一、地产数据爬取
原创代码,打个标签,便于自己以后整理。
1、数据来源
数据来源为浙报传媒地产研究院的网上数据,
红色标注区段改写后
,可用于提取不同地市、不同时段的房地产土地交易数据,用于深入分析。
2、数据爬取
采用requests进行数据爬取,需要注意对异常数据的处理。本代码中采用try进行流拍、中止交易处理。

from bs4 import BeautifulSoup
import requests
import urllib3
import re
import csv
import os
from urllib.parse import urljoin,urlparse#检查URL地址
def check_link(url):
header= {‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36′}
r=requests.get(url=url,headers=header) #查看网页源代码 document.charset
return(r.text)#爬取资源
def get_contents(ulist,rurl):
soup=BeautifulSoup(rurl,’html.parser’)
table=soup.find(‘table’) #找到包含数据的表格
#print(table)
trs=table.find_all(‘tr’)
for tr in trs:
ui=[]
for td in tr:
ui.append(td.string)
ulist.append(ui)
for list in ulist:
print(list)#保存资源
def save_contents(file_path,file_name,urlist):
if not os.path.exists(file_path):#是否存在文件夹,不存在就创建
os.makedirs(file_path)
path=file_path+os.path.sep+'{file_name}’.format(file_name=file_name+”.csv”)
with open(path,”w”,newline=”) as f:
writer=csv.writer(f)
writer.writerow([‘嘉兴土地交易状况’])
ge=[‘中止’,’流拍’]
try:
for i in range(len(urlist)):
if urlist[i][13] not in ge:
writer.writerow([urlist[i][1],urlist[i][3],urlist[i][5],urlist[i][7],urlist[i][9],urlist[i][11],urlist[i][13],urlist[i][15],urlist[i][17],urlist[i][19],urlist[i][21]])
else:
writer.writerow([urlist[i][1],urlist[i][3],urlist[i][5],urlist[i][7],urlist[i][9],urlist[i][11],urlist[i][13]]) #应对流拍、中止情况
except:
passdef main():
urli=[]
url=
‘http://yanjiu.zzhz.com.cn/newPageindex.html?att=2019&attName=2019&slRg=54&brd=&brdName=%25E5%2598%2589%25E5%2585%25B4’
#修改URL地址,获取不同阶段的地价表格
rs=check_link(url)
#print(rs)
get_contents(urli,rs)
save_contents(r
“E:\地产研究资料”,”2019-jx”
,urli)main()
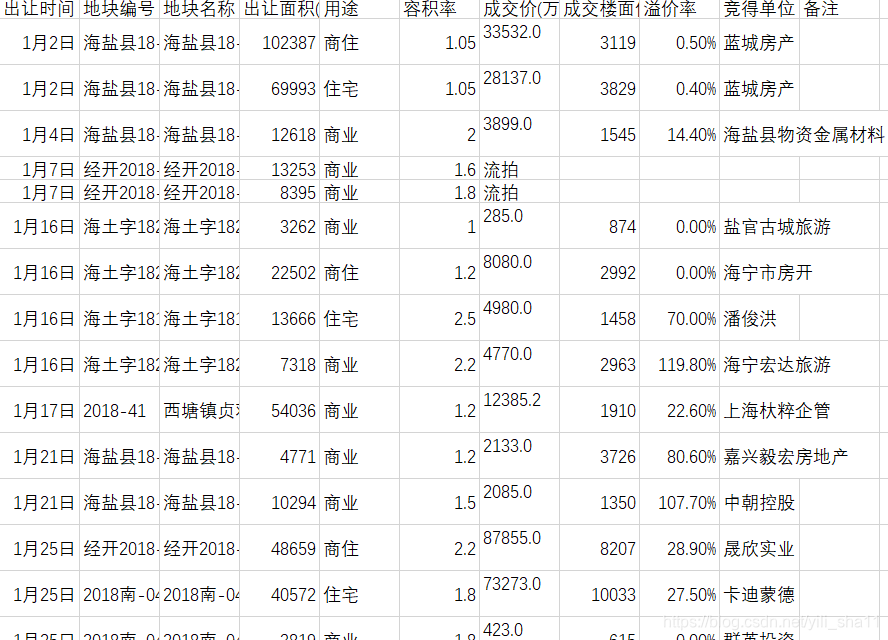
3、数据结果
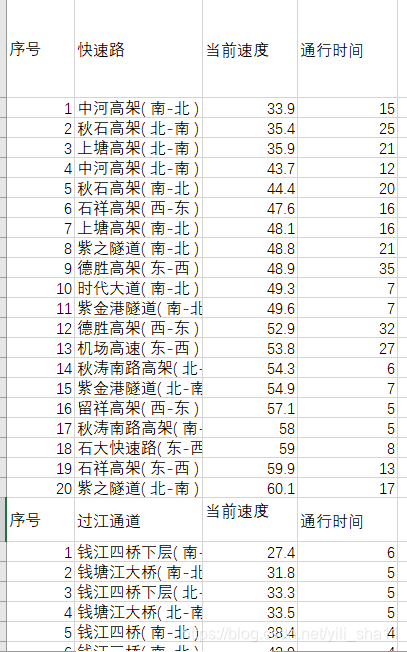
二、交通数据爬取
爬取数据来源:
