K-means算法(非监督性学习)
1.算法思想
k-means
算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的
K
个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含
n
个
d
维数据点的数据集
X
以及要分得的类别
K,
选取欧式距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即最小化
:
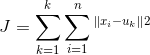
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
2.算法流程
K-means
是一个反复迭代的过程,算法分为四个步骤:
1
) 选取数据空间中的
K
个对象作为初始中心,每个对象代表一个聚类中心;
2
) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3
) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4
) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回
2
)。
3.算法的优缺点
K
-Means
擅长处理球状分布的数据,当结果聚类是密集的,而且类和类之间的区别比较明显时,
K
均值的效果比较好。对于处理大数据集,这个算法是相对可伸缩的和高效的,它的复杂度是
O(
nkt
),n
是对象的个数,
k
是簇的数目,
t
是迭代的次数。相比其他的聚类算法
,
K
-Means
比较简单、容易掌握,这也是其得到广泛使用的原因之一
。
但
K
-Means
算法也存在一些问题。
(
1
)算法的初始中心点选择与算法的运行效率密切相关,而随机选取中心点有可能导致迭代次数很大或者限于某个局部最优状态;通常
k<<n,
且
t<<n
,所以算法经常以局部最优收敛。
(
2
)
K
均值
的最大问题是要求用户必须事先给出
k
的个数,
k
的选择一般都基于一些经验值和多次试验的结果,对于不同的数据集,
k
的取值没有可借鉴性。
(
3
)对异常偏离的数据敏感
——
离群点
;
K
均值
对“噪声”和孤立点数据是敏感的,少量的这类数据就能对平均值造成极大的影响。