本文转载自知乎
https://zhuanlan.zhihu.com/p/68531147?utm_source=qq
,侵删
本文是对 DeepLab 系列的概括,主要讨论模型的设计和改进,附 Pytorch 实现代码,略去训练细节以及性能细节,这些都可以在原论文中找到。
原论文地址:
DeepLabv1
https://arxiv.org/pdf/1412.7062v3.pdf
DeepLabv2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
DeepLabv3
Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLabv3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
DeepLabv1
DeepLabv1 模型结构很容易理解:
- 首先它是个 VGG-16
- 然后为了使图像语义分割更准确,5 个 max-pooling 层 skip 了后两个(具体实现上,看G站上的代码,似乎没有去除,而是保留了后两个 max-pooling ,只是将 stride = 2 改为 stride = 1,kernal = 3),最后卷积层的输出整体 stride 从 32x 下降至 8x。
-
参考
Uno Whoiam:空洞卷积(Dilated Convolution):有之以为利,无之以为用
,由于后两个 max-pooling 影响了其后的卷积层,使其视野分别下降了 2x 和 4x,为了保持其原来的视野,便将其改成空洞卷积,dilation 分别为 2 和 4,理念与DRN一致:

4. 当然,它也是一个全卷积网络
Uno Whoiam:FCN:从图片分类到像素分类
,即将全连接层替换成
![[公式]](https://img-blog.csdnimg.cn/img_convert/aaa0f162b58058cec2a8c51ff81640d8.png)
的卷积层,输出和原图大小一致的特征图,对每个像素分类。
5. 使用双线性插值上采样 8x 得到和原图大小一致的像素分类图。
6. 使用 CRF(条件随机场)使最后分类结果的边缘更加精细:

啥是 CRF 呢?这里只给论文里的公式,不深究,v3 以及之后就没用这玩意了:
其中
为 DCNN 输出的置信度;
,p 表示像素的位置,I 表示像素的 RGB 数值;如何理解这玩意呢?简单来说就是在对一个像素做分类时,不光考虑 DCNN 输出的结果,还要考虑周围像素的意见尤其像素值比较接近的,这样得出的语义分割结果会有更好的边缘。
7. 多尺寸预测,希望获得更好的边界信息,与FCN skip layer类似,具体实现上,在输入图片与前四个 max pooling 后添加
和
的卷积层,这四个预测结果与最终模型输出拼接(concatenate)到一起,相当于多了128*5=640个channel。虽然效果不如dense CRF,但也有一定提高。最终模型是结合了Desne CRF与Multi-scale Prediction。
一个简单的 Pytorch 实现如下,使用 ResNet,第一层为
普通卷积,stride = 2,紧跟着 stride = 2 的 max-pooling,尔后一个普通的 bottleneck ,一个 stride = 2 的 bottleneck,然后 dilation =2、dilation =4 的bottleneck。
from __future__ import absolute_import, print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
class DeepLabV1(nn.Sequential):
"""
DeepLab v1: Dilated ResNet + 1x1 Conv
Note that this is just a container for loading the pretrained COCO model and not mentioned as "v1" in papers.
"""
def __init__(self, n_classes, n_blocks):
super(DeepLabV1, self).__init__()
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], 1, 1))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], 2, 1))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], 1, 2))
self.add_module("layer5", _ResLayer(n_blocks[3], ch[4], ch[5], 1, 4))
self.add_module("fc", nn.Conv2d(2048, n_classes, 1))
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
class _Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
if __name__ == "__main__":
model = DeepLabV1(n_classes=21, n_blocks=[3, 4, 23, 3])
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
DeepLabv2
DeepLabv2 相对于 v1 最大的改动是增加了受
SPP(Spacial Pyramid Pooling)
启发得来的 ASPP(Atrous Spacial Pyramid Pooling),在模型最后进行像素分类之前增加一个类似 Inception 的结构,包含不同 rate(空洞间隔) 的 Atrous Conv(空洞卷积),增强模型识别不同尺寸的同一物体的能力:


