Kettle有几年没用过了,昨天刚好开发找我,说同步ORACLE几张表的数据到MySQL,ORACLE的数据有可能更新,可以通过时间字段,但是全量同步,当天上生产由于数据量大不一定来得及,需要提前想个方案,问我做还是他来做,说他没有找到什么好办法,那就我来吧。就在这一瞬间,我脑子里浮现出来几个方案:
1. 用python写个程序读取ORACLE,通过ID判断,来增量插入到MySQL
2. 用JAVA写个程序读取ORACLE,通过ID判断,来增量插入到MySQL
3. 通过SPARK批量读取ORACLE,通过ID判断,来增量插入到MySQL
4. 通过ORACLE spool到文件,然后在MySQL load inpath
5. 通过kettle增量插入并更新
以上1-4都是增量插入,那么更新的数据怎么来处理,我想了一个办法,通过盗用ogg抓取ORACLE日志存放到KAFKA,写一个spark streaming实时更新这些数据到MySQL。
第一个想法通常会第一个实现,因此我打开Pycharm,安装oracle, MySQL的module, 一直提示gcc++错误,装不了,于是百度,浪费了我半个小时也没搞定,于是放弃了,反正我方案多的是。思来想去,还是用kettle吧,ETL工具不用太麻烦。
我习惯性的把问题肢解成2个步骤:
1. 增量插入
2. 处理更新的数据
增量插入的思路很简单,假设同步test到test1
转换1(获取最大的ID):select max(id) as endid from test —>设置变量
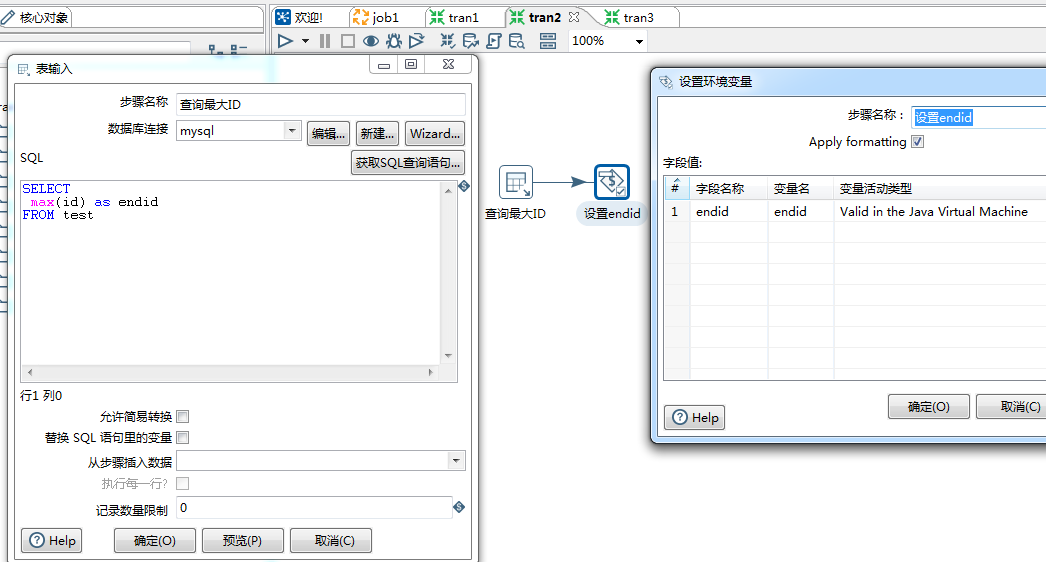
