目录
⭐所属专栏:
人工智能
文中提到的代码如有需要可以私信我发给你?
1、简介
当谈论数据集时,通常是指在机器学习和数据分析中使用的一组数据样本,这些样本通常代表了某个特定问题领域的实际观测数据。数据集可以用于开发、训练和评估机器学习模型,从而使模型能够从数据中学习并做出预测或分类。
数据集通常由以下几个组成部分组成:
-
特征(Features)
:也称为自变量、属性或输入变量,是用来描述每个数据样本的不同方面的数据。特征可以是数值型、类别型、文本型等。在监督学习中,特征被用来训练模型。 -
目标变量(Target Variable)
:也称为因变量、标签或输出变量,是我们希望模型预测或分类的值。在监督学习中,模型使用特征来预测或分类目标变量。 -
样本(Samples)
:每个样本是数据集中的一行,包含特征和目标变量的值。样本代表了问题领域中的一个观测点或数据点。 -
特征名称(Feature Names)
:如果数据集中的特征有名称,通常会提供一个特征名称列表,以便更好地理解和解释特征。 -
目标变量的类别(Target Variable Classes)
:对于分类问题,目标变量可能有多个类别,每个类别表示一个不同的类或标签。 -
数据集描述(Dataset Description)
:通常包括数据集的来源、数据采集方法、特征和目标变量的含义,以及数据的格式和结构等信息。
数据集可以在各种领域和问题中使用,例如医疗诊断、自然语言处理、计算机视觉、金融预测等。不同类型的数据集可能需要不同的预处理和特征工程步骤,以便为模型提供有意义的数据。
在机器学习中,一个常见的任务是将数据集划分为训练集和测试集,用于模型的训练和评估。这样可以确保模型在未见过的数据上能够进行泛化。数据集的质量和适用性对机器学习模型的性能和效果有很大影响,因此选择合适的数据集和进行有效的特征工程非常重要。
2、可用数据集
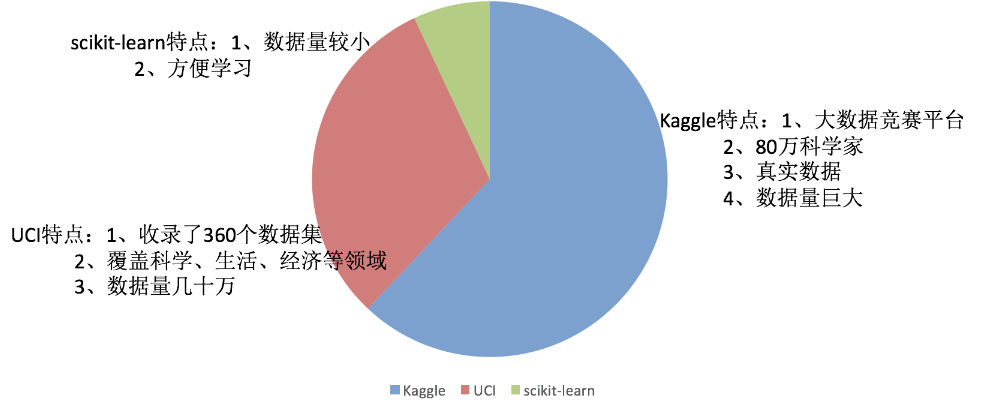
Kaggle网址:
Find Open Datasets and Machine Learning Projects | Kaggle
UCI数据集网址:
UCI Machine Learning Repository
scikit-learn网址:
http://scikit-learn.org/stable/datasets/index.html#datasets
Scikit-learn工具介绍:

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
安装:pip3 install Scikit-learn==0.19.1
(安装scikit-learn需要Numpy, Scipy等库)
Scikit-learn包含的内容:
scikitlearn接口
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3、scikit-learn数据集API
- sklearn.datasets 加载获取流行数据集
- datasets.load_*() 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
3.1、小数据集
sklearn.datasets.load_iris() 加载并返回鸢尾花数据集

sklearn.datasets.load_boston() 加载并返回波士顿房价数据集
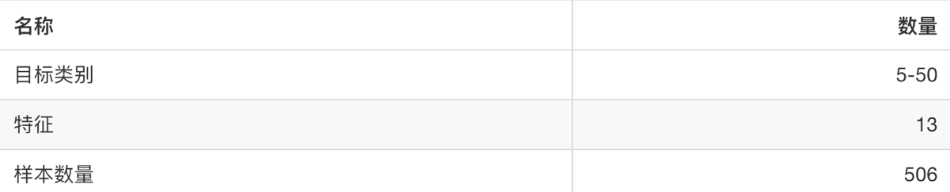
3.2、大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
- subset:’train’或者’test’,’all’,可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4、数据集使用
这里使用的是鸢尾花数据集

数据集返回值介绍:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
from sklearn.datasets import load_iris
'''
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
'''
def getIris_1():
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
if __name__ == '__main__':
getIris_1()数据集划分:
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
数据集划分api:
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.model_selection import train_test_split # 数据集划分
'''
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
'''
def datasets_demo():
"""
对鸢尾花数据集的演示
:return: None
"""
# 1、获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
# 2、对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
return None
if __name__ == '__main__':
datasets_demo()