DeepLabv2 Pytorch 实现:
from __future__ import absolute_import, print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling (ASPP)
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
for i, rate in enumerate(rates):
self.add_module(
"c{}".format(i),
nn.Conv2d(in_ch, out_ch, 3, 1, padding=rate, dilation=rate, bias=True),
)
for m in self.children():
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
return sum([stage(x) for stage in self.children()])
class DeepLabV2(nn.Sequential):
"""
DeepLab v2: Dilated ResNet + ASPP
Output stride is fixed at 8
"""
def __init__(self, n_classes, n_blocks, atrous_rates):
super(DeepLabV2, self).__init__()
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], 1, 1))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], 2, 1))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], 1, 2))
self.add_module("layer5", _ResLayer(n_blocks[3], ch[4], ch[5], 1, 4))
self.add_module("aspp", _ASPP(ch[5], n_classes, atrous_rates))
def freeze_bn(self):
for m in self.modules():
if isinstance(m, _ConvBnReLU.BATCH_NORM):
m.eval()
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
if __name__ == "__main__":
model = DeepLabV2(
n_classes=21, n_blocks=[3, 4, 23, 3], atrous_rates=[6, 12, 18, 24]
)
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)另外,DeepLabv2 采用了 Poly 的训练策略:
当
时,模型效果要比普通的分段学习率策略要高
,Pytorch 实现如下:
https://github.com/kazuto1011/deeplab-pytorch/blob/master/libs/utils/lr_scheduler.py
from torch.optim.lr_scheduler import _LRScheduler
class PolynomialLR(_LRScheduler):
def __init__(self, optimizer, step_size, iter_max, power, last_epoch=-1):
self.step_size = step_size
self.iter_max = iter_max
self.power = power
super(PolynomialLR, self).__init__(optimizer, last_epoch)
def polynomial_decay(self, lr):
return lr * (1 - float(self.last_epoch) / self.iter_max) ** self.power
def get_lr(self):
if (
(self.last_epoch == 0)
or (self.last_epoch % self.step_size != 0)
or (self.last_epoch > self.iter_max)
):
return [group["lr"] for group in self.optimizer.param_groups]
return [self.polynomial_decay(lr) for lr in self.base_lrs]
DeepLabv3
DeepLabv3 的主要变化如下:
- 使用了Multi-Grid 策略,即在模型后端多加几层不同 rate 的空洞卷积:

2. 将 batch normalization 加入到 ASPP模块.
3. 具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息。不过,论文发现,随着sampling rate的增加,有效filter特征权重(即有效特征区域,而不是补零区域的权重)的数量会变小,极端情况下,当空洞卷积的 rate 和 feature map 的大小一致时,
卷积会退化成
:
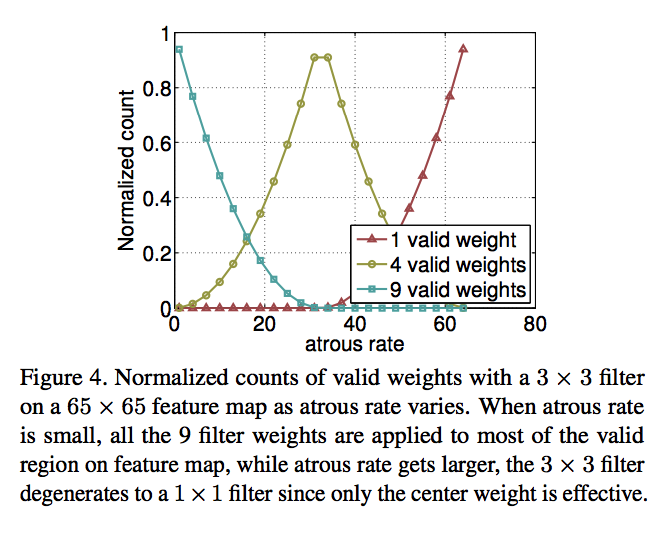
为了保留较大视野的空洞卷积的同时解决这个问题,DeepLabv3 的 ASPP 加入了 全局池化层+conv1x1+双线性插值上采样 的模块:

DeepLabv3 的Pytorch 实现如下:
from __future__ import absolute_import, print_function
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
class _ImagePool(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.conv = _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1)
def forward(self, x):
_, _, H, W = x.shape
h = self.pool(x)
h = self.conv(h)
h = F.interpolate(h, size=(H, W), mode="bilinear", align_corners=False)
return h
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling with image-level feature
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
self.stages = nn.Module()
self.stages.add_module("c0", _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1))
for i, rate in enumerate(rates):
self.stages.add_module(
"c{}".format(i + 1),
_ConvBnReLU(in_ch, out_ch, 3, 1, padding=rate, dilation=rate),
)
self.stages.add_module("imagepool", _ImagePool(in_ch, out_ch))
def forward(self, x):
return torch.cat([stage(x) for stage in self.stages.children()], dim=1)
class DeepLabV3(nn.Sequential):
"""
DeepLab v3: Dilated ResNet with multi-grid + improved ASPP
"""
def __init__(self, n_classes, n_blocks, atrous_rates, multi_grids, output_stride):
super(DeepLabV3, self).__init__()
# Stride and dilation
if output_stride == 8:
s = [1, 2, 1, 1]
d = [1, 1, 2, 4]
elif output_stride == 16:
s = [1, 2, 2, 1]
d = [1, 1, 1, 2]
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], s[0], d[0]))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], s[1], d[1]))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], s[2], d[2]))
self.add_module(
"layer5", _ResLayer(n_blocks[3], ch[4], ch[5], s[3], d[3], multi_grids)
)
self.add_module("aspp", _ASPP(ch[5], 256, atrous_rates))
concat_ch = 256 * (len(atrous_rates) + 2)
self.add_module("fc1", _ConvBnReLU(concat_ch, 256, 1, 1, 0, 1))
self.add_module("fc2", nn.Conv2d(256, n_classes, kernel_size=1))
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
if __name__ == "__main__":
model = DeepLabV3(
n_classes=21,
n_blocks=[3, 4, 23, 3],
atrous_rates=[6, 12, 18],
multi_grids=[1, 2, 4],
output_stride=8,
)
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
DeepLabv3+
V3+ 最大的改进是将 DeepLab 的 DCNN 部分看做 Encoder,将 DCNN 输出的特征图上采样成原图大小的部分看做 Decoder ,构成 Encoder+Decoder 体系,双线性插值上采样便是一个简单的 Decoder,而强化 Decoder 便可使模型整体在图像语义分割边缘部分取得良好的结果。