转换2(获取最小的ID): select max(id) as startid from test1 —->设置变量
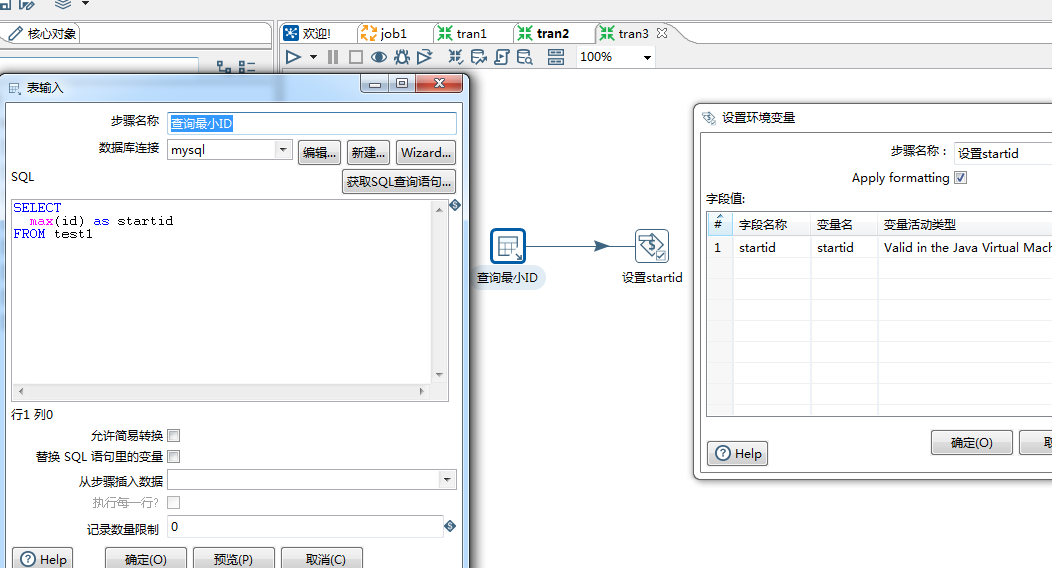
转换3: 获取变量—>table input —> table output
input的SQL:select * from test where id > ${startid} and id <= ${endid} ;
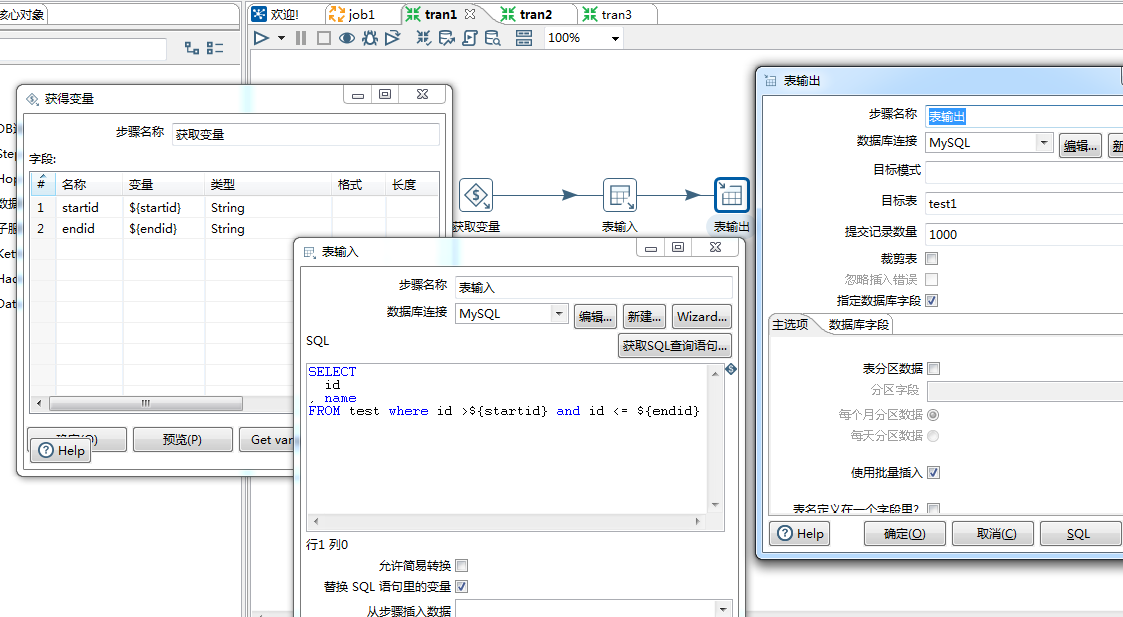
就是这么简单3步解决。整个JOB的连接顺序如下:
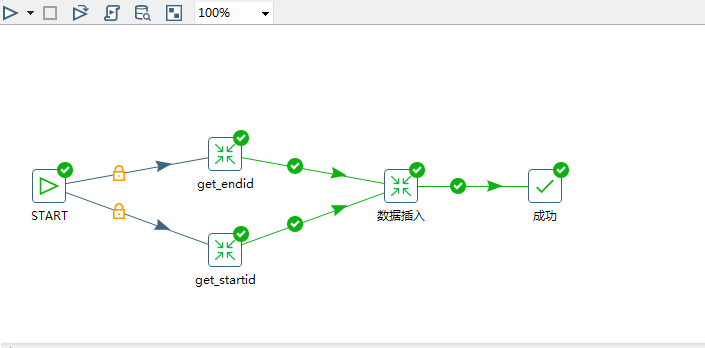
好了,以上搞定了增量同步插入,现在来处理更新的数据。
更新的数据处理实际是比较麻烦的,通过kettle来做的话,需要这么来处理。 从test表查询数据,从test1查询数据,然后进行比较,数据量大的话,这个比较实际上会很慢的。
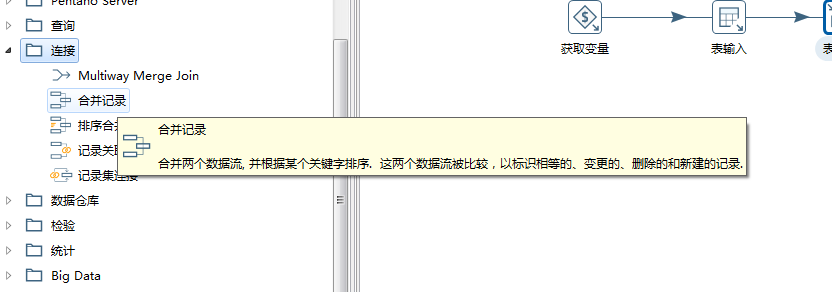
看上面的合并记录的定义,比较2个数据流,然后我们可以通过时间戳的对比,如果发现不同,表示这个数据需要更新。通常不用考虑delete的问题,因为现在大部分不会直接删除数据,基本是通过设置行的状态,来表示数据可用还是不可用,实际也就只需要考虑update.
既然上面的效率不好,那么考虑使用我们5种方案来处理update的数据。
逻辑简单:ogg监控ORACLE日志,抓取相关表的日志到kafka,然后通过spark streaming或者storm处理数据,发现变更的字段直接拼接SQL,在mysql里面更新即可,做到实时。