返回 list
result_lcut = jieba.lcut("小明硕士毕业于中国科学院计算所,后在哈佛大学深造")
print(result_lcut)
print (" ".join(result_lcut))
print (" ".join(jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在哈佛大学深造")))
#专业领域的分词处理:
# 添加用户自定义词典
# 很多时候我们需要针对自己的场景进行分词,会有一些领域内的专有词汇。
#
# 1.可以用jieba.load_userdict(file_name)加载用户字典
# 2.少量的词汇可以自己用下面方法手动添加:
# 用 add_word(word, freq=None, tag=None) 和 del_word(word) 在程序中动态修改词典
# 用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
print('/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))
jieba.suggest_freq(('中', '将'), True)
print('/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))

2.关键词提取
2.1基于 TF-IDF 算法的关键词抽取
# 关键词提取
# 基于 TF-IDF 算法的关键词抽取
# import jieba.analyse
#
# jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
# sentence 为待提取的文本
# topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
# withWeight 为是否一并返回关键词权重值,默认值为 False
# allowPOS 仅包括指定词性的词,默认值为空,即不筛选
import jieba.analyse as analyse
#以下代码犯过错误:1.文件路径问题 2.编码问题,txt为gbk格式文件,需要先转化为utf-8格式,才能拿过来用。
lines = open('E:/DMtest/Jupytertest/NBA.txt',encoding='utf-8').read()
print (" ".join(analyse.extract_tags(lines, topK=20, withWeight=False, allowPOS=())))
#注意:以下文件操作出项过错误:txt自身文件不为utf-8时,需要采用另存为的方式改为utf-8
lines1 = open('E:/DMtest/Jupytertest/西游记.txt',encoding='utf-8').read()
print (" ".join(analyse.extract_tags(lines1, topK=20, withWeight=False, allowPOS=())))

import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open('人民的名义.txt','r',encoding='utf-8').read()
tags = jieba.analyse.extract_tags(content,topK=10)
print(",".join(tags))

2.2关于TF-IDF 算法的关键词抽取补充
基本概念理解:
背景
:有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
词频:停用词:逆文档频率:
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行
“词频”(Term Frequency,缩写为TF)
统计。结果你肯定猜到了,出现次数最多的词是—-“的”、”是”、”在”—-这一类最常用的词。它们叫做
“停用词”(stop words)
,表示对找到结果毫无帮助、必须过滤掉的词。假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现
”中国”、”蜜蜂”、”养殖”
这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?显然不是这样。因为”中国”是很常见的词,相对而言,”蜜蜂”和”养殖”不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂”和”养殖”的重要程度要大于”中国”,也就是说,在关键词排序上面,”蜜蜂”和”养殖”应该排在”中国”的前面。所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。用统计学语言表达,就是在词频的基础上,要对每个词分配一个”重要性”权重。最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做”
逆文档频率”(Inverse Document Frequency,缩写为IDF)
,它的大小与一个词的常见程度成反比。知道了
”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值
。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
计算:
第一步,计算词频。
![]()
考虑到文章有长短之分,为了便于不同文章的比较,进行”词频”标准化,这样就使用一个比例来减少了每篇文章数量不一致的影响。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。附一个wiki百科对数的链接
第三步,计算TF-IDF。
![]()
可以看到,
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比
。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例
劳动防护 13.900677652 勞動防護 13.900677652 生化学 13.900677652 生化學 13.900677652 奥萨贝尔 13.900677652 奧薩貝爾 13.900677652 考察队员 13.900677652 考察隊員 13.900677652 岗上 11.5027823792 崗上 11.5027823792 倒车档 12.2912397395 倒車檔 12.2912397395 编译 9.21854642485 編譯 9.21854642485 蝶泳 11.1926274509 外委 11.8212361103
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open('idf.txt.big','r',encoding='utf-8').read()
tags = jieba.analyse.extract_tags(content, topK=10)
print(",".join(tags))

关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:
!
"
#
$
%
&
'
(
)
*
+
,
-
--
.
..
...
......
...................