具体来说,DeepLabV3+ 在 stride = 16 的DeepLabv3 模型输出上采样 4x 后,将 DCNN 中 0.25x 的输出使用
的卷积降维后与之连接(concat)再使用
卷积处理后双线性插值上采样 4 倍后得到相对于 DeepLabv3 更精细的结果。

DeepLabv3+的其他改进还有:
-
借鉴MobileNet,使用 Depth-wise 空洞卷积+
卷积:

2. 使用修改过的 Xception:

使用 Pytorch 的DeepLabv3+ 实现如下:
from __future__ import absolute_import, print_function
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling with image-level feature
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
self.stages = nn.Module()
self.stages.add_module("c0", _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1))
for i, rate in enumerate(rates):
self.stages.add_module(
"c{}".format(i + 1),
_ConvBnReLU(in_ch, out_ch, 3, 1, padding=rate, dilation=rate),
)
self.stages.add_module("imagepool", _ImagePool(in_ch, out_ch))
def forward(self, x):
return torch.cat([stage(x) for stage in self.stages.children()], dim=1)
class DeepLabV3Plus(nn.Module):
"""
DeepLab v3+: Dilated ResNet with multi-grid + improved ASPP + decoder
"""
def __init__(self, n_classes, n_blocks, atrous_rates, multi_grids, output_stride):
super(DeepLabV3Plus, self).__init__()
# Stride and dilation
if output_stride == 8:
s = [1, 2, 1, 1]
d = [1, 1, 2, 4]
elif output_stride == 16:
s = [1, 2, 2, 1]
d = [1, 1, 1, 2]
# Encoder
ch = [64 * 2 ** p for p in range(6)]
self.layer1 = _Stem(ch[0])
self.layer2 = _ResLayer(n_blocks[0], ch[0], ch[2], s[0], d[0])
self.layer3 = _ResLayer(n_blocks[1], ch[2], ch[3], s[1], d[1])
self.layer4 = _ResLayer(n_blocks[2], ch[3], ch[4], s[2], d[2])
self.layer5 = _ResLayer(n_blocks[3], ch[4], ch[5], s[3], d[3], multi_grids)
self.aspp = _ASPP(ch[5], 256, atrous_rates)
concat_ch = 256 * (len(atrous_rates) + 2)
self.add_module("fc1", _ConvBnReLU(concat_ch, 256, 1, 1, 0, 1))
# Decoder
self.reduce = _ConvBnReLU(256, 48, 1, 1, 0, 1)
self.fc2 = nn.Sequential(
OrderedDict(
[
("conv1", _ConvBnReLU(304, 256, 3, 1, 1, 1)),
("conv2", _ConvBnReLU(256, 256, 3, 1, 1, 1)),
("conv3", nn.Conv2d(256, n_classes, kernel_size=1)),
]
)
)
def forward(self, x):
h = self.layer1(x)
h = self.layer2(h)
h_ = self.reduce(h)
h = self.layer3(h)
h = self.layer4(h)
h = self.layer5(h)
h = self.aspp(h)
h = self.fc1(h)
h = F.interpolate(h, size=h_.shape[2:], mode="bilinear", align_corners=False)
h = torch.cat((h, h_), dim=1)
h = self.fc2(h)
h = F.interpolate(h, size=x.shape[2:], mode="bilinear", align_corners=False)
return h
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
if __name__ == "__main__":
model = DeepLabV3Plus(
n_classes=21,
n_blocks=[3, 4, 23, 3],
atrous_rates=[6, 12, 18],
multi_grids=[1, 2, 4],
output_stride=16,
)
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)参考链接:
https://blog.csdn.net/junparadox/article/details/52610744
清欢守护者:精读深度学习论文(20) DeepLab V1
https://blog.csdn.net/u011974639/article/details/79518175
语义分割论文-DeepLab系列
语义分割中 CRF 的运用
https://blog.csdn.net/studyeboy/article/details/88121657