分布式文件系统
单机与分布式存储区别
单机存储
存储块:512KB
单个计算机节点
硬件要求高
分布式存储
存储块:64MB
但是一个文件小于数据块的大小,并不占用整个数据块
多个节点构成
硬件要求低
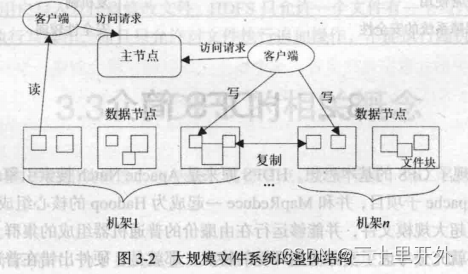
分布式文件系统结构:什么是节点
节点分为两类(后面会详细说明):
1.主节点(名称节点)
负责目录的创建、删除和重命名等,同时管理着数据节点和文件块的映射关系
2.从节点(数据节点)
负责数据的存储和读取,在存储时,由名称节点分配存储位置,再由客户端把数据直接写入相应的数据节点,数据节点也要更具名称节点命令创建,删除数据块,冗余复制。
注意:下图的客户端可以是同一个客户端,分开是为了更好的区分流程
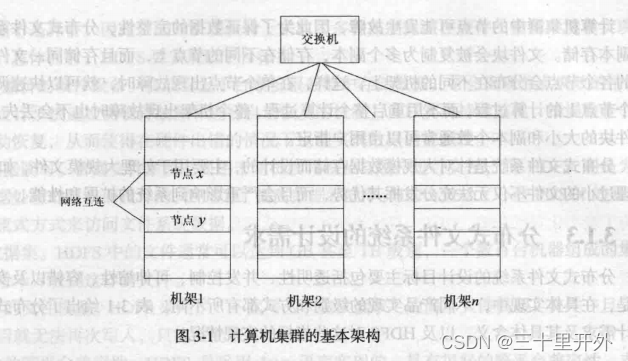
节点
放到机架上,同一机架上的不同节点之间通过网络互连,不同机架之间通过另一级别的网络或交换机互连。

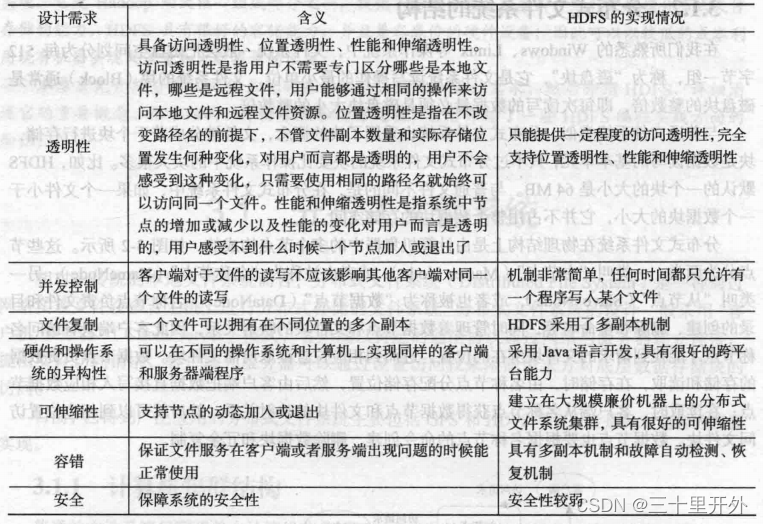
分布式文件系统的设计需求
设计目标:
透明性
,
并发控制性
,
文件复制
,
硬件和操作系统的异构性
,
可伸缩性
,
容错
,
安全
HDFS简介
HDFS和MapReduce一起成为Hadoop的核心组成部分。支持流数据读取和处理超大规模文件,并能够运行在有廉价的普通机器组成的集群上。
HDFS实现目标:
1.兼容廉价的硬件设备
2.流数据读写
3.大数据集
4.简单文件模型
5.强大的跨平台兼容性
6.不适合低延迟数据访问
7.无法高效存储大量小文件
HDFS的相关概念
块
一般的文件系统都是以数据块为单位,这样能提高数据的读写效率
ps
:硬盘在寻道的时候以块寻道肯定比字节寻道块
HDFS一般采用64mb为一个数据块,因为HDFS存储的一般是超大文件
好处:
1.支持大规模文件存储
2.简化系统设计
3.适合数据备份
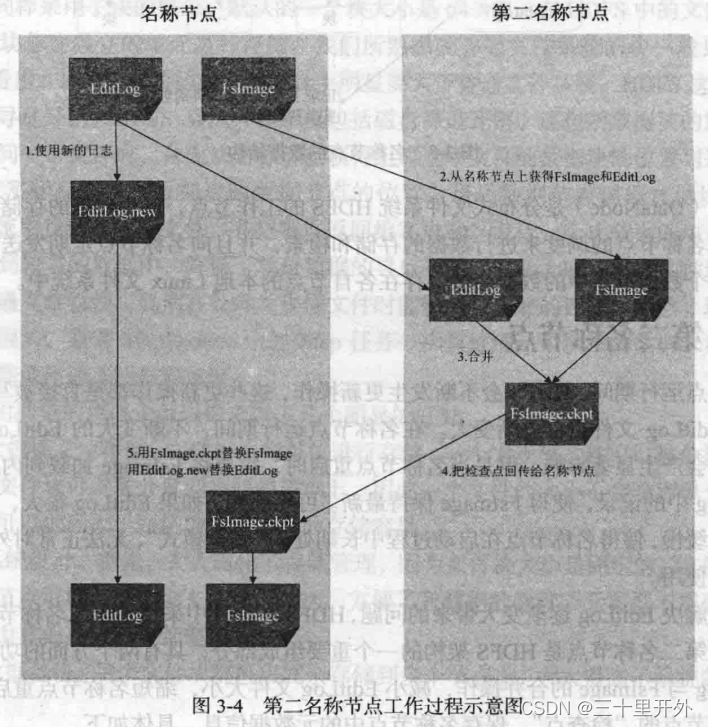
名称节点和数据节点
在HDFS中,
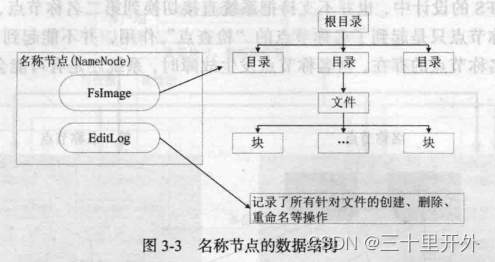
名称节点
(NameNode)负责管理分布式文件系统的
命名空间
(Namespace)。保存了两个核心的数据结构,即
FsImage
和
EditLog
。
FsImage用于维护文件系统树以及文件树所有的文件和文件夹的元数据,操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作。
名称节点记录了每个文件中各个块所在的数据节点的位置信息,但是并
不持久化存储
这些信息,而是在系统每次启动时扫描所有数据节点
重构
得到这些信息。
数据节点
(DataNode)是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
第二名称节点