./
.一
记者
数
年
月
日
时
分
秒
/
//
0
1
2
3
4
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open(u'人民的名义.txt','r',encoding='utf-8').read()
jieba.analyse.set_stop_words("stopwords.txt")
tags = jieba.analyse.extract_tags(content, topK=10)
print(",".join(tags))

关键词一并返回关键词权重值示例
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open(u'人民的名义.txt','r',encoding='utf-8').read()
jieba.analyse.set_stop_words("stopwords.txt")
tags = jieba.analyse.extract_tags(content, topK=10,withWeight=True)
for tag in tags:
print("tag:%s\t\t weight:%f"%(tag[0],tag[1]))
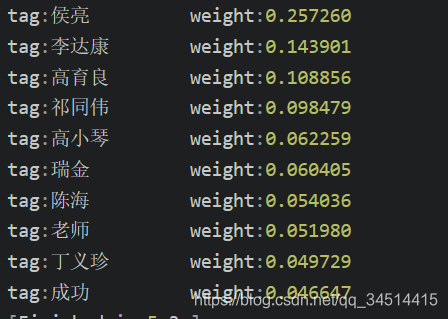
2.3.基于 TextRank 算法的关键词抽取
1.基本介绍:
TextRank 算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要。本文介绍了抽取型文本摘要算法TextRank,并使用Python实现TextRank算法在多篇单领域文本数据中抽取句子组成摘要的应用。
文本摘要可以大致分为两类——抽取型摘要和抽象型摘要:
-
抽取型摘要:这种方法依赖于从文本中提取几个部分,例如短语、句子,把它们堆叠起来创建摘要。因此,这种抽取型的方法最重要的是识别出适合总结文本的句子。
-
抽象型摘要:这种方法应用先进的NLP技术生成一篇全新的总结。可能总结中的文本甚至没有在原文中出现。
本文,我们将关注于抽取式摘要方法。
2.引入:
在开始使用TextRank算法之前,我们还应该熟悉另一种算法——PageRank算法。事实上它启发了TextRank!PageRank主要用于对在线搜索结果中的网页进行排序。让我们通过一个例子快速理解这个算法的基础。
PageRank算法简介:
图 1 PageRank算法
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
-
w1有指向w2、w4的链接
-
w2有指向w3和w1的链接
-
w4仅指向w1
-
w3没有指向的链接,因此为悬空页面
为了对这些页面进行排名,我们必须计算一个称为PageRank的分数。这个分数是用户访问该页面的概率。
为了获得用户从一个页面跳转到另一个页面的概率,我们将创建一个正方形矩阵M,它有n行和n列,其中n是网页的数量。
矩阵中得每个元素表示从一个页面链接进另一个页面的可能性。比如,如下高亮的方格包含的是从w1跳转到w2的概率。
如下是概率初始化的步骤:
1. 从页面i连接到页面j的概率,也就是M[i][j],初始化为1/页面i的出链接总数wi
2. 如果页面i没有到页面j的链接,那么M[i][j]初始化为0
3. 如果一个页面是悬空页面,那么假设它链接到其他页面的概率为等可能的,因此M[i][j]初始化为1/页面总数
因此在本例中,矩阵M初始化后如下:
最后,这个矩阵中的值将以迭代的方式更新,以获得网页排名。
3.