http://www.hzjtydzs.com/index4.html
1、爬取数据代码
原网页是基于js编写的,因此requests不同提取得到数据。采用selenium进行数据提取,方法是一样的。需要先定位到数据,对数据进行提取,保存。
#抓取杭州市交通拥堵指数页面-分区域交通-主要道路行程车速
#设置保存文件的位置,并按照“时间”对文件进行命名,进行存储。
#
from bs4 import BeautifulSoup
import pandas as pd
import re
import csv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import lxml
import datetime
import time
import os as osurl=’http://www.hzjtydzs.com/index4.html’
browser=webdriver.Chrome() #需安装webdriver,在chrome的开发模式下进行
browser.get(url)#找到页面源码
print(“等待网页相应….”)
wait=WebDriverWait(browser,10)
Xpath=”//*[@id=\”secure_fund_list1\”]” #可借助xpath helper定位到数据
wait.until(EC.presence_of_element_located((By.XPATH,Xpath)))
#presence_of_element_located()方法中传入的应该是一个元组, ec.presence_of_element_located((By.ID, ‘feed_friend’))
#多了一个括号, 把传入参数变为元组类型
print(“正在获取网页数据…”)
soup=BeautifulSoup(browser.page_source,’html.parser’) #页面解析
browser.close() #关闭brower#定位数据
ulist=[]
for tr in soup.find_all(‘tr’):
item=[]
for td in tr.find_all(‘td’):
lst=td.get_text()
item.append(lst)
ulist.append(item)
shuju=[]
for i in range(0,len(ulist),2):
shuju.append(ulist[i])
#print(shuju) #打印数据
#print(len(shuju)) #打印数据长度
#print(shuju[2]) #打印数据第3行(编号从0开始)#保存资源
def save_contents(file_path,file_name,urlist):
if not os.path.exists(file_path):#是否存在文件夹,不存在就创建
os.makedirs(file_path)
path=file_path+os.path.sep+'{file_name}’.format(file_name=file_name+”.csv”)
#path=r”D:\jtzs\{name}”.format(name=file_name+”.csv”)
with open(path,”w”,newline=”) as f: #增加newline=”,删除空格行
writer=csv.writer(f)
writer.writerow([‘jtzs’])
for i in range(len(ulist)):
try:
writer.writerow([urlist[i][0],urlist[i][1],urlist[i][2],urlist[i][3]])
except:
pass
def main():
path=r”D:\jtzs”
filename=datetime.datetime.now().strftime(‘%b-%d-%Y %H%M%S’)
save_contents(path,filename,shuju)main()
2、提取得到数据