TextRank算法
现在我们已经掌握了PageRank,让我们理解TextRank算法。我列举了以下两种算法的相似之处:
-
用句子代替网页
-
任意两个句子的相似性等价于网页转换概率
-
相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
1. 第一步是把所有文章整合成文本数据
2. 接下来把文本分割成单个句子
3. 然后,我们将为每个句子找到向量表示(词向量)。
4. 计算句子向量间的相似性并存放在矩阵中
5. 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
6. 最后,一定数量的排名最高的句子构成最后的摘要。
4.实践
我决定设计一个系统,通过扫描多篇文章为我提供一个要点整合的摘要。如何着手做这件事?这就是我将在本教程中向大家展示的内容。我们将在一个爬取得到的文章集合的文本数据集上应用TextRank算法,以创建一个漂亮而简洁的文章摘要。
数据集下载链接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
import numpy as np
import pandas as pd
import nltk
# 理解nltk.download('punkt'):
# 要下载特定的数据集/模型,请使用nltk.download()函数,例如如果您要下载punkt句子标记生成器,请使用:
# $python3
# >>> import nltk
# >>> nltk.download('punkt')
nltk.download('punkt')
import re
#读取数据
df=pd.read_csv('tennis_articles_v4.csv')
#输出,查看数据
print(df.head())
print(df['article_text'][0])
print(df['article_text'][1])
print(df['article_text'][2])
#将文本分割为单个句子
from nltk.tokenize import sent_tokenize
sentences=[]
for s in df['article_text']:
sentences.append(sent_tokenize(s))
sentences=[y for x in sentences for y in x]
#打印查看:
print('sentences[:5]')
# GloVe词向量是单词的向量表示。这些词向量将用于生成表示句子的特征向量。我们也可以使用Bag-of-Words或TF-IDF方法来为句子生成特征,但这些方法忽略了单词的顺序,并且通常这些特征的数量非常大。
# 我们将使用预训练好的Wikipedia 2014 + Gigaword 5 (补充链接)GloVe向量,文件大小是822 MB。
# GloVe词向量下载链接:
# https://nlp.stanford.edu/data/glove.6B.zip
#提取词向量:
word_embeddings={}
f=open('glove.6B.100d.txt',encoding='utf-8')
for line in f:
values=line.split()
word=values[0]
coefs=np.asarray(values[1:],dtype='float32')
word_embeddings[word]=coefs
f.close()
print(len(word_embeddings))
#文本预处理:
#尽可能减少文本数据的噪声是一个好习惯,所以我们做一些基本的文本清洗(包括移除标点符号、数字、特殊字符,统一成小写字母)。
clean_sentences=pd.Series(sentences).str.replace("[^a-zA-Z]"," ")
clean_sentences=[s.lower() for s in clean_sentences]
#去掉句子中出现的停用词(一种语言的常用词——is,am,of,in等)。如果尚未下载nltk-stop,则执行以下代码行:
nltk.download('stopwords')
#导入停用词:
from nltk.corpus import stopwords
stopwords=stopwords.words('english')
#定义移除我们的数据集中停用词的函数
def remove_stopwords(sen):
sen_new=" ".join([i for i in sen if i not in stopwords])
return sen_new
#将在GloVe词向量的帮助下用clean_sentences(程序中用来保存句子的列表变量)来为我们的数据集生成特征向量。
clean_sentences=[remove_stopwords(r.split()) for r in clean_sentences]
#句子的特征向量
#现在,来为我们的句子生成特征向量。我们首先获取每个句子的所有组成词的向量(从GloVe词向量文件中获取,每个向量大小为100个元素),然后取这些向量的平均值,得出这个句子的合并向量为这个句子的特征向量。
sentence_vectors=[]
for i in clean_sentences:
if len(i) != 0:
v=sum([word_embeddings.get(w,np.zeros((100,))) for w in i.split()])/(len(i.split())+0.001)
else:
v=np.zeros((100,))
sentence_vectors.append(v)
#相似矩阵准备
#下一步是找出句子之间的相似性,我们将使用余弦相似性来解决这个问题。让我们为这个任务创建一个空的相似度矩阵,并用句子的余弦相似度填充它。
#首先定义一个n乘n的零矩阵,然后用句子间的余弦相似度填充矩阵,这里n是句子的总数。
sim_mat=np.zeros([len(sentences),len(sentences)])
#用余弦相似度计算两个句子之间的相似度。
from sklearn.metrics.pairwise import cosine_similarity
#用余弦相似度初始化这个相似度矩阵。
for i in range(len(sentences)):
for j in range(len(sentences)):
if i!=j:
sim_mat[i][j]=cosine_similarity(sentence_vectors[i].reshape(1,100),sentence_vectors[j].reshape(1,100))[0,0]
# 应用PageRank算法
#
# 在进行下一步之前,我们先将相似性矩阵sim_mat转换为图结构。这个图的节点为句子,边用句子之间的相似性分数表示。在这个图上,我们将应用PageRank算法来得到句子排名。
import networkx as nx
nx_graph=nx.from_numpy_array(sim_mat)
scores=nx.pagerank(nx_graph)
# 摘要提取
# 最后,根据排名提取前N个句子,就可以用于生成摘要了。
ranked_sentences=sorted(((scores[i],s) for i,s in enumerate(sentences)),reverse=True)
for i in range(10):
print(ranked_sentences[i][1])结果显示:
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\帅比\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
article_id ... source
0 1 ... https://www.tennisworldusa.org/tennis/news/Mar...
1 2 ... http://www.tennis.com/pro-game/2018/10/copil-s...
2 3 ... https://scroll.in/field/899938/tennis-roger-fe...
3 4 ... http://www.tennis.com/pro-game/2018/10/nishiko...
4 5 ... https://www.express.co.uk/sport/tennis/1036101...
[5 rows x 3 columns]
Maria Sharapova has basically no friends as tennis players on the WTA Tour. The Russian player has no problems in openly speaking about it and in a recent interview she said: 'I don't really hide any feelings too much. I think everyone knows this is my job here. When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match. I'm a pretty competitive girl. I say my hellos, but I'm not sending any players flowers as well. Uhm, I'm not really friendly or close to many players. I have not a lot of friends away from the courts.' When she said she is not really close to a lot of players, is that something strategic that she is doing? Is it different on the men's tour than the women's tour? 'No, not at all. I think just because you're in the same sport doesn't mean that you have to be friends with everyone just because you're categorized, you're a tennis player, so you're going to get along with tennis players. I think every person has different interests. I have friends that have completely different jobs and interests, and I've met them in very different parts of my life. I think everyone just thinks because we're tennis players we should be the greatest of friends. But ultimately tennis is just a very small part of what we do. There are so many other things that we're interested in, that we do.'
BASEL, Switzerland (AP), Roger Federer advanced to the 14th Swiss Indoors final of his career by beating seventh-seeded Daniil Medvedev 6-1, 6-4 on Saturday. Seeking a ninth title at his hometown event, and a 99th overall, Federer will play 93th-ranked Marius Copil on Sunday. Federer dominated the 20th-ranked Medvedev and had his first match-point chance to break serve again at 5-1. He then dropped his serve to love, and let another match point slip in Medvedev's next service game by netting a backhand. He clinched on his fourth chance when Medvedev netted from the baseline. Copil upset expectations of a Federer final against Alexander Zverev in a 6-3, 6-7 (6), 6-4 win over the fifth-ranked German in the earlier semifinal. The Romanian aims for a first title after arriving at Basel without a career win over a top-10 opponent. Copil has two after also beating No. 6 Marin Cilic in the second round. Copil fired 26 aces past Zverev and never dropped serve, clinching after 2 1/2 hours with a forehand volley winner to break Zverev for the second time in the semifinal. He came through two rounds of qualifying last weekend to reach the Basel main draw, including beating Zverev's older brother, Mischa. Federer had an easier time than in his only previous match against Medvedev, a three-setter at Shanghai two weeks ago.
Roger Federer has revealed that organisers of the re-launched and condensed Davis Cup gave him three days to decide if he would commit to the controversial competition. Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of any commitment. "They only left me three days to decide", Federer said. "I didn't to have time to consult with all the people I had to consult. "I could not make a decision in that time, so I told them to do what they wanted." The 20-time Grand Slam champion has voiced doubts about the wisdom of the one-week format to be introduced by organisers Kosmos, who have promised the International Tennis Federation up to $3 billion in prize money over the next quarter-century. The competition is set to feature 18 countries in the November 18-24 finals in Madrid next year, and will replace the classic home-and-away ties played four times per year for decades. Kosmos is headed by Barcelona footballer Gerard Pique, who is hoping fellow Spaniard Rafael Nadal will play in the upcoming event. Novak Djokovic has said he will give precedence to the ATP's intended re-launch of the defunct World Team Cup in January 2020, at various Australian venues. Major players feel that a big event in late November combined with one in January before the Australian Open will mean too much tennis and too little rest. Federer said earlier this month in Shanghai in that his chances of playing the Davis Cup were all but non-existent. "I highly doubt it, of course. We will see what happens," he said. "I do not think this was designed for me, anyhow. This was designed for the future generation of players." Argentina and Britain received wild cards to the new-look event, and will compete along with the four 2018 semi-finalists and the 12 teams who win qualifying rounds next February. "I don't like being under that kind of pressure," Federer said of the deadline Kosmos handed him.
sentences[:5]
400000
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\帅比\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match.
Major players feel that a big event in late November combined with one in January before the Australian Open will mean too much tennis and too little rest.
Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of any commitment.
"I felt like the best weeks that I had to get to know players when I was playing were the Fed Cup weeks or the Olympic weeks, not necessarily during the tournaments.
Currently in ninth place, Nishikori with a win could move to within 125 points of the cut for the eight-man event in London next month.
He used his first break point to close out the first set before going up 3-0 in the second and wrapping up the win on his first match point.
The Spaniard broke Anderson twice in the second but didn't get another chance on the South African's serve in the final set.
"We also had the impression that at this stage it might be better to play matches than to train.
The competition is set to feature 18 countries in the November 18-24 finals in Madrid next year, and will replace the classic home-and-away ties played four times per year for decades.
Federer said earlier this month in Shanghai in that his chances of playing the Davis Cup were all but non-existent.
Process finished with exit code 0
实践总结:
1.导入所需要的库
2.读入数据
3.检查数据
4.将文本分割成句子
5.下载GloVe词汇量
GloVe词向量下载链接:
https://nlp.stanford.edu/data/glove.6B.zip
6.文本预处理
7.句子特征向量处理
8.相似矩阵准备
9.应用PageRank算法
10.提取摘要
拓展待研究:
1. 问题导向:
-
多领域文本摘要
-
单个文档的摘要
-
跨语言文本摘要
(文本来源是一种语言,文本总结用另一种语言)
2. 算法导向:
-
应用RNN和LSTM的文本摘要
-
应用加强学习的文本摘要
-
应用生成对抗神经网络(GAN)的文本摘要
3.词性标注
# jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
# 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
# 具体的词性对照表参见计算所汉语词性标记集
import jieba.posseg as pseg
words = pseg.cut("我爱自然语言处理")
for word, flag in words:
print('%s %s' % (word, flag))
我 r
爱 v
自然语言 l
处理 v
计算所汉语词性标记集
Version 3.0
0. 说明
计算所汉语词性标记集(共计99个,22个一类,66个二类,11个三类)主要用于中国科学院计算技术研究所研制的汉语词法分析器、句法分析器和汉英机器翻译系统。本标记集主要参考了以下词性标记集:
1. 北大《人民日报》语料库词性标记集;
2. 北大2002新版词性标记集(草稿);
3. 清华大学汉语树库词性标记集;
4. 教育部语用所词性标记集(国家推荐标准草案2002版);
5. 美国宾州大学中文树库(ChinesePennTreeBank)词性标记集;
由于计算所的汉语词法分析器主要采用北大《人民日报》语料库进行参数训练,因此本
词性标记集主要以北大《人民日报》语料库的词性标记集为蓝本,并参考了北大《汉语语法信息词典》中给出的汉语词的语法信息。
本标记集在制定过程中主要考虑了以下几方面的因素:
1. 有助于提高汉语词法分析器的切分和标注正确率;
2. 有助于提高汉语句法分析器的正确率;
3. 有助于汉英机器翻译系统进行翻译;
4. 易于从北大《人民日报》语料库词性标记集进行转换;
5. 对于语法功能不同的词,在不造成词法分析和句法分析歧义区分困难的情况下,尽可能细分子类。
基于以上考虑,我们在标注过程中尽量避免那些容易出错的词性标记,而采用那些不容易出错、而对提高汉语词法句法分析正确率有明显作用的标记。例如,在动词的子类中,我们参考了宾州大学中文树库的做法,把汉语动词“是”和“有”分别做成单独的标记,而没有采用“系动词”的标记。因为同样是“是”这个动词,其句法功能很多,作“系动词”只是其中一种功能,而要区分这些功能是非常困难的,会导致词法分析的正确率下降。
在名词子类中,我们区分了“汉语人名”、“日语人名”和“翻译人名”,这不仅仅是因为这三种人名要采用不同的参数进行训练与识别,而且在汉英机器翻译中也要采用不同的分析算法进行翻译。又如,我们把表示时间的“数词+‘年’”(如“1995年”)合并成一个时间词,而表示年头的“数词+‘年’”分别标注为“数词”和“量词”,这是因为我们通过实验发现这种区分在词法分析阶段通过统计方法可以达到较高的正确率,而且这种区分对于后续的句法分析和机器翻译有非常重要的作用。
对于某些词类(助词和标点符号),基本上是一个封闭集,而这些词类中各个词的语法功能相差很大,在这种情况下,我们尽可能地细分其子类。
另外,与其他词性标记集类似,在我们的标记体系中,小类只是大类中一些有必要区分的一些特例,但小类的划分不满足完备性。
1. 名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
2. 时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
. 处所词(1个一类)
s 处所词
4. 方位词(1个一类)
f 方位词
5. 动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
6. 形容词(1个一类,4个二类)
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
7. 区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
8. 状态词(1个一类)
z 状态词
9. 代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
10. 数词(1个一类,1个二类)
m 数词
mq 数量词
11.量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
12. 副词(1个一类)
d 副词
13.介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
14. 连词(1个一类,1个二类)
c 连词
cc 并列连词
15. 助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
16. 叹词(1个一类)
e 叹词
17. 语气词(1个一类)
y 语气词(delete yg)
18. 拟声词(1个一类)
o 拟声词
19.前缀(1个一类)
h 前缀
20. 后缀(1个一类)
k 后缀
21. 字符串(1个一类,2个二类)
x 字符串
xe Email字符串
xs 微博会话分隔符
xm 表情符合
xu 网址URL
22.标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:―― -- ――- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$
4.并行分词
【本部分未进行实践:(设备有要求)】
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
注意:并行分词仅支持默认分词器 jieba.dt 和 jieba.posseg.dt。
import sys
import time
import jieba
jieba.enable_parallel()
content = open(u'西游记.txt',"r").read()
t1 = time.time()
words = "/ ".join(jieba.cut(content))
t2 = time.time()
tm_cost = t2-t1
print('并行分词速度为 %s bytes/second' % (len(content)/tm_cost))
jieba.disable_parallel()
content = open(u'西游记.txt',"r").read()
t1 = time.time()
words = "/ ".join(jieba.cut(content))
t2 = time.time()
tm_cost = t2-t1
print('非并行分词速度为 %s bytes/second' % (len(content)/tm_cost))
5.Tokenize:返回词语在原文的起止位置
#注意,输入参数只接受 unicode
import jieba
print ("这是默认模式的tokenize")
result = jieba.tokenize(u'自然语言处理非常有用')
for tk in result:
print("%s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
print ("\n-----------我是神奇的分割线------------\n")
print ("这是搜索模式的tokenize")
result = jieba.tokenize(u'自然语言处理非常有用', mode='search')
for tk in result:
print("%s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))这是默认模式的tokenize
自然语言 start: 0 end:4
处理 start: 4 end:6
非常 start: 6 end:8
有用 start: 8 end:10
-----------我是神奇的分割线------------
这是搜索模式的tokenize
自然 start: 0 end:2
语言 start: 2 end:4
自然语言 start: 0 end:4
处理 start: 4 end:6
非常 start: 6 end:8
有用 start: 8 end:10
6.ChineseAnalyzer for Whoosh 搜索引擎
from jieba.analyse import ChineseAnalyzer
# -*- coding: UTF-8 -*-
from __future__ import unicode_literals
import sys,os
sys.path.append("../")
from whoosh.index import create_in,open_dir
from whoosh.fields import *
from whoosh.qparser import QueryParser
analyzer = jieba.analyse.ChineseAnalyzer()
schema = Schema(title=TEXT(stored=True), path=ID(stored=True), content=TEXT(stored=True, analyzer=analyzer))
if not os.path.exists("tmp"):
os.mkdir("tmp")
ix = create_in("tmp", schema) # for create new index
#ix = open_dir("tmp") # for read only
writer = ix.writer()
writer.add_document(
title="document1",
path="/a",
content="This is the first document we’ve added!"
)
writer.add_document(
title="document2",
path="/b",
content="The second one 你 中文测试中文 is even more interesting! 吃水果"
)
writer.add_document(
title="document3",
path="/c",
content="买水果然后来世博园。"
)
writer.add_document(
title="document4",
path="/c",
content="工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"
)
writer.add_document(
title="document4",
path="/c",
content="咱俩交换一下吧。"
)
writer.commit()
searcher = ix.searcher()
parser = QueryParser("content", schema=ix.schema)
for keyword in ("水果世博园","你","first","中文","交换机","交换"):
print(keyword+"的结果为如下:")
q = parser.parse(keyword)
results = searcher.search(q)
for hit in results:
print(hit.highlights("content"))
print("\n--------------我是神奇的分割线--------------\n")
for t in analyzer("我的好朋友是李明;我爱北京天安门;IBM和Microsoft; I have a dream. this is intetesting and interested me a lot"):
print(t.text)水果世博园的结果为如下:
买<b class="match term0">水果</b>然后来<b class="match term1">世博园</b>
--------------我是神奇的分割线--------------
你的结果为如下:
second one <b class="match term0">你</b> 中文测试中文 is even more interesting
--------------我是神奇的分割线--------------
first的结果为如下:
<b class="match term0">first</b> document we’ve added
--------------我是神奇的分割线--------------
中文的结果为如下:
second one 你 <b class="match term0">中文</b>测试<b class="match term0">中文</b> is even more interesting
--------------我是神奇的分割线--------------
交换机的结果为如下:
干事每月经过下属科室都要亲口交代24口<b class="match term0">交换机</b>等技术性器件的安装工作
--------------我是神奇的分割线--------------
交换的结果为如下:
咱俩<b class="match term0">交换</b>一下吧
干事每月经过下属科室都要亲口交代24口<b class="match term0">交换</b>机等技术性器件的安装工作
--------------我是神奇的分割线--------------
我
好
朋友
是
李明
我
爱
北京
天安
天安门
ibm
microsoft
dream
intetest
interest
me
lot
7.命令行分词
使用示例:python -m jieba news.txt > cut_result.txt
命令行选项(翻译):
使用: python -m jieba [options] filename
结巴命令行界面。
固定参数:
filename 输入文件
可选参数:
-h, --help 显示此帮助信息并退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的' / '。
若不指定 DELIM,则使用一个空格分隔。
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替默认词典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用
-a, --cut-all 全模式分词(不支持词性标注)
-n, --no-hmm 不使用隐含马尔可夫模型
-q, --quiet 不输出载入信息到 STDERR
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。
--help 选项输出:
$> python -m jieba --help
Jieba command line interface.
positional arguments:
filename input file
optional arguments:
-h, --help show this help message and exit
-d [DELIM], --delimiter [DELIM]
use DELIM instead of ' / ' for word delimiter; or a
space if it is used without DELIM
-p [DELIM], --pos [DELIM]
enable POS tagging; if DELIM is specified, use DELIM
instead of '_' for POS delimiter
-D DICT, --dict DICT use DICT as dictionary
-u USER_DICT, --user-dict USER_DICT
use USER_DICT together with the default dictionary or
DICT (if specified)
-a, --cut-all full pattern cutting (ignored with POS tagging)
-n, --no-hmm don't use the Hidden Markov Model
-q, --quiet don't print loading messages to stderr
-V, --version show program's version number and exit
If no filename specified, use STDIN